Research and Documentation Centre (WODC), Ministry of Justice and Security, The Hague, Zuid-Holland, the Netherlands.
Department of Social Sciences, Utrecht University, Utrecht, Utrecht, the Netherlands.
PLoS One. 2019 Mar 8;14(3):e0213245. doi: 10.1371/journal.pone.0213245. eCollection 2019.
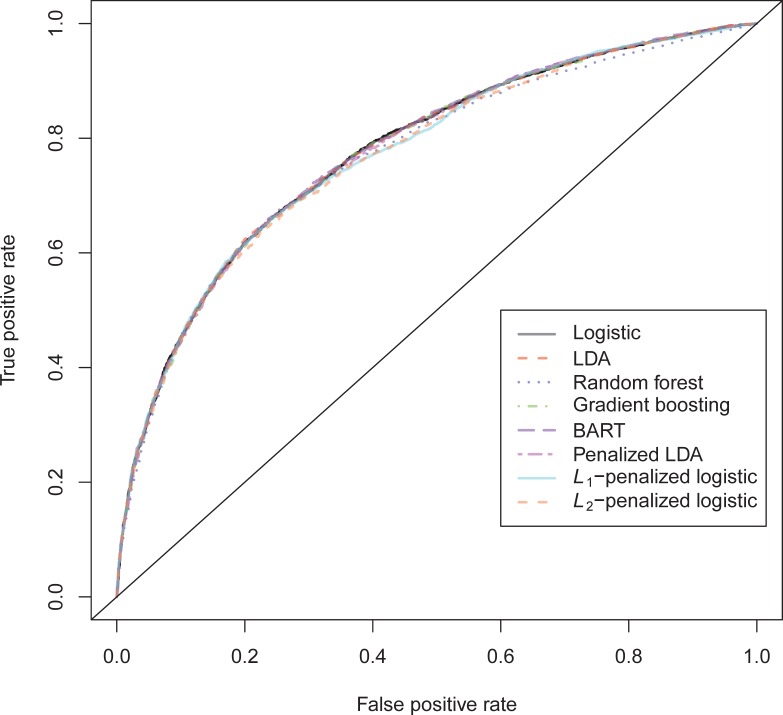
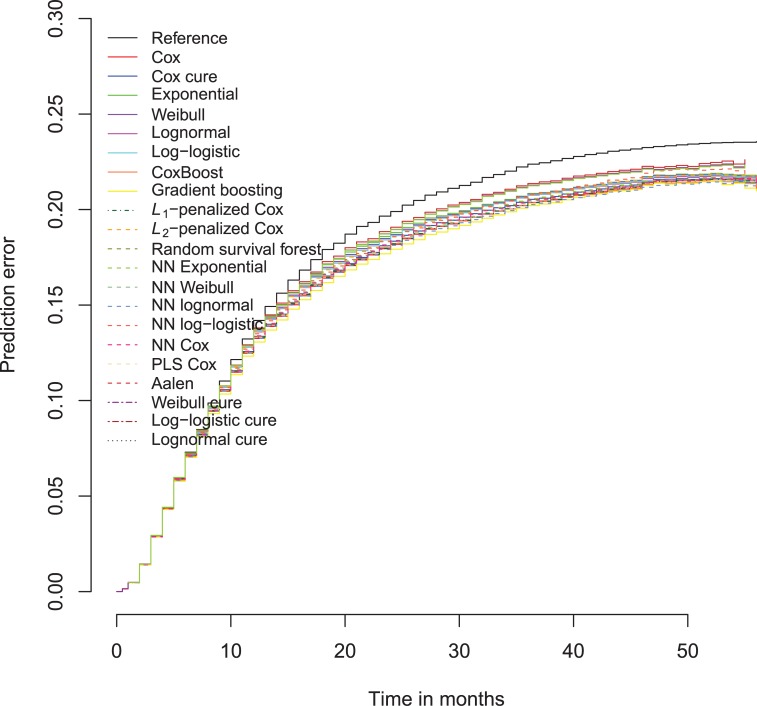
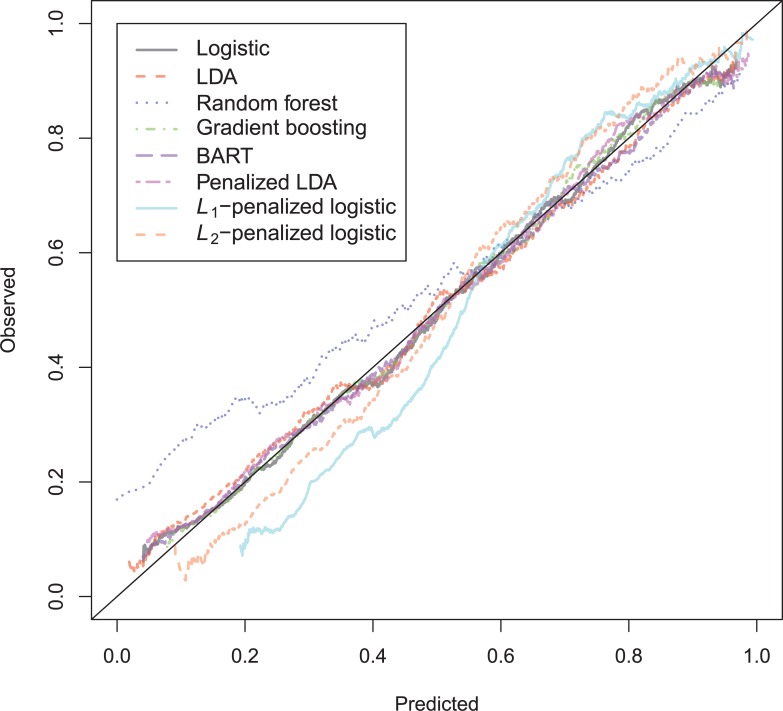
