Chevrier Raphaël, Foufi Vasiliki, Gaudet-Blavignac Christophe, Robert Arnaud, Lovis Christian
Division of Medical Information Sciences, University Hospitals of Geneva, Geneva, Switzerland.
Faculty of Medicine, University of Geneva, Geneva, Switzerland.
J Med Internet Res. 2019 May 31;21(5):e13484. doi: 10.2196/13484.
The secondary use of health data is central to biomedical research in the era of data science and precision medicine. National and international initiatives, such as the Global Open Findable, Accessible, Interoperable, and Reusable (GO FAIR) initiative, are supporting this approach in different ways (eg, making the sharing of research data mandatory or improving the legal and ethical frameworks). Preserving patients' privacy is crucial in this context. De-identification and anonymization are the two most common terms used to refer to the technical approaches that protect privacy and facilitate the secondary use of health data. However, it is difficult to find a consensus on the definitions of the concepts or on the reliability of the techniques used to apply them. A comprehensive review is needed to better understand the domain, its capabilities, its challenges, and the ratio of risk between the data subjects' privacy on one side, and the benefit of scientific advances on the other.
This work aims at better understanding how the research community comprehends and defines the concepts of de-identification and anonymization. A rich overview should also provide insights into the use and reliability of the methods. Six aspects will be studied: (1) terminology and definitions, (2) backgrounds and places of work of the researchers, (3) reasons for anonymizing or de-identifying health data, (4) limitations of the techniques, (5) legal and ethical aspects, and (6) recommendations of the researchers.
Based on a scoping review protocol designed a priori, MEDLINE was searched for publications discussing de-identification or anonymization and published between 2007 and 2017. The search was restricted to MEDLINE to focus on the life sciences community. The screening process was performed by two reviewers independently.
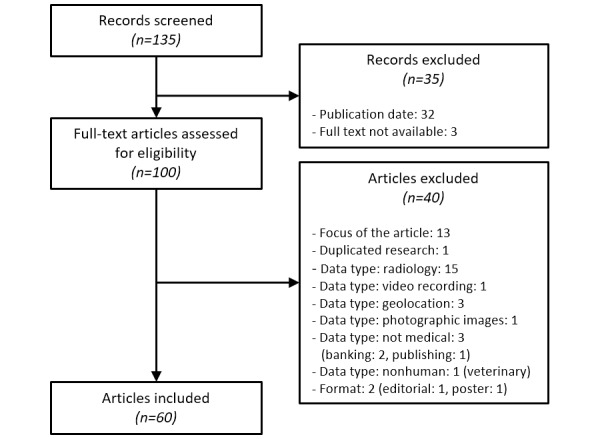
After searching 7972 records that matched at least one search term, 135 publications were screened and 60 full-text articles were included. (1) Terminology: Definitions of the terms de-identification and anonymization were provided in less than half of the articles (29/60, 48%). When both terms were used (41/60, 68%), their meanings divided the authors into two equal groups (19/60, 32%, each) with opposed views. The remaining articles (3/60, 5%) were equivocal. (2) Backgrounds and locations: Research groups were based predominantly in North America (31/60, 52%) and in the European Union (22/60, 37%). The authors came from 19 different domains; computer science (91/248, 36.7%), biomedical informatics (47/248, 19.0%), and medicine (38/248, 15.3%) were the most prevalent ones. (3) Purpose: The main reason declared for applying these techniques is to facilitate biomedical research. (4) Limitations: Progress is made on specific techniques but, overall, limitations remain numerous. (5) Legal and ethical aspects: Differences exist between nations in the definitions, approaches, and legal practices. (6) Recommendations: The combination of organizational, legal, ethical, and technical approaches is necessary to protect health data.
Interest is growing for privacy-enhancing techniques in the life sciences community. This interest crosses scientific boundaries, involving primarily computer science, biomedical informatics, and medicine. The variability observed in the use of the terms de-identification and anonymization emphasizes the need for clearer definitions as well as for better education and dissemination of information on the subject. The same observation applies to the methods. Several legislations, such as the American Health Insurance Portability and Accountability Act (HIPAA) and the European General Data Protection Regulation (GDPR), regulate the domain. Using the definitions they provide could help address the variable use of these two concepts in the research community.

在数据科学和精准医学时代,健康数据的二次利用是生物医学研究的核心。国家和国际倡议,如全球开放、可查找、可访问、可互操作和可重用(GO FAIR)倡议,正在以不同方式支持这种方法(例如,强制要求共享研究数据或完善法律和伦理框架)。在这种情况下,保护患者隐私至关重要。去标识化和匿名化是用于指代保护隐私并促进健康数据二次利用的技术方法的两个最常用术语。然而,对于这些概念的定义或用于应用它们的技术的可靠性,很难达成共识。需要进行全面综述,以更好地理解该领域、其能力、挑战以及一方面数据主体隐私与另一方面科学进步益处之间的风险比例。
这项工作旨在更好地理解研究界如何理解和定义去标识化和匿名化概念。丰富的概述还应提供有关方法的使用和可靠性的见解。将研究六个方面:(1)术语和定义;(2)研究人员的背景和工作地点;(3)对健康数据进行匿名化或去标识化的原因;(4)技术的局限性;(5)法律和伦理方面;(6)研究人员的建议。
基于事先设计的范围综述方案,在MEDLINE中搜索2007年至2017年期间讨论去标识化或匿名化的出版物。搜索仅限于MEDLINE,以专注于生命科学领域。筛选过程由两名审稿人独立进行。
在搜索了7972条至少匹配一个搜索词的记录后,筛选了135篇出版物,纳入了60篇全文文章。(1)术语:不到一半的文章(29/60,48%)提供了去标识化和匿名化术语的定义。当同时使用这两个术语时(41/60,68%),它们的含义将作者分成了两组(各19/60,32%),观点相反。其余文章(3/60,5%)含糊不清。(2)背景和地点:研究团队主要位于北美(31/60,52%)和欧盟(22/60,37%)。作者来自19个不同领域;计算机科学(91/248,36.7%)、生物医学信息学(47/248,19.0%)和医学(上38/248,15.3%)是最普遍的领域。(3)目的:声明应用这些技术的主要原因是促进生物医学研究。(4)局限性:特定技术有进展,但总体而言,局限性仍然很多。(5)法律和伦理方面:各国在定义、方法和法律实践上存在差异。(6)建议:组织、法律、伦理和技术方法相结合对于保护健康数据是必要的。
生命科学领域对增强隐私技术的兴趣在增加。这种兴趣跨越科学界限,主要涉及计算机科学、生物医学信息学和医学。在去标识化和匿名化术语的使用中观察到的变异性强调了需要更清晰的定义以及更好地开展关于该主题的教育和信息传播。同样的观察结果也适用于方法。一些立法,如美国《健康保险流通与责任法案》(HIPAA)和欧洲《通用数据保护条例》(GDPR),对该领域进行规范。使用它们提供的定义有助于解决研究界对这两个概念的不同用法。