Federico Anthony, Karagiannis Tanya, Karri Kritika, Kishore Dileep, Koga Yusuke, Campbell Joshua D, Monti Stefano
Bioinformatics Program, Boston University, Boston, MA, United States.
Division of Computational Biomedicine, Boston University School of Medicine, Boston, MA, United States.
Front Genet. 2019 Jun 28;10:614. doi: 10.3389/fgene.2019.00614. eCollection 2019.
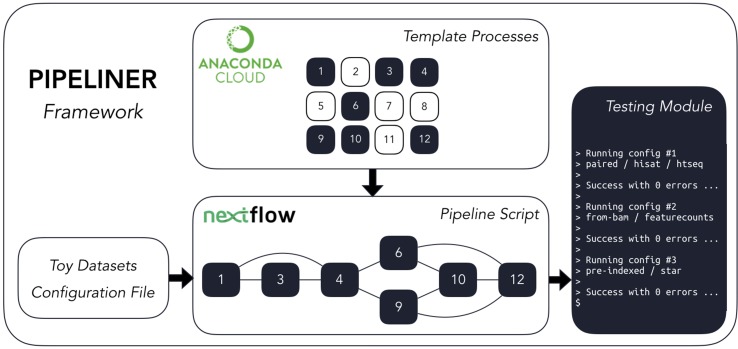
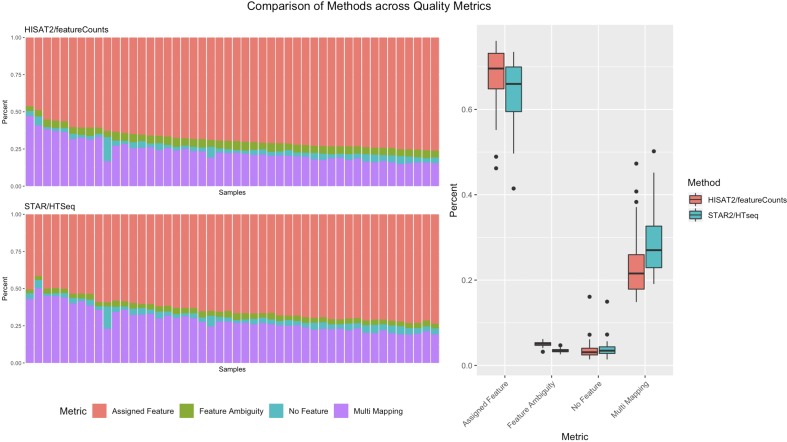
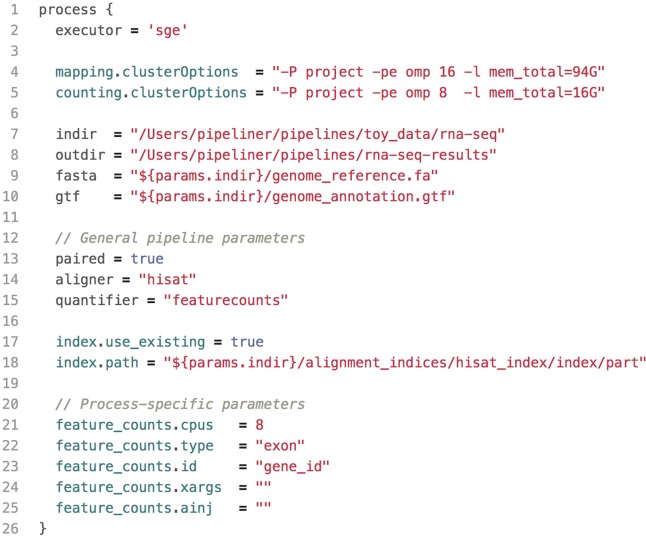
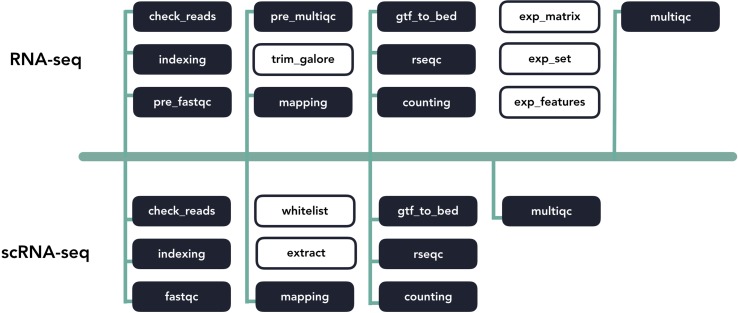
The advent of high-throughput sequencing technologies has led to the need for flexible and user-friendly data preprocessing platforms. The Pipeliner framework provides an out-of-the-box solution for processing various types of sequencing data. It combines the Nextflow scripting language and Anaconda package manager to generate modular computational workflows. We have used Pipeliner to create several pipelines for sequencing data processing including bulk RNA-sequencing (RNA-seq), single-cell RNA-seq, as well as digital gene expression data. This report highlights the design methodology behind Pipeliner that enables the development of highly flexible and reproducible pipelines that are easy to extend and maintain on multiple computing environments. We also provide a quick start user guide demonstrating how to setup and execute available pipelines with toy datasets.
高通量测序技术的出现导致了对灵活且用户友好的数据预处理平台的需求。Pipeliner框架为处理各种类型的测序数据提供了一个开箱即用的解决方案。它结合了Nextflow脚本语言和Anaconda包管理器来生成模块化的计算工作流程。我们已经使用Pipeliner创建了几个用于测序数据处理的管道,包括批量RNA测序(RNA-seq)、单细胞RNA-seq以及数字基因表达数据。本报告重点介绍了Pipeliner背后的设计方法,该方法能够开发出高度灵活且可重复的管道,这些管道易于在多个计算环境中扩展和维护。我们还提供了一个快速入门用户指南,展示了如何使用玩具数据集设置和执行可用的管道。