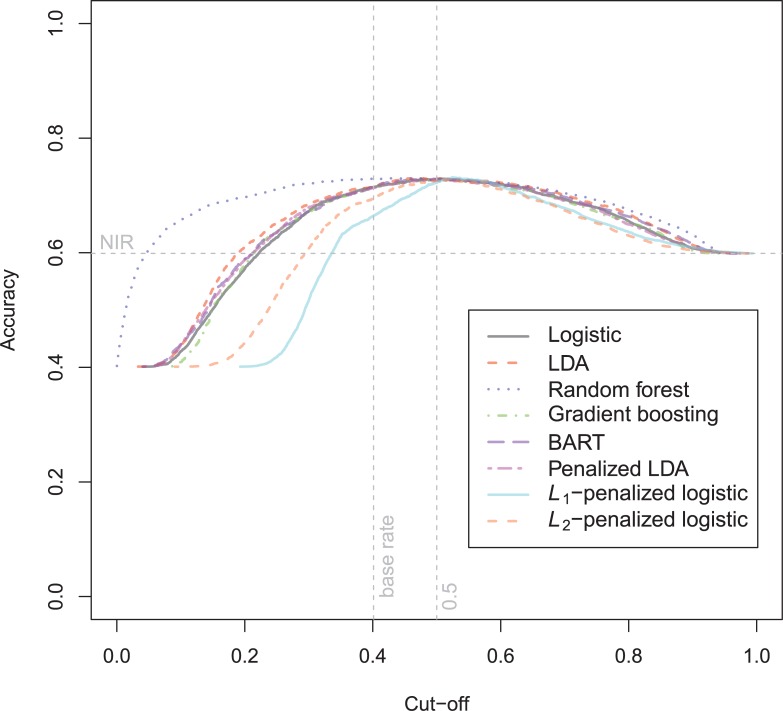
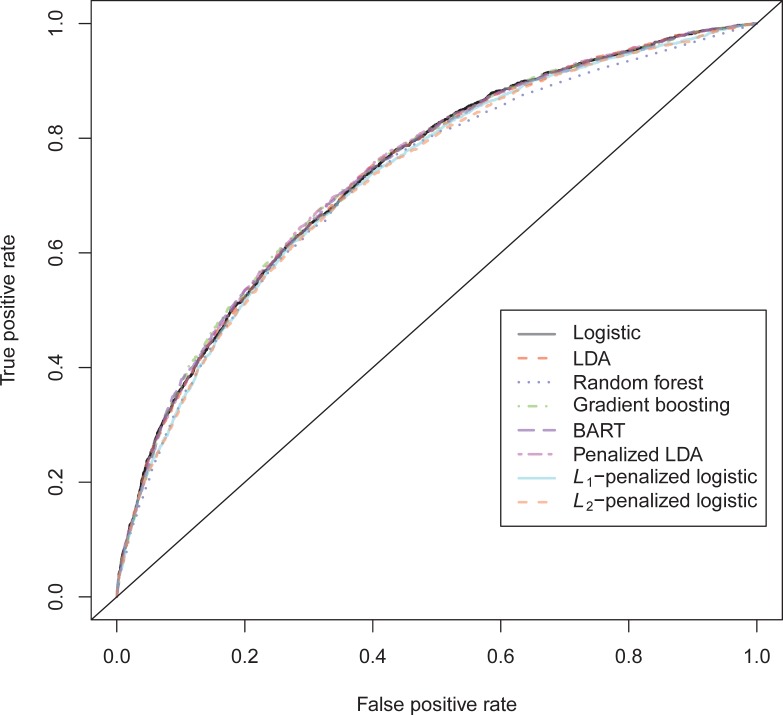
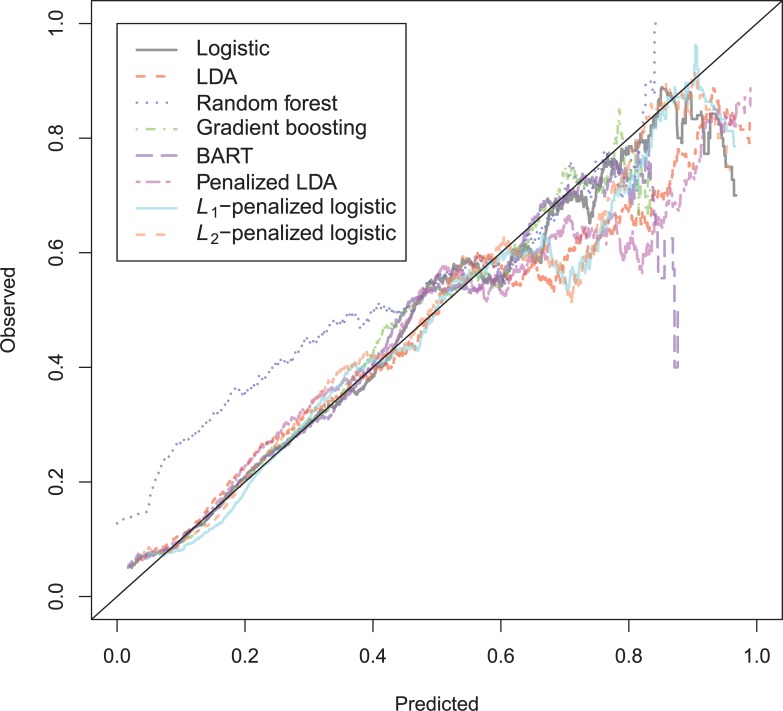
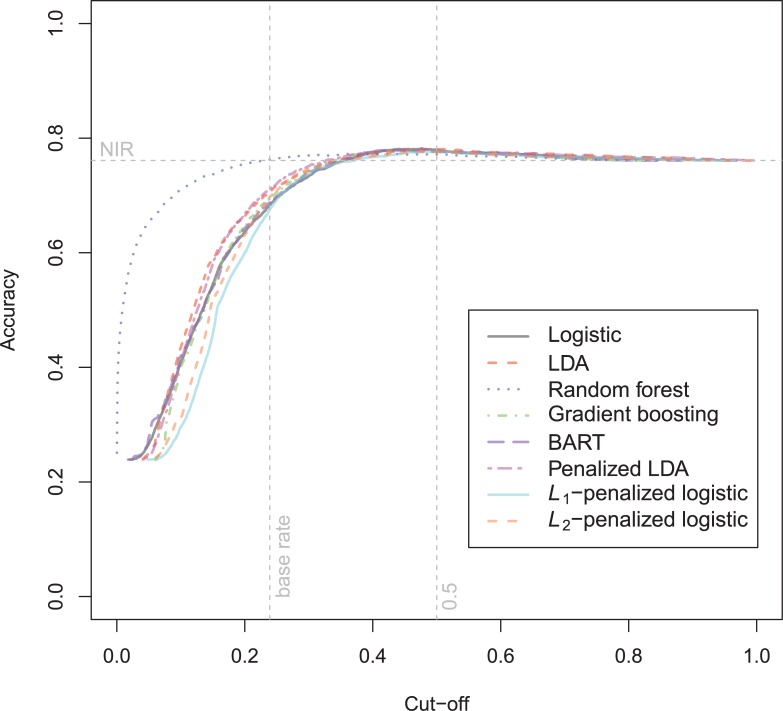
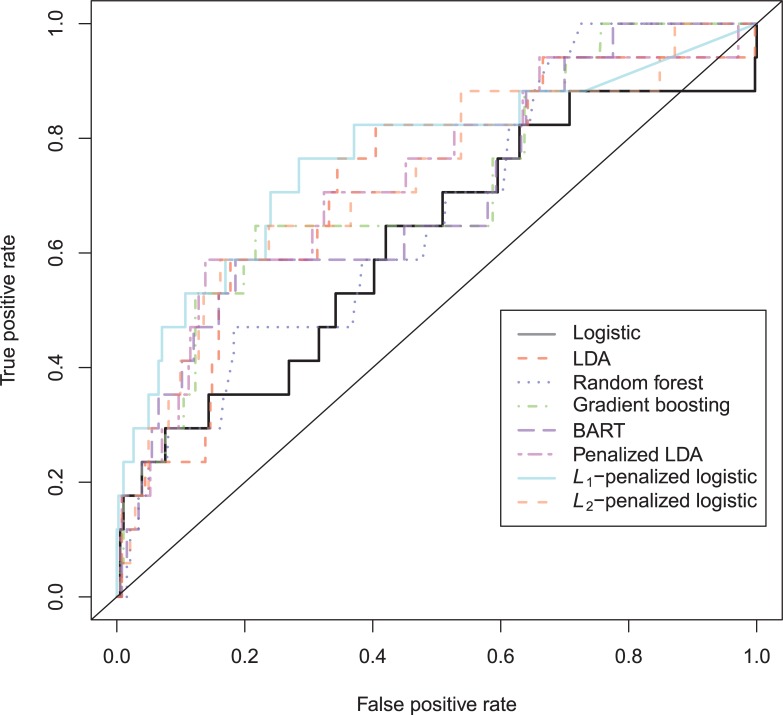
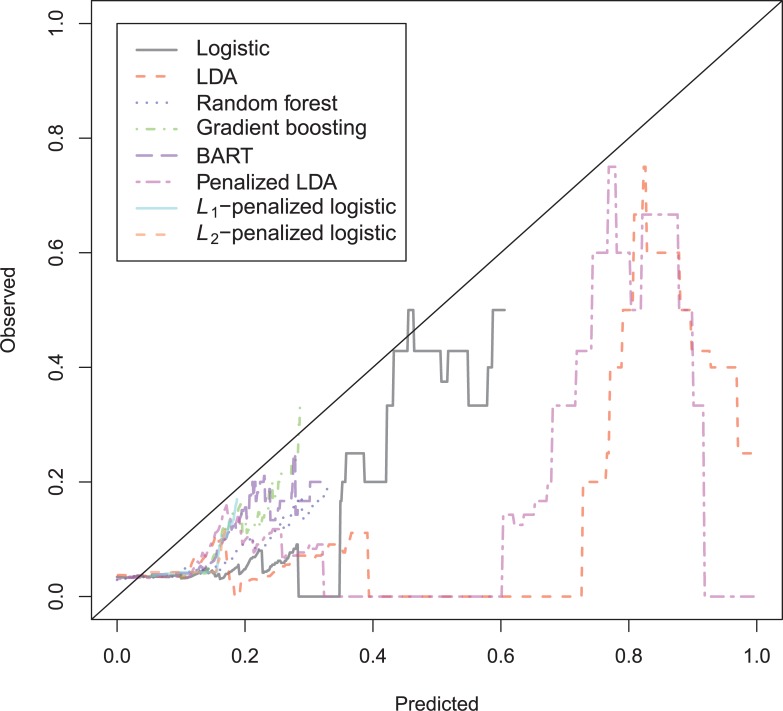
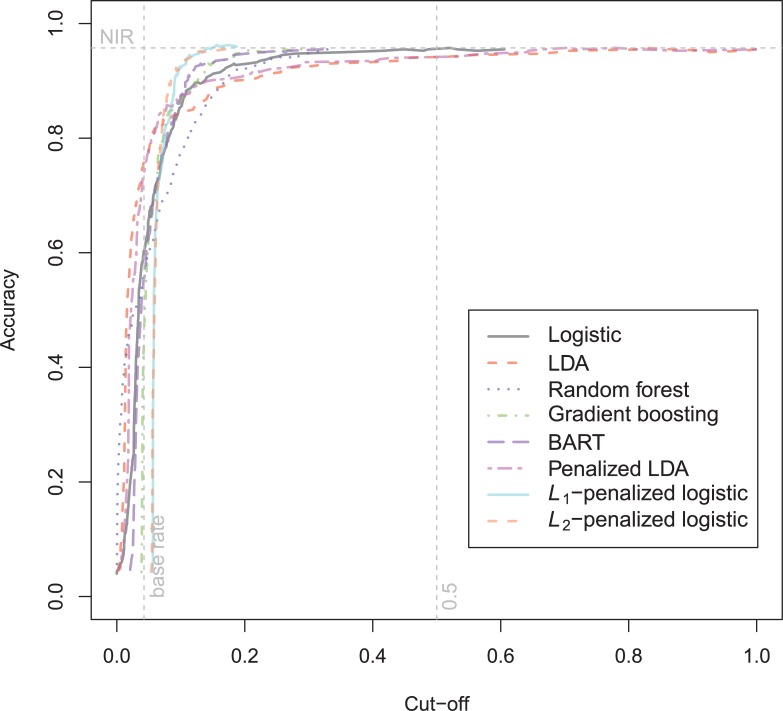
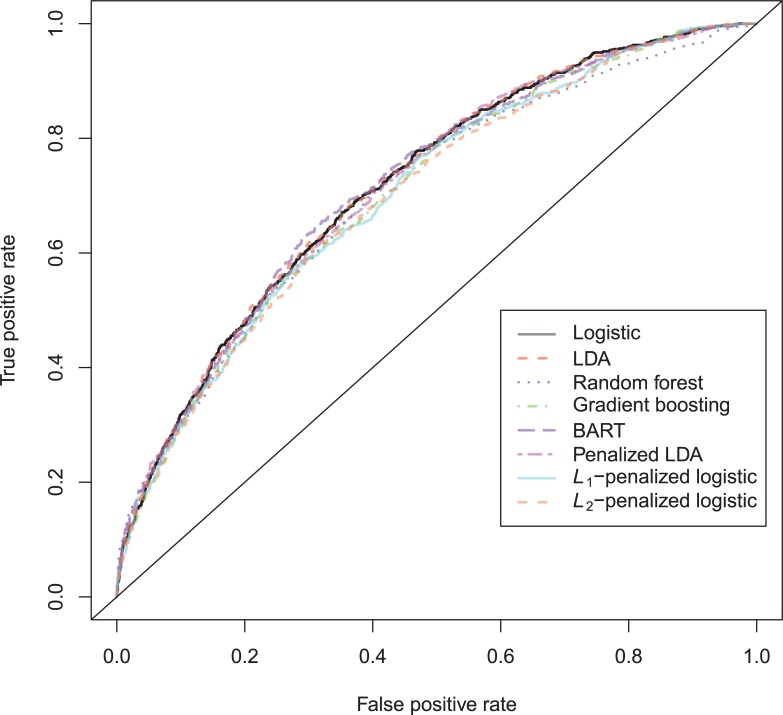
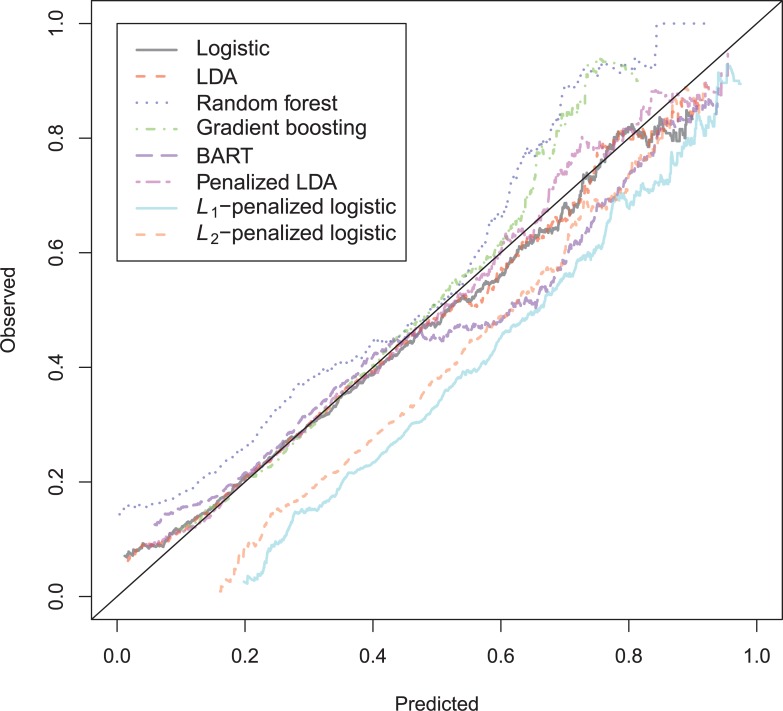
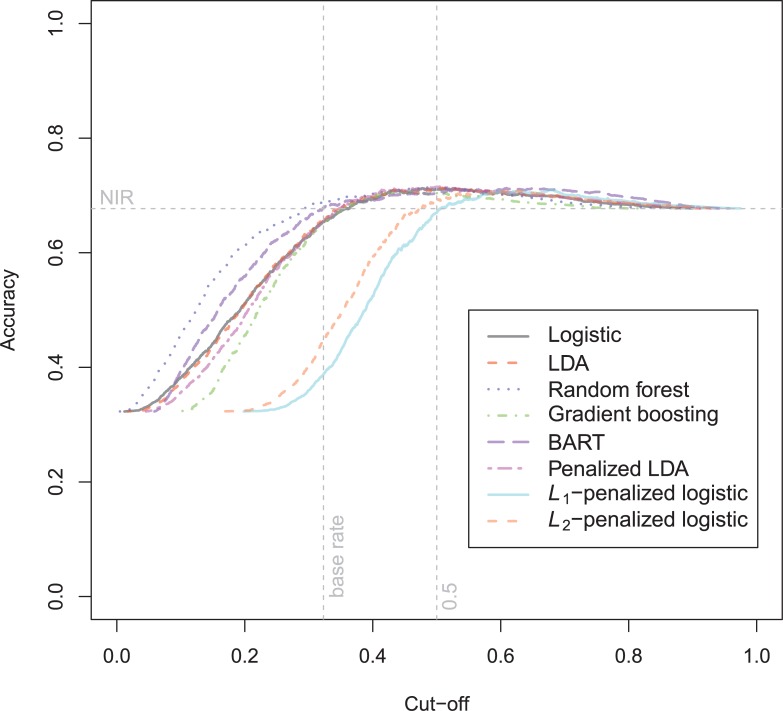
