State Key Laboratory of Tea Plant Biology and Utilization, Anhui Agricultural University, Hefei, 230036, China.
Plant Biotechnol J. 2019 Oct;17(10):1938-1953. doi: 10.1111/pbi.13111. Epub 2019 Apr 11.
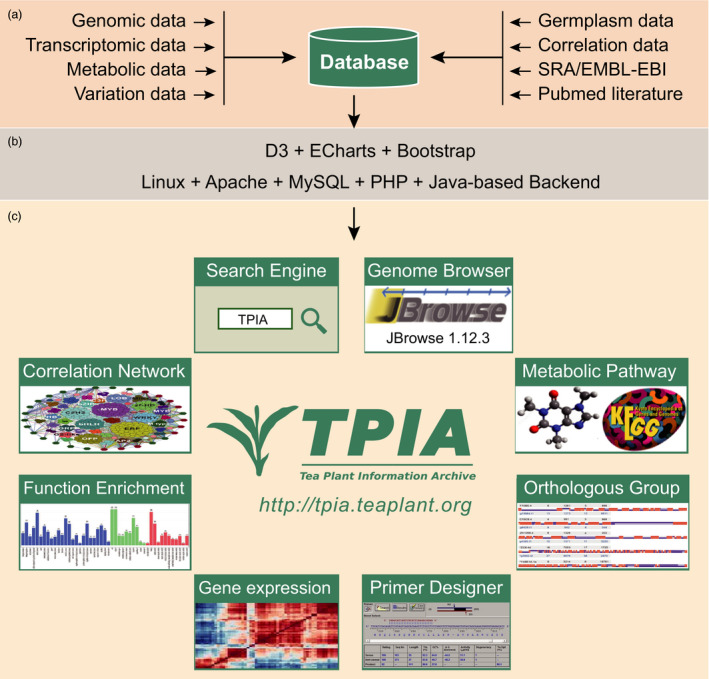
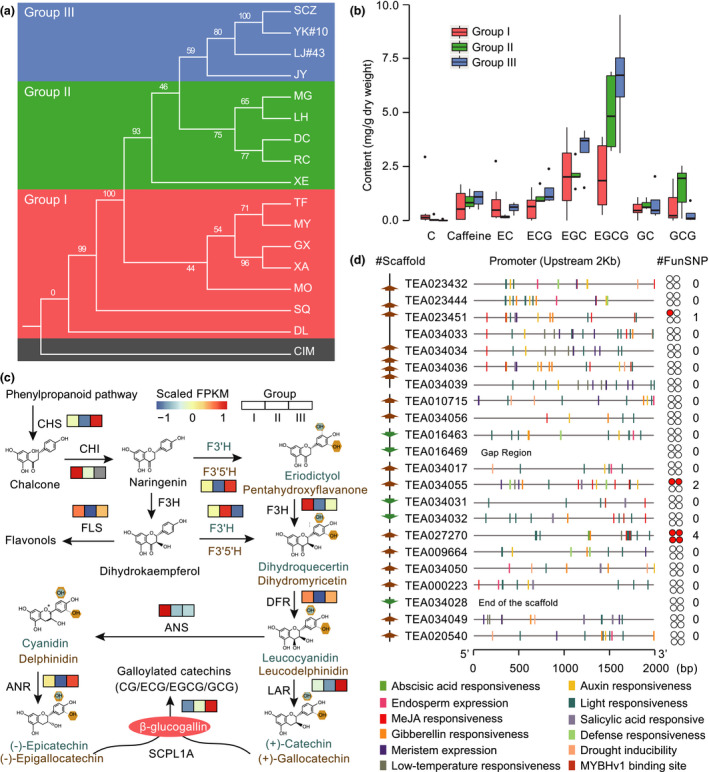
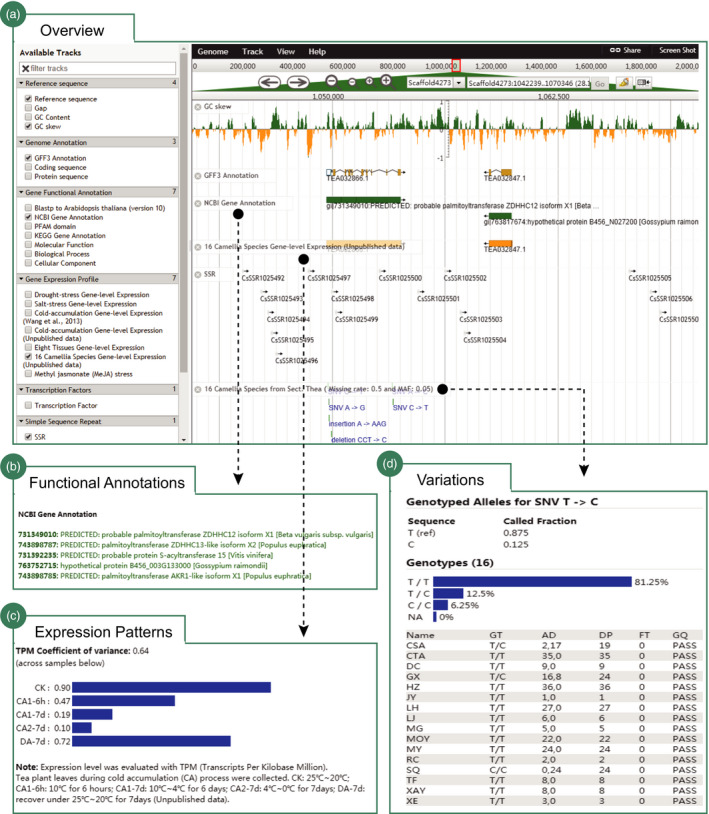
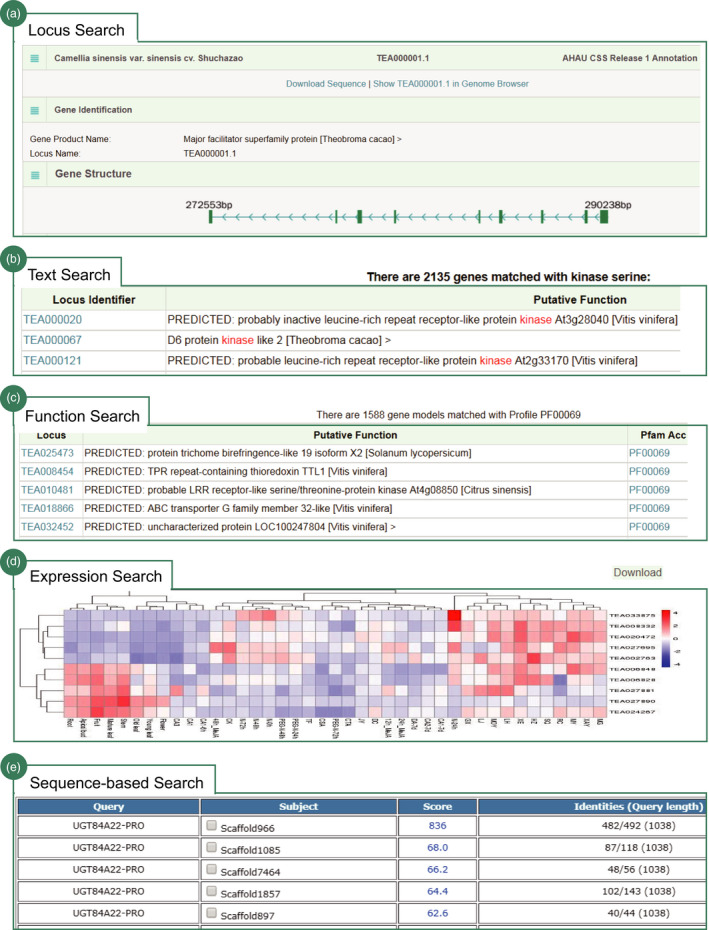
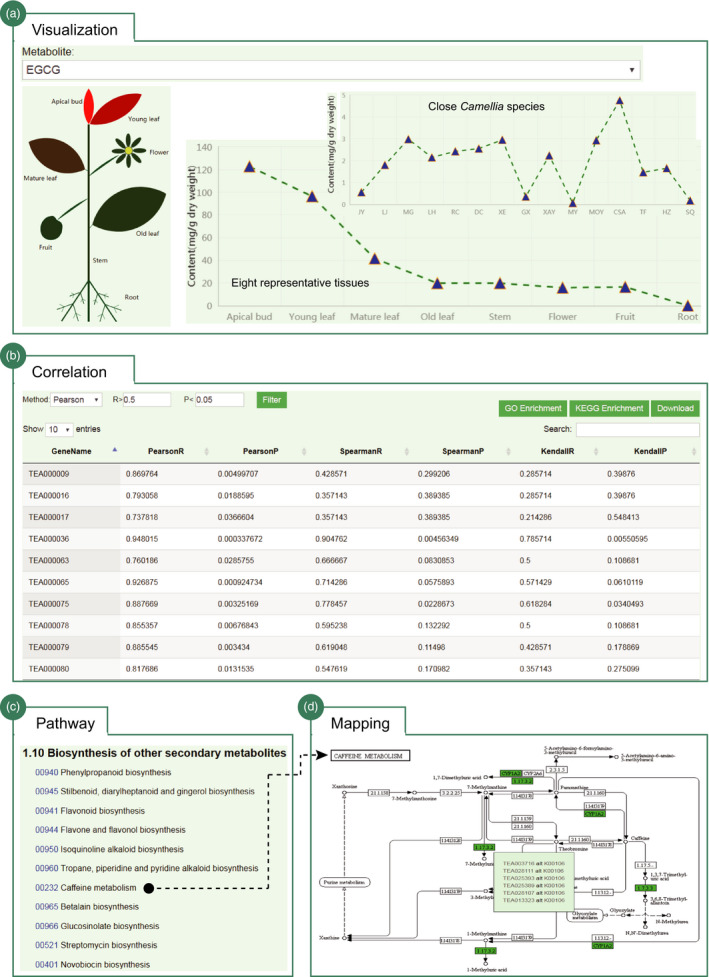
Tea is the world's widely consumed nonalcohol beverage with essential economic and health benefits. Confronted with the increasing large-scale omics-data set particularly the genome sequence released in tea plant, the construction of a comprehensive knowledgebase is urgently needed to facilitate the utilization of these data sets towards molecular breeding. We hereby present the first integrative and specially