Radiotherapy Department, Humanitas Research Hospital and Cancer Center, Via Manzoni 56, 20089 Rozzano, Milan, Italy.
Department of Biomedical Sciences, Humanitas University, Milan, Rozzano, Italy.
Radiat Oncol. 2019 Oct 30;14(1):187. doi: 10.1186/s13014-019-1403-0.
To determine if the performance of a knowledge based RapidPlan (RP) planning model could be improved with an iterative learning process, i.e. if plans generated by an RP model could be used as new input to re-train the model and achieve better performance.
Clinical VMAT plans from 83 patients presenting with head and neck cancer were selected to train an RP model, CL-1. With this model, new plans on the same patients were generated, and subsequently used as input to train a novel model, CL-2. Both models were validated on a cohort of 20 patients and dosimetric results compared. Another set of 83 plans was realised on the same patients with different planning criteria, by using a simple template with no attempt to manually improve the plan quality. Those plans were employed to train another model, TP-1. The differences between the plans generated by CL-1 and TP-1 for the validation cohort of patients were compared with respect to the differences between the original plans used to build the two models.
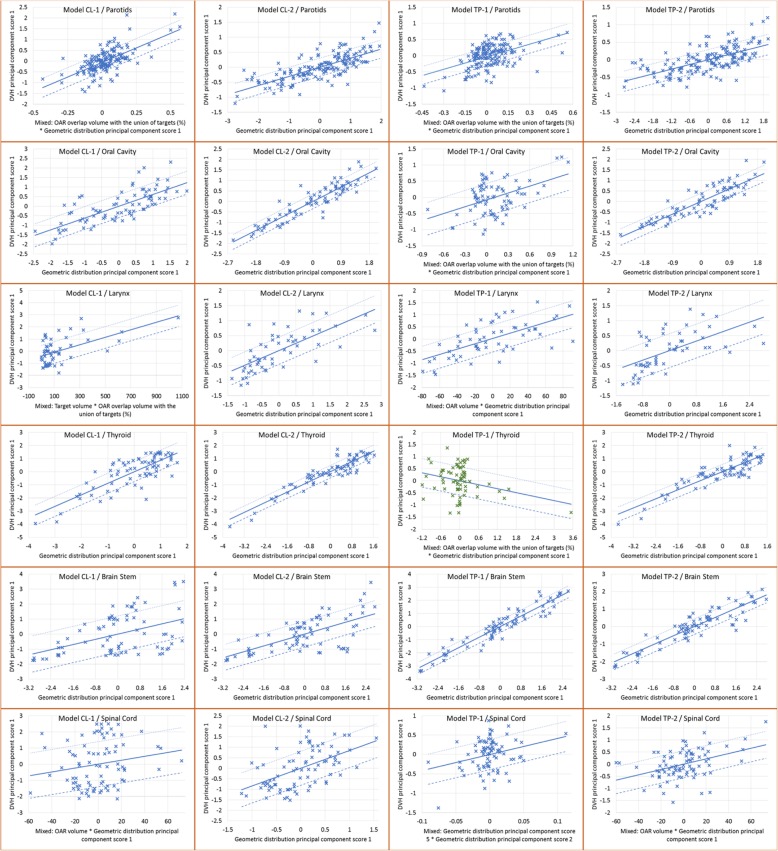
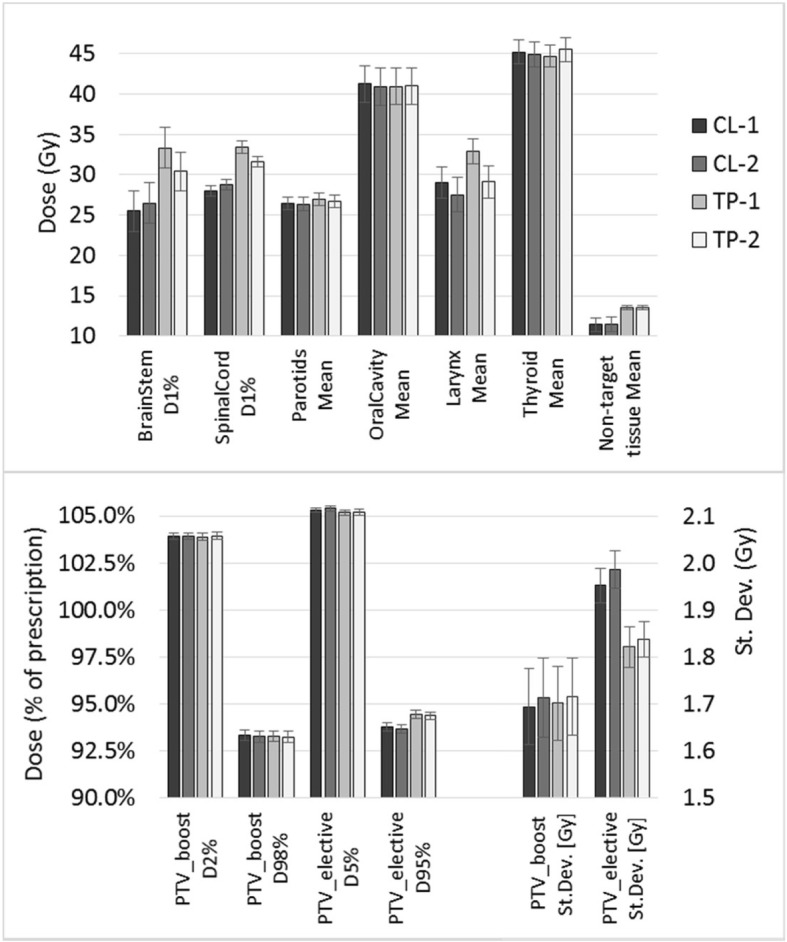
The CL-2 model presented an improvement relative to CL-1, with higher R values and better regression plots. The mean doses to parallel organs decreased with CL-2, while D to serial organs increased (but not significantly). The different models CL-1 and TP-1 were able to yield plans according to each original strategy.
A refined RP model allowed the generation of plans with improved quality, mostly for parallel organs at risk and, possibly, also the intrinsic model quality.
确定基于知识的 RapidPlan(RP)规划模型的性能是否可以通过迭代学习过程得到改善,即 RP 模型生成的计划是否可以用作新的输入来重新训练模型,以实现更好的性能。
选择 83 例头颈部癌症患者的临床 VMAT 计划来训练 RP 模型 CL-1。使用该模型为同一患者生成新的计划,然后将其用作输入来训练新模型 CL-2。对 20 例患者的队列进行了模型验证,并比较了剂量学结果。对于同一患者,使用没有尝试手动提高计划质量的简单模板实现了另一组 83 个计划。这些计划用于训练另一个模型 TP-1。对于验证患者队列,CL-1 和 TP-1 生成的计划之间的差异与用于构建两个模型的原始计划之间的差异进行了比较。
CL-2 模型相对于 CL-1 有所改进,R 值更高,回归图更好。平行危及器官的平均剂量随着 CL-2 的降低而降低,而串行器官的 D 值增加(但不显著)。不同的模型 CL-1 和 TP-1 能够根据各自的原始策略生成计划。
精细化的 RP 模型能够生成质量更高的计划,主要是对于平行的危及器官,并且可能还有内在的模型质量。