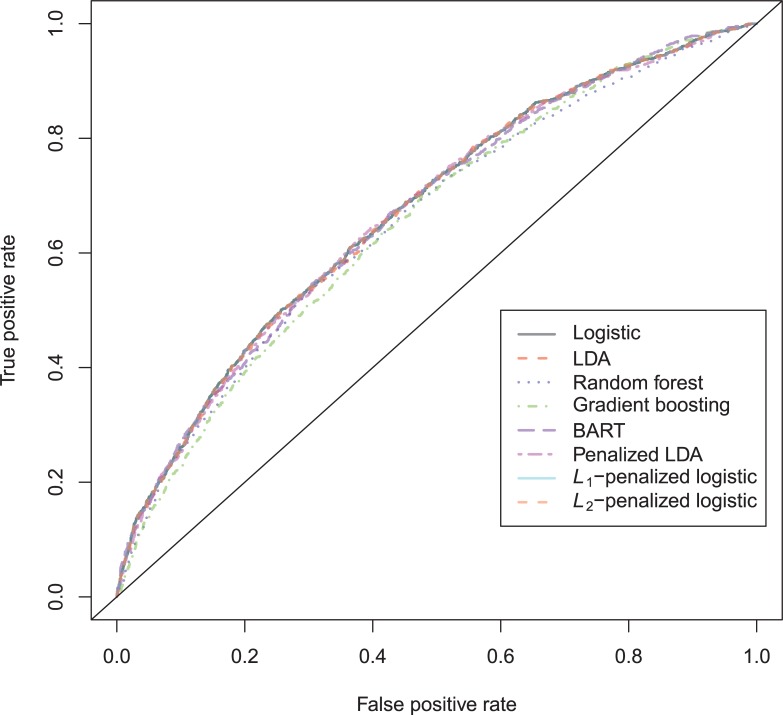
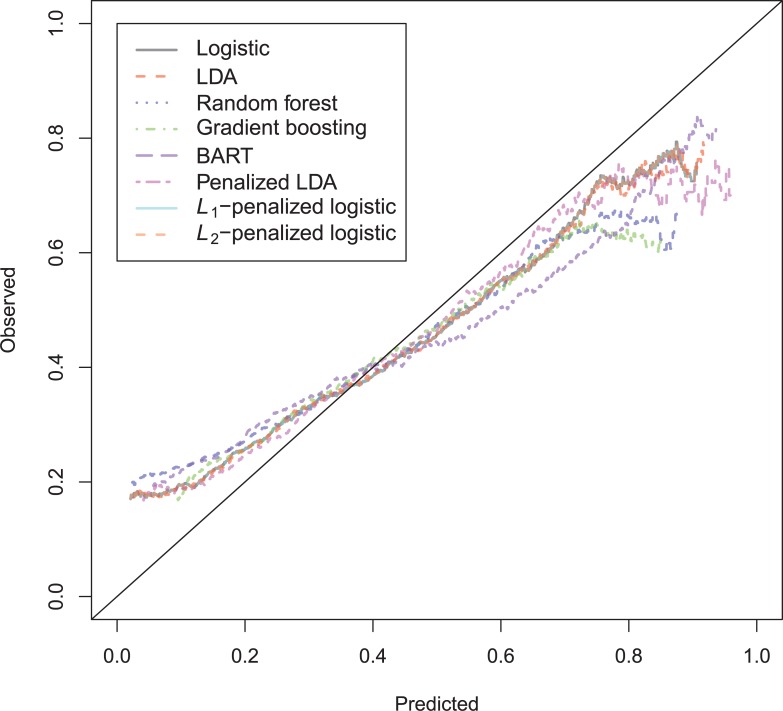
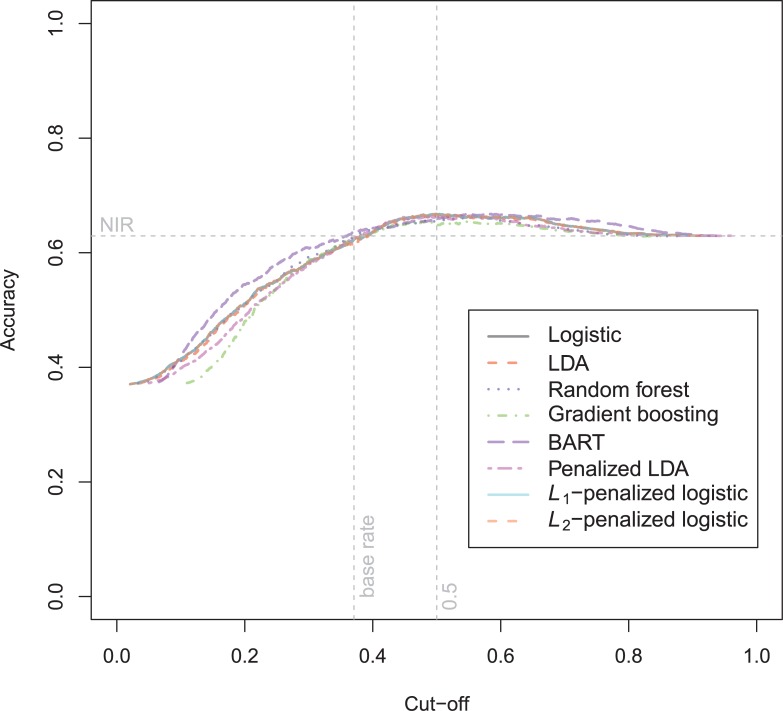
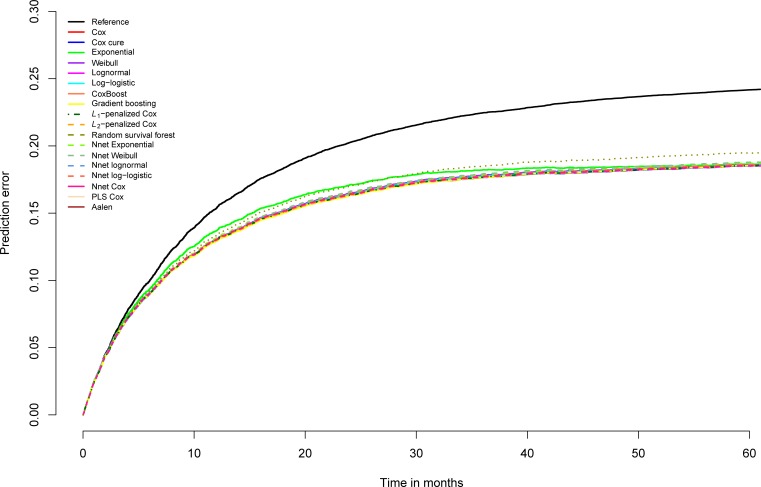
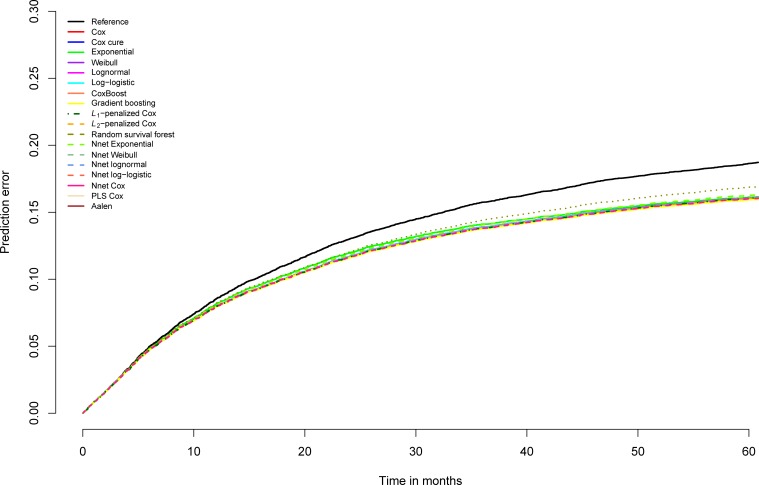
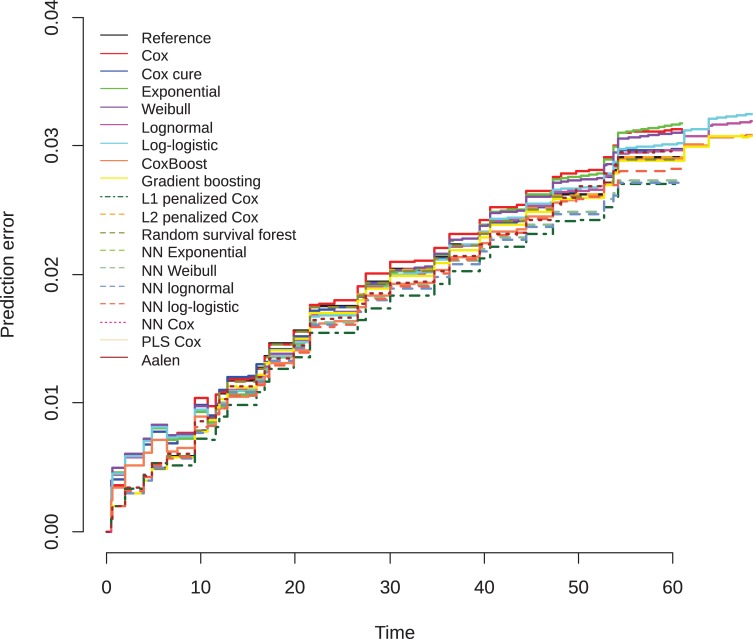
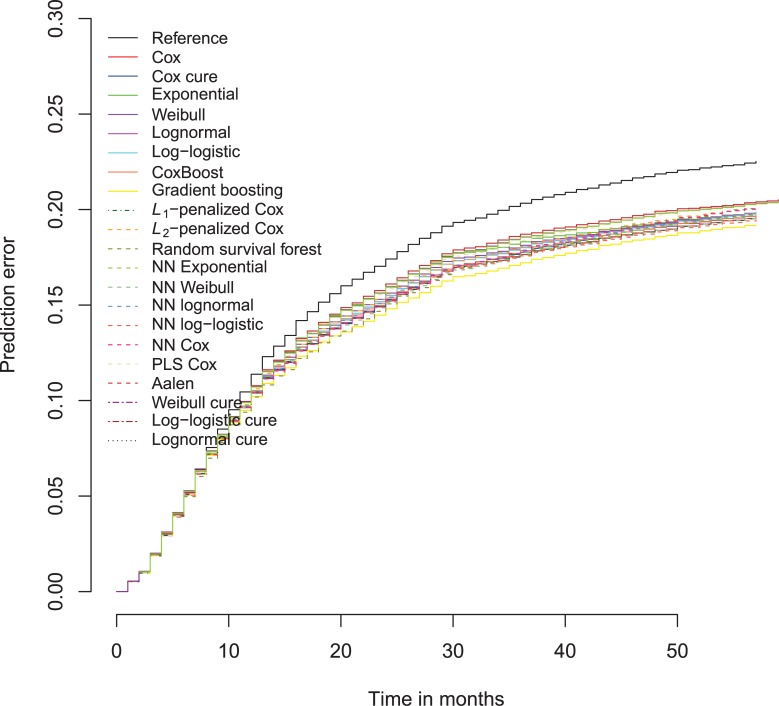
In a recidivism prediction context, there is no consensus on which modeling strategy should be followed for obtaining an