designed web-accessible database, Tea Plant Information Archive (TPIA; http://tpia.teaplant.org). The current release of TPIA employs the comprehensively annotated tea plant genome as framework and incorporates with abundant well-organized transcriptomes, gene expressions (across species, tissues and stresses), orthologs and characteristic metabolites determining tea quality. It also hosts massive transcription factors, polymorphic simple sequence repeats, single nucleotide polymorphisms, correlations, manually curated functional genes and globally collected germplasm information. A variety of versatile analytic tools (e.g. JBrowse, blast, enrichment analysis, etc.) are established helping users to perform further comparative, evolutionary and functional analysis. We show a case application of TPIA that provides novel and interesting insights into the phytochemical content variation of section Thea of genus Camellia under a well-resolved phylogenetic framework. The constructed knowledgebase of tea plant will serve as a central gateway for global tea community to better understand the tea plant biology that largely benefits the whole tea industry.
茶是世界上广泛饮用的非酒精饮料,具有重要的经济和健康益处。面对日益增多的大规模组学数据集,特别是茶树基因组序列的发布,迫切需要构建一个综合知识库,以促进这些数据集在分子育种中的利用。我们在此介绍第一个综合的、专门设计的可通过网络访问的数据库,即茶树信息档案(TPIA;http://tpia.teaplant.org)。目前发布的 TPIA 以全面注释的茶树基因组为框架,结合了丰富的、组织良好的转录组、基因表达(跨物种、组织和胁迫)、同源物和决定茶叶品质的特征代谢物。它还拥有大量的转录因子、多态性简单重复序列、单核苷酸多态性、相关性、经过精心编辑的功能基因以及全球收集的种质信息。建立了各种多功能分析工具(例如 JBrowse、blast、富集分析等),帮助用户进行进一步的比较、进化和功能分析。我们展示了 TPIA 的一个应用案例,该案例在一个经过良好解析的系统发育框架下,为理解山茶属茶组植物的植物化学物质含量变化提供了新的有趣见解。构建的茶树知识库将成为全球茶界了解茶树生物学的中心门户,这将使整个茶产业受益匪浅。