Department of Biostatistics and Bioinformatics, Rollins School of Public Health, Emory University, 1518 Clifton Road NE, Atlanta, 30322, GA, USA.
Genome Biol. 2019 Sep 4;20(1):190. doi: 10.1186/s13059-019-1778-0.
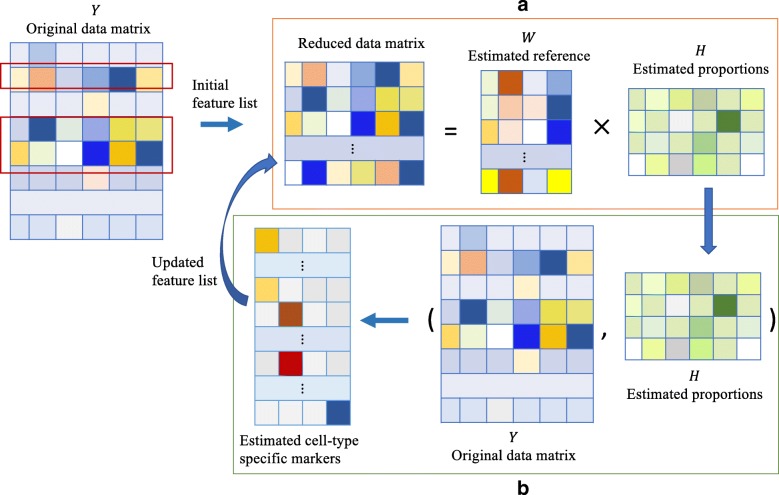
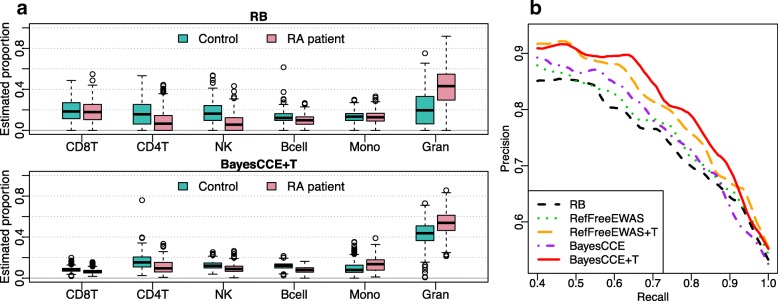
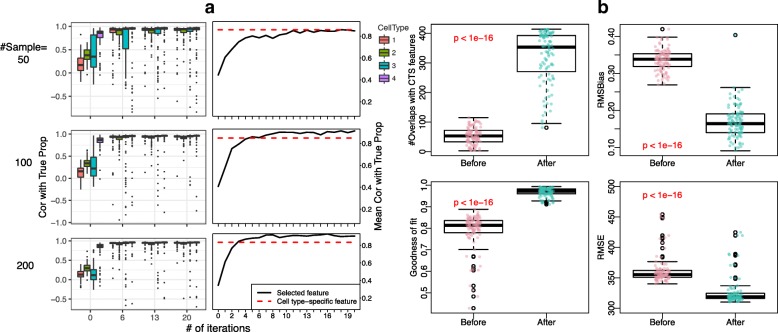
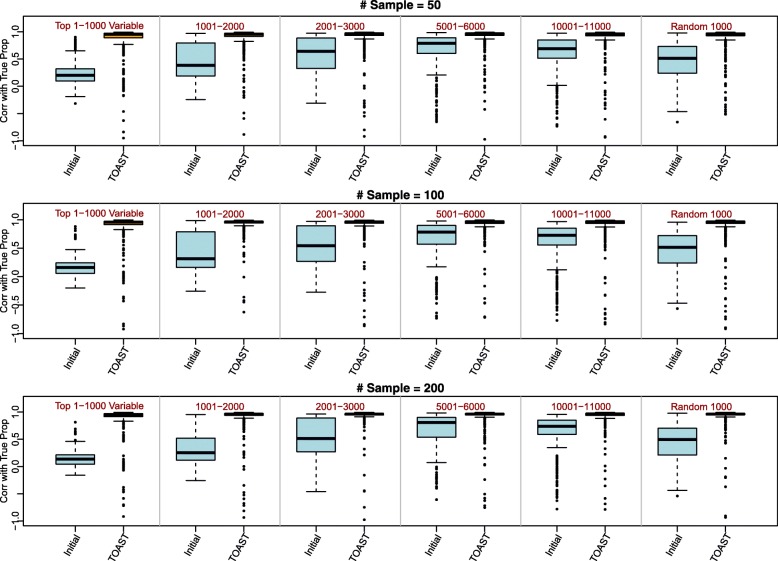
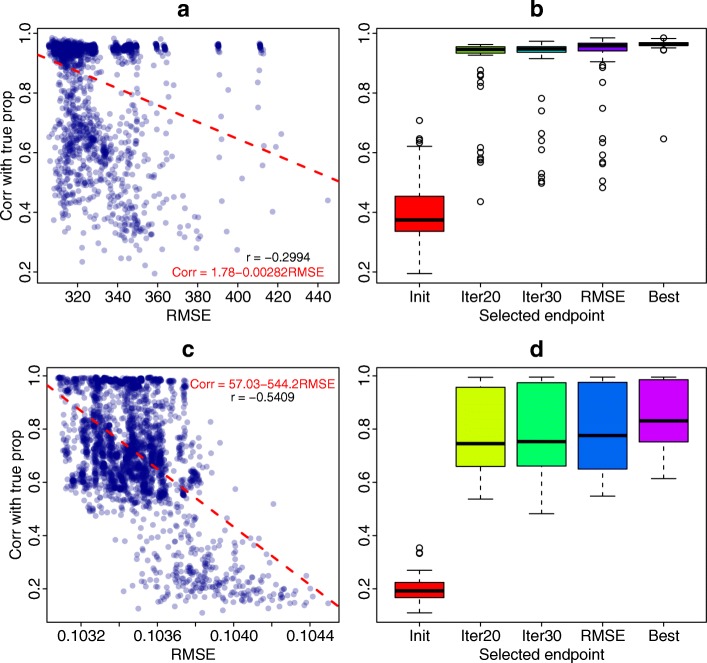
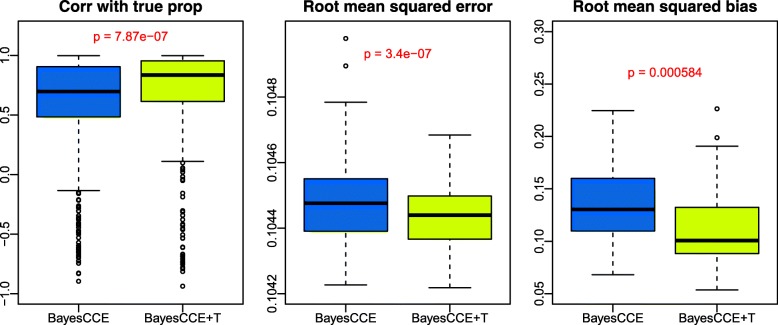
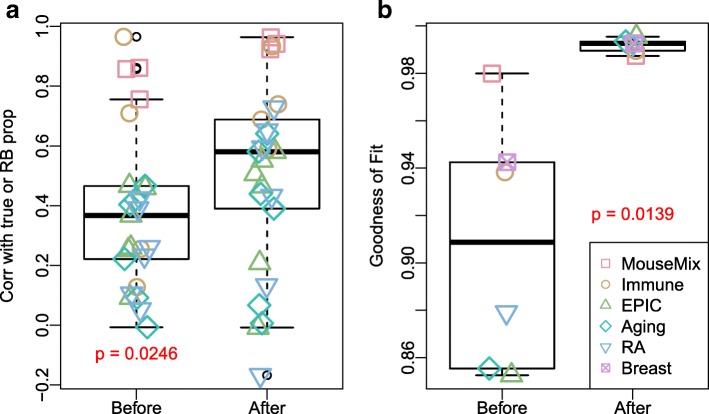
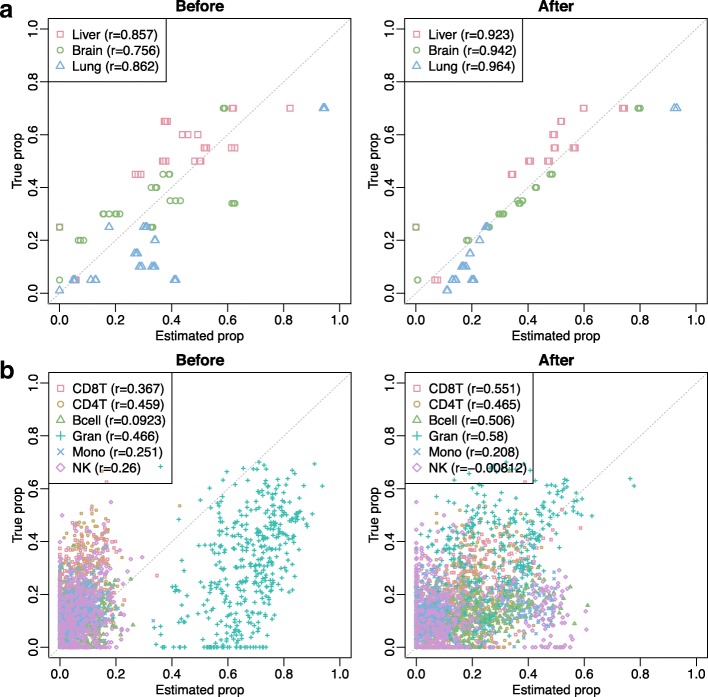
In the analysis of high-throughput data from complex samples, cell composition is an important factor that needs to be accounted for. Except for a limited number of tissues with known pure cell type profiles, a majority of genomics and epigenetics data relies on the "reference-free deconvolution" methods to estimate cell composition. We develop a novel computational method to improve reference-free deconvolution, which iteratively searches for cell type-specific features and performs composition estimation. Simulation studies and applications to six real datasets including both DNA methylation and gene expression data demonstrate favorable performance of the proposed method. TOAST is available at https://bioconductor.org/packages/TOAST .
在分析复杂样本的高通量数据时,细胞组成是一个需要考虑的重要因素。除了少数已知具有纯细胞类型特征的组织外,大多数基因组学和表观遗传学数据都依赖于“无参考解卷积”方法来估计细胞组成。我们开发了一种新的计算方法来改进无参考解卷积,该方法迭代地搜索细胞类型特异性特征并进行组成估计。模拟研究和对包括 DNA 甲基化和基因表达数据在内的六个真实数据集的应用表明,该方法具有良好的性能。TOAST 可在 https://bioconductor.org/packages/TOAST 获得。