Hripcsak George, Albers David J
Department of Biomedical Informatics, Columbia University Medical Center, New York, NY, USA.
J Am Med Inform Assoc. 2018 Mar 1;25(3):289-294. doi: 10.1093/jamia/ocx110.
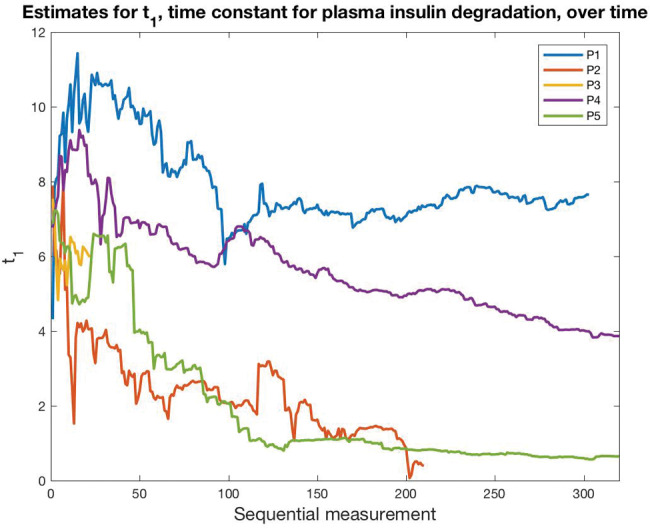
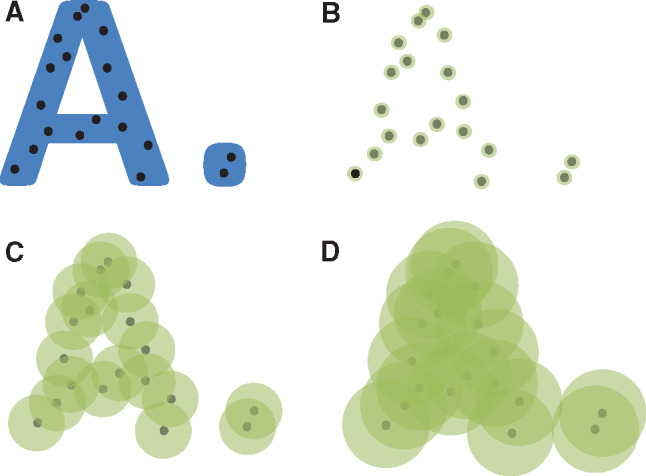
Electronic health record phenotyping is the use of raw electronic health record data to assert characterizations about patients. Researchers have been doing it since the beginning of biomedical informatics, under different names. Phenotyping will benefit from an increasing focus on fidelity, both in the sense of increasing richness, such as measured levels, degree or severity, timing, probability, or conceptual relationships, and in the sense of reducing bias. Research agendas should shift from merely improving binary assignment to studying and improving richer representations. The field is actively researching new temporal directions and abstract representations, including deep learning. The field would benefit from research in nonlinear dynamics, in combining mechanistic models with empirical data, including data assimilation, and in topology. The health care process produces substantial bias, and studying that bias explicitly rather than treating it as merely another source of noise would facilitate addressing it.
电子健康记录表型分析是利用原始电子健康记录数据来确定患者的特征。自生物医学信息学诞生之初,研究人员就一直在进行这项工作,只是名称不同。表型分析将受益于对保真度的日益关注,这既体现在增加丰富度方面,如测量水平、程度或严重性、时间、概率或概念关系,也体现在减少偏差方面。研究议程应从仅仅改进二元赋值转向研究和改进更丰富的表示形式。该领域正在积极研究新的时间方向和抽象表示形式,包括深度学习。该领域将受益于非线性动力学、将机制模型与经验数据相结合(包括数据同化)以及拓扑学方面的研究。医疗保健过程会产生大量偏差,明确研究这种偏差而非仅仅将其视为另一种噪声来源将有助于解决该问题。