Institute of Cognitive Neuroscience, University College London, Alexandra House, 17 Queen Square, WC1N 3AZ London, UK.
Curr Biol. 2019 Mar 18;29(6):979-990.e4. doi: 10.1016/j.cub.2019.01.077. Epub 2019 Mar 7.
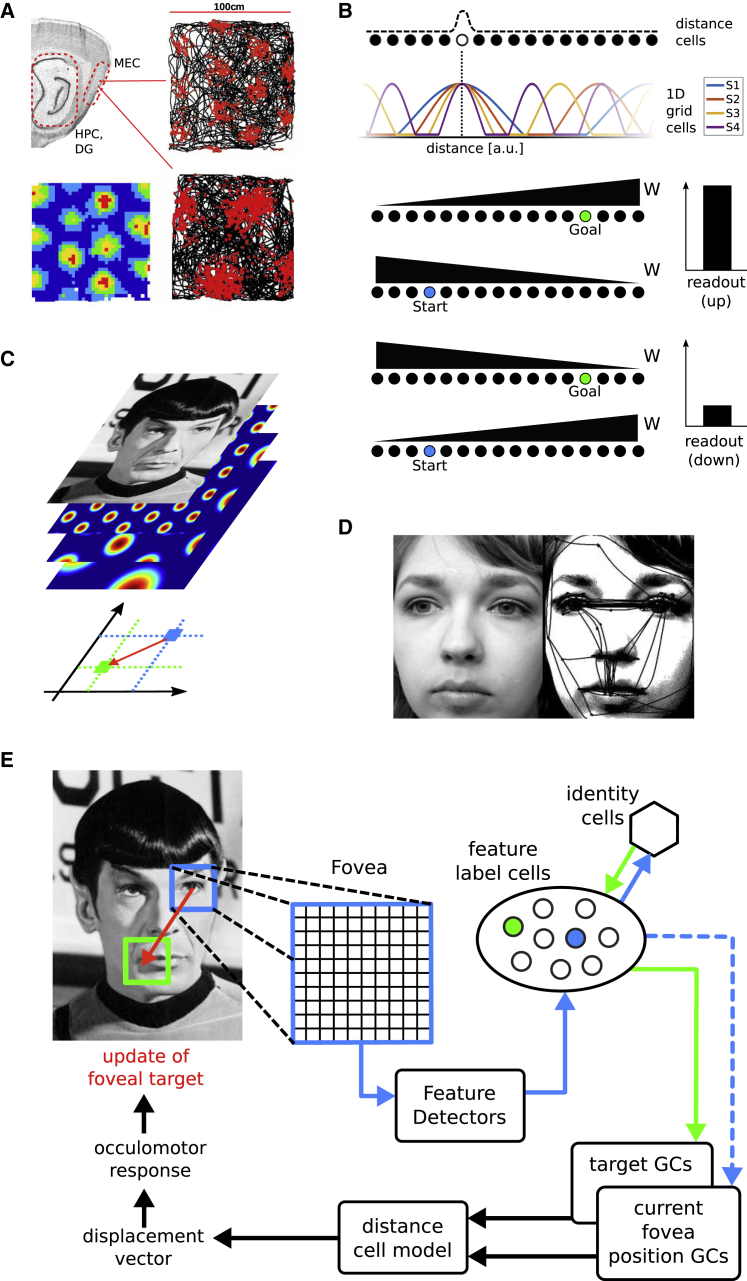
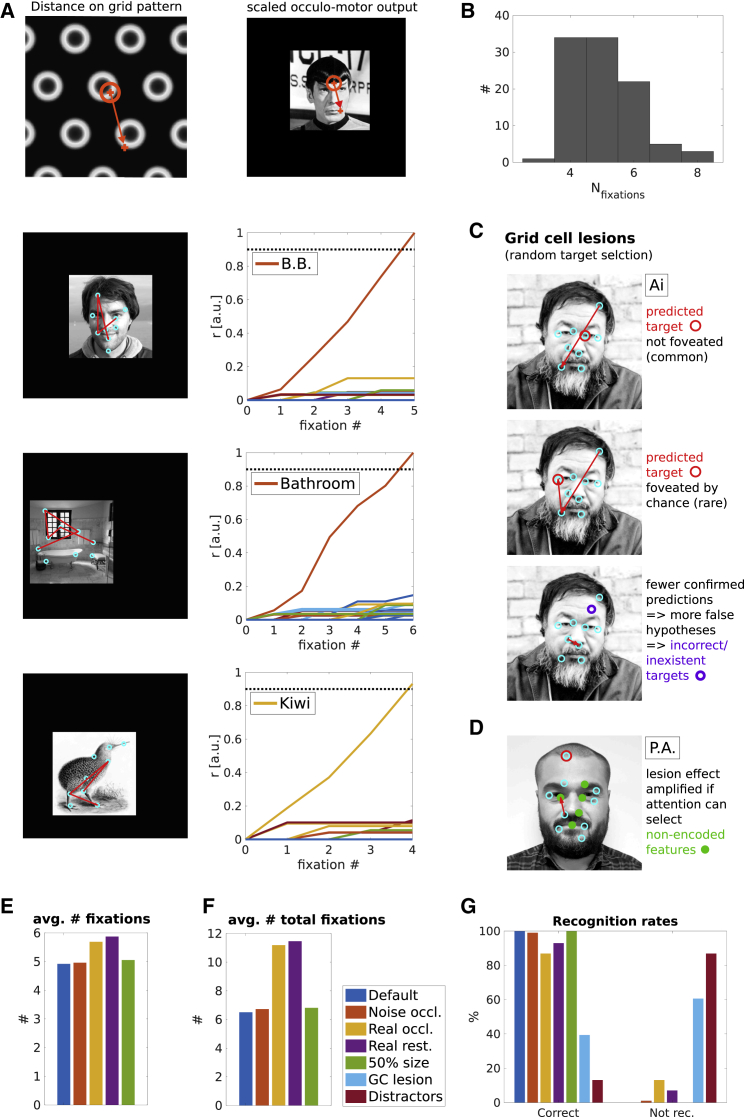
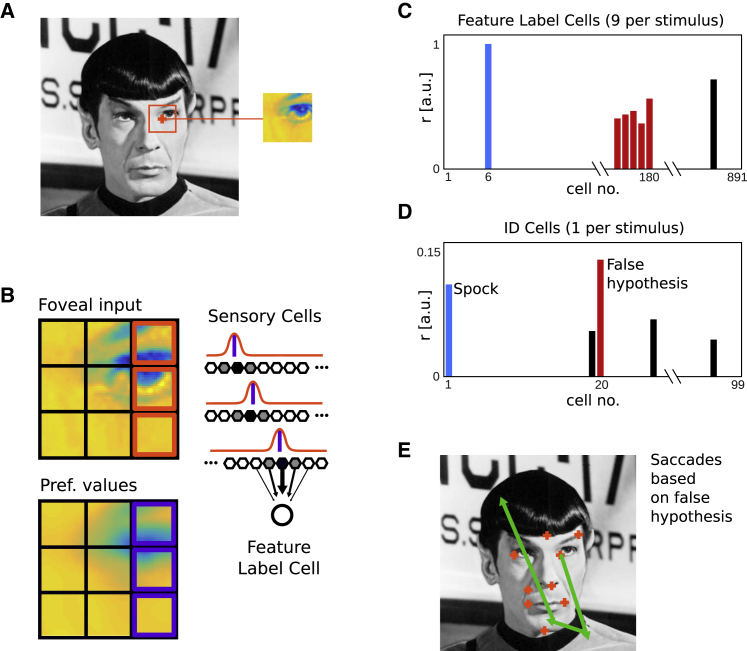
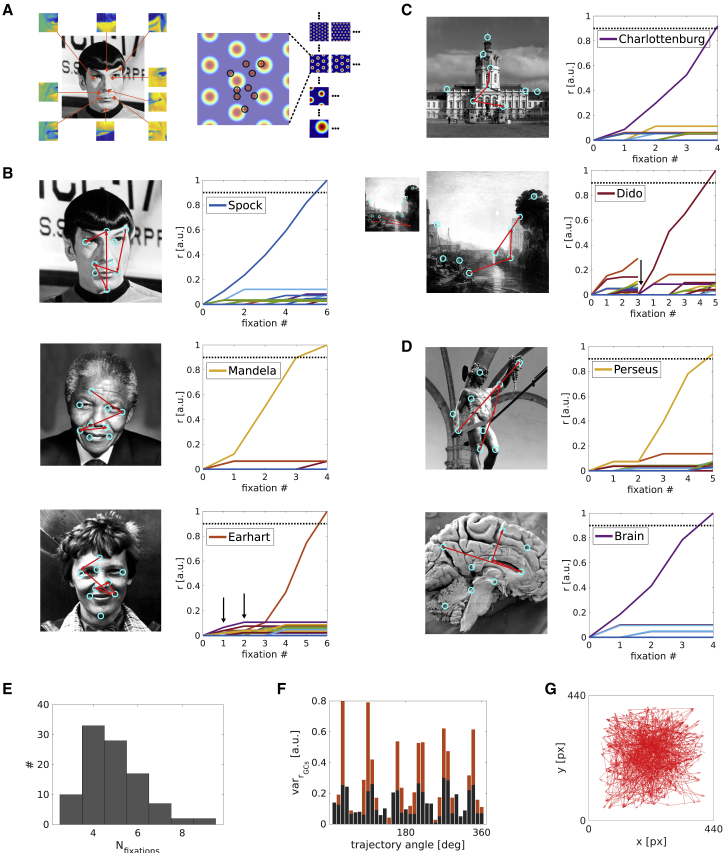
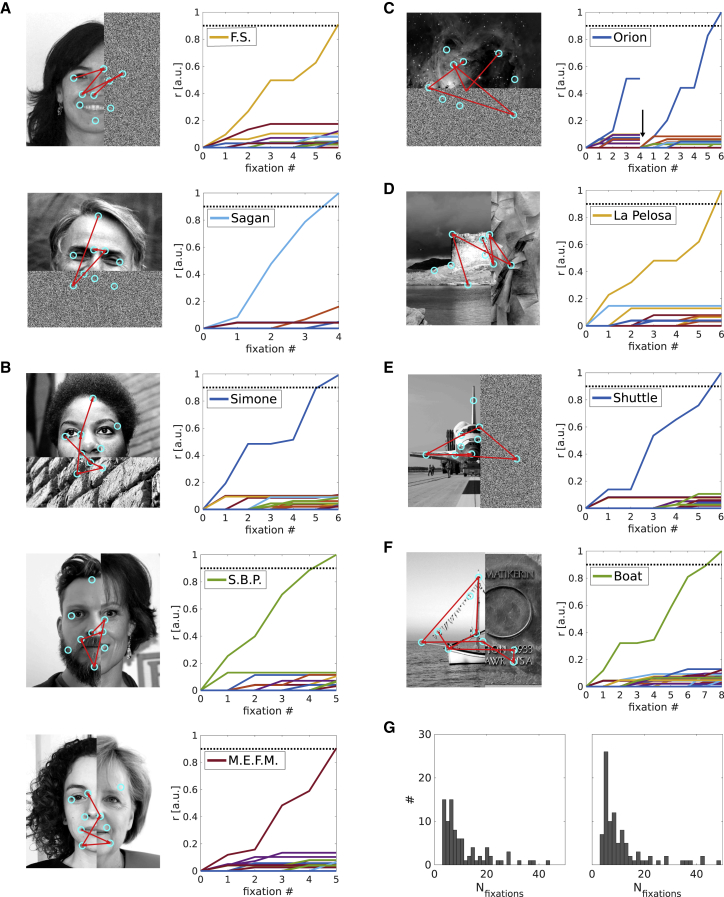
Models of face, object, and scene recognition traditionally focus on massively parallel processing of low-level features, with higher-order representations emerging at later processing stages. However, visual perception is tightly coupled to eye movements, which are necessarily sequential. Recently, neurons in entorhinal cortex have been reported with grid cell-like firing in response to eye movements, i.e., in visual space. Following the presumed role of grid cells in vector navigation, we