optimal prediction model. In previous papers, a range of statistical and machine learning techniques were benchmarked on recidivism data with a binary outcome. However, two important tree ensemble methods, namely gradient boosting and random forests were not extensively evaluated. In this paper, we further explore the modeling potential of these techniques in the binary outcome criminal prediction context. Additionally, we explore the predictive potential of classical statistical and machine learning methods for censored time-to-event data. A range of statistical manually specified statistical and (semi-)automatic machine learning models is fitted on Dutch recidivism data, both for the binary outcome case and censored outcome case. To enhance generalizability of results, the same models are applied to two historical American data sets, the North Carolina prison data. For all datasets, (semi-) automatic modeling in the binary case seems to provide no improvement over an appropriately manually specified traditional statistical model. There is however evidence of slightly improved performance of gradient boosting in survival data. Results on the reconviction data from two sources suggest that both statistical and machine learning should be tried out for obtaining an optimal model. Even if a flexible black-box model does not improve upon the predictions of a manually specified model, it can serve as a test whether important interactions are missing or other misspecification of the model are present and can thus provide more security in the modeling process.
在累犯预测的背景下,对于应该采用哪种建模策略来获得最优的预测模型,尚未达成共识。在之前的论文中,已经对基于二分类结局的累犯数据使用了一系列统计学和机器学习技术进行了基准测试。然而,两种重要的树集成方法,即梯度提升和随机森林,尚未得到广泛评估。在本文中,我们进一步探索了这些技术在二分类结局的犯罪预测背景下的建模潜力。此外,我们还探索了经典统计学和机器学习方法在删失时间事件数据中的预测潜力。在荷兰累犯数据中,针对二分类结局和删失结局情况,拟合了一系列统计学上手动指定的统计模型和(半)自动机器学习模型。为了提高结果的可推广性,我们将相同的模型应用于两个历史上的美国数据集,即北卡罗来纳州监狱数据。对于所有数据集,(半)自动建模在二分类情况下似乎并没有优于适当手动指定的传统统计模型。然而,在生存数据中,梯度提升的性能略有提高。来自两个来源的再犯数据的结果表明,应该尝试使用统计学和机器学习来获得最优模型。即使灵活的黑盒模型不能提高手动指定模型的预测效果,它也可以作为检验是否缺少重要交互作用或模型存在其他误设定的一种手段,从而为建模过程提供更多的保障。