School of Computer Science, Wuhan University, Wuhan, 430072, People's Republic of China.
Suzhou Institute of Wuhan University, Suzhou, 215123, People's Republic of China.
BMC Bioinformatics. 2019 Mar 29;20(Suppl 3):134. doi: 10.1186/s12859-019-2644-5.
In the field of drug repositioning, it is assumed that similar drugs may treat similar diseases, therefore many existing computational methods need to compute the similarities of drugs and diseases. However, the calculation of similarity depends on the adopted measure and the available features, which may lead that the similarity scores vary dramatically from one to another, and it will not work when facing the incomplete data. Besides, supervised learning based methods usually need both positive and negative samples to train the prediction models, whereas in drug-disease pairs data there are only some verified interactions (positive samples) and a lot of unlabeled pairs. To train the models, many methods simply treat the unlabeled samples as negative ones, which may introduce artificial noises. Herein, we propose a method to predict drug-disease associations without the need of similarity information, and select more likely negative samples.
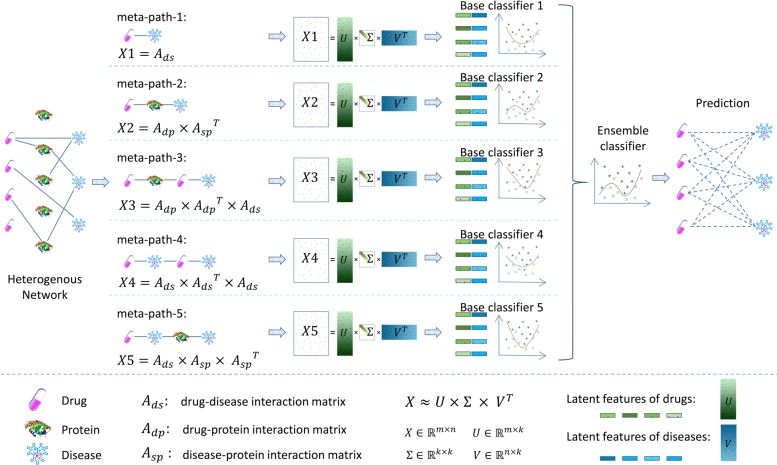
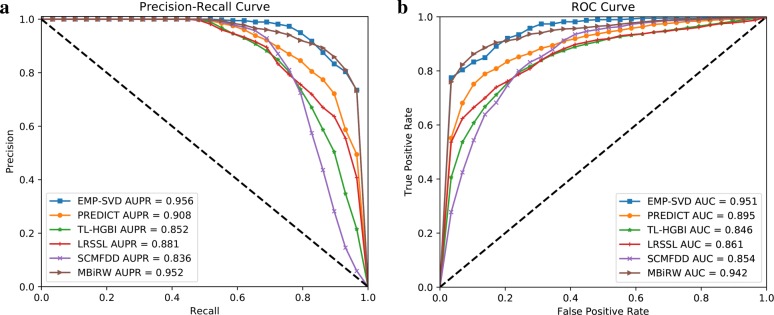
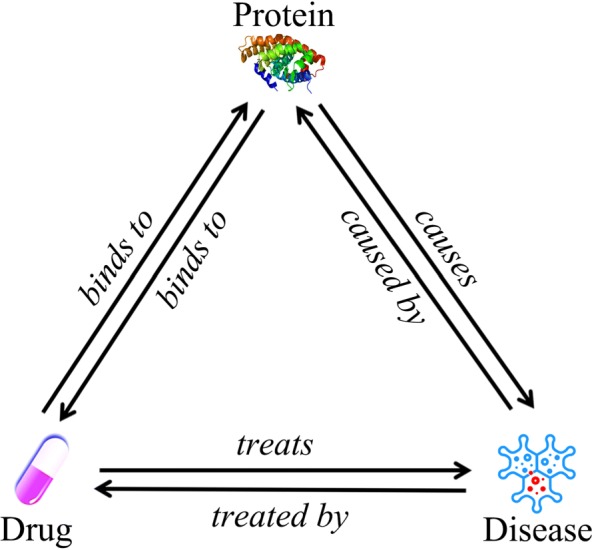
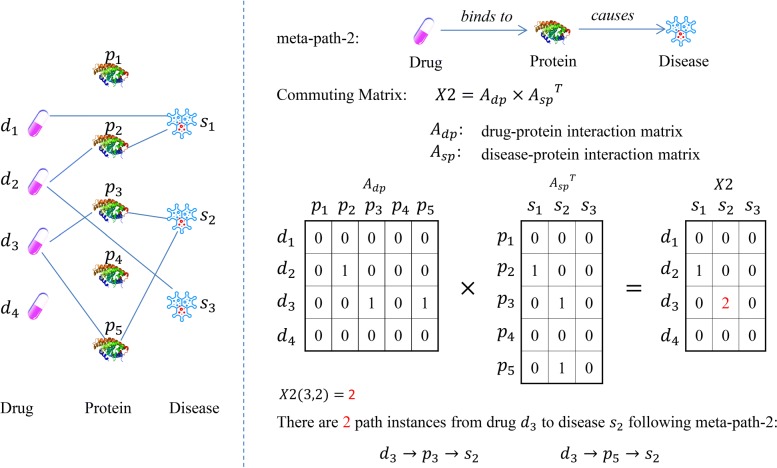
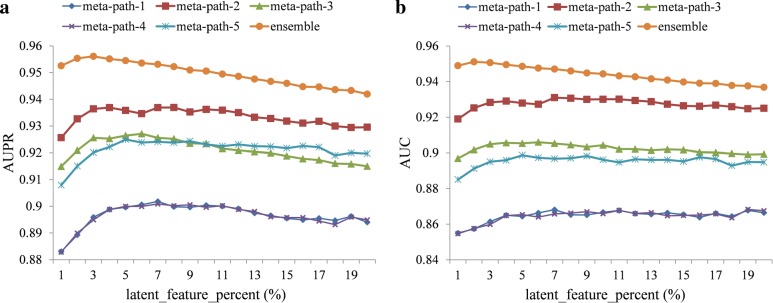
In the proposed EMP-SVD (Ensemble Meta Paths and Singular Value Decomposition), we introduce five meta paths corresponding to different kinds of interaction data, and for each meta path we generate a commuting matrix. Every matrix is factorized into two low rank matrices by SVD which