propose a model of recognition memory for familiar faces, objects, and scenes, in which grid cells encode translation vectors between salient stimulus features. A sequence of saccadic eye-movement vectors, moving from one salient feature to the expected location of the next, potentially confirms an initial hypothesis (accumulating evidence toward a threshold) about stimulus identity, based on the relative feature layout (i.e., going beyond recognition of individual features). The model provides an explicit neural mechanism for the long-held view that directed saccades support hypothesis-driven, constructive perception and recognition; is compatible with holistic face processing; and constitutes the first quantitative proposal for a role of grid cells in visual recognition. The variance of grid cell activity along saccade trajectories exhibits 6-fold symmetry across 360 degrees akin to recently reported fMRI data. The model suggests that disconnecting grid cells from occipitotemporal inputs may yield prosopagnosia-like symptoms. The mechanism is robust with regard to partial visual occlusion, can accommodate size and position invariance, and suggests a functional explanation for medial temporal lobe involvement in visual memory for relational information and memory-guided attention.
传统的面孔、物体和场景识别模型主要侧重于对低水平特征的大规模并行处理,而更高阶的表示则在后续处理阶段出现。然而,视觉感知与眼球运动紧密相连,而眼球运动是必然顺序的。最近,有报道称内嗅皮层中的神经元在对眼球运动(即在视觉空间中)做出反应时具有类似网格细胞的放电模式。鉴于网格细胞在向量导航中的假定作用,我们提出了一个用于熟悉面孔、物体和场景的识别记忆模型,其中网格细胞编码显著刺激特征之间的平移向量。一系列的眼跳运动向量,从一个显著特征移动到下一个特征的预期位置,可能会根据相对特征布局(即超越对单个特征的识别),基于初始假设(在阈值处积累证据),确认刺激的身份。该模型为以下观点提供了明确的神经机制:定向眼跳支持基于假设的、建设性的感知和识别;与整体面部处理兼容;并首次提出了网格细胞在视觉识别中的作用的定量建议。网格细胞活动在眼跳轨迹上的变化表现出 6 倍的对称性,跨越 360 度,类似于最近报道的 fMRI 数据。该模型表明,将网格细胞与枕颞输入分离可能会导致面孔失认症样症状。该机制对部分视觉遮挡具有鲁棒性,可以容纳大小和位置不变性,并为内侧颞叶参与视觉记忆中关系信息和记忆引导注意提供了功能解释。