are used for the latent features of drugs and diseases respectively. The features are combined to represent drug-disease pairs. We build a base classifier via Random Forest for each meta path and five base classifiers are combined as the final ensemble classifier. In order to train out a more reliable prediction model, we select more likely negative ones from unlabeled samples under the assumption that non-associated drug and disease pair have no common interacted proteins. The experiments have shown that the proposed EMP-SVD method outperforms several state-of-the-art approaches. Case studies by literature investigation have found that the proposed EMP-SVD can mine out many drug-disease associations, which implies the practicality of EMP-SVD.
The proposed EMP-SVD can integrate the interaction data among drugs, proteins and diseases, and predict the drug-disease associations without the need of similarity information. At the same time, the strategy of selecting more reliable negative samples will benefit the prediction.
在药物重定位领域,人们假设相似的药物可能治疗相似的疾病,因此许多现有的计算方法需要计算药物和疾病的相似性。然而,相似性的计算取决于所采用的度量标准和可用的特征,这可能导致相似性得分在一个方法和另一个方法之间差异巨大,并且在面对不完整的数据时无法工作。此外,基于监督学习的方法通常需要正例和负例来训练预测模型,而在药物-疾病对数据中只有一些已验证的相互作用(正例)和大量未标记的对。为了训练模型,许多方法简单地将未标记的样本视为负例,这可能会引入人为噪声。在这里,我们提出了一种无需相似性信息即可预测药物-疾病关联的方法,并选择更可能的负例。
在提出的 EMP-SVD(集成元路径和奇异值分解)中,我们引入了对应于不同类型的交互数据的五条元路径,并为每条元路径生成一个交换矩阵。每个矩阵通过 SVD 分解成两个低秩矩阵,分别用于药物和疾病的潜在特征。特征组合起来表示药物-疾病对。我们通过随机森林为每条元路径构建一个基础分类器,并将五个基础分类器组合成最终的集成分类器。为了训练出一个更可靠的预测模型,我们假设非相关的药物-疾病对没有共同的相互作用蛋白,从未标记的样本中选择更可能的负例。实验表明,所提出的 EMP-SVD 方法优于几种最先进的方法。通过文献调查进行的案例研究发现,所提出的 EMP-SVD 可以挖掘出许多药物-疾病关联,这表明 EMP-SVD 的实用性。
所提出的 EMP-SVD 可以整合药物、蛋白质和疾病之间的交互数据,无需相似性信息即可预测药物-疾病关联。同时,选择更可靠的负例的策略将有利于预测。