Graduate School of Public Health and Health Policy, City University of New York, New York, NY 10027, USA.
Institute for Implementation Science and Population Health, City University of New York, New York, NY 10027, USA.
Brief Bioinform. 2021 Jan 18;22(1):545-556. doi: 10.1093/bib/bbz158.
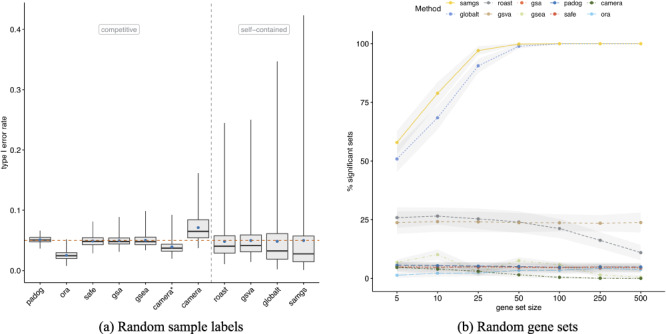
Although gene set enrichment analysis has become an integral part of high-throughput gene expression data analysis, the assessment of enrichment methods remains rudimentary and ad hoc. In the absence of suitable gold standards, evaluations are commonly restricted to selected datasets and biological reasoning on the relevance of resulting enriched gene sets.
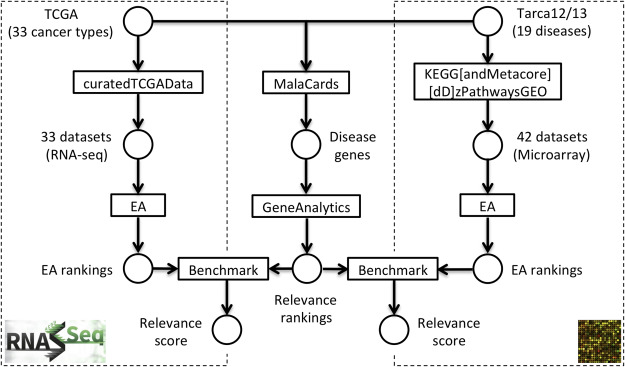
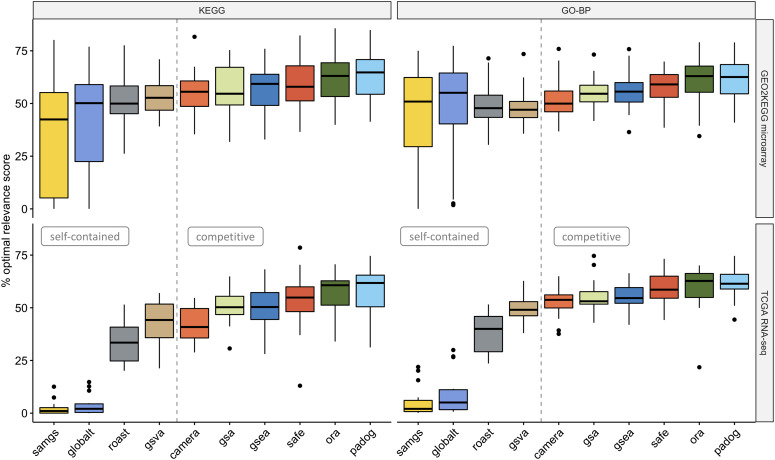
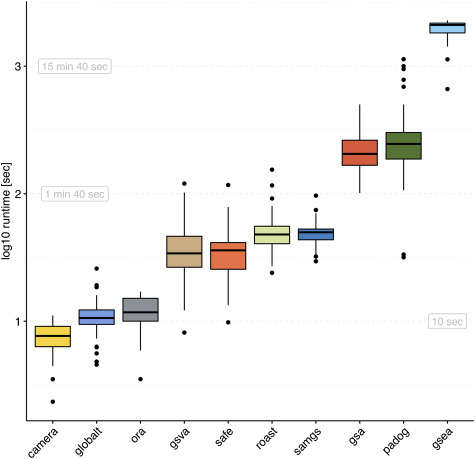
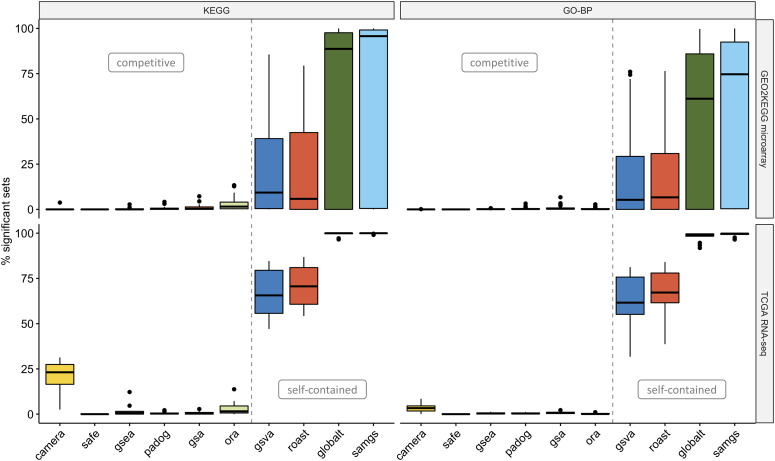
We develop an extensible framework for reproducible benchmarking of enrichment methods based on defined criteria for applicability, gene set prioritization and detection of relevant processes. This framework incorporates a curated compendium of 75 expression datasets investigating 42 human diseases. The compendium features microarray and RNA-seq measurements, and each dataset is associated with a precompiled GO/KEGG relevance ranking for the corresponding disease under investigation. We perform a comprehensive assessment of 10 major enrichment methods, identifying significant differences in runtime and applicability to RNA-seq data, fraction of enriched gene sets depending on the null hypothesis tested and recovery of the predefined relevance rankings. We make practical recommendations on how methods originally developed for microarray data can efficiently be applied to RNA-seq data, how to interpret results depending on the type of gene set test conducted and which methods are best suited to effectively prioritize gene sets with high phenotype relevance.
http://bioconductor.org/packages/GSEABenchmarkeR.
尽管基因集富集分析已成为高通量基因表达数据分析不可或缺的一部分,但对富集方法的评估仍然是初步和特定的。在缺乏合适的黄金标准的情况下,评估通常仅限于选定的数据集和基于相关基因集的生物学推理。
我们开发了一个可扩展的框架,用于基于适用性、基因集优先级和检测相关过程的定义标准,对富集方法进行可重复的基准测试。该框架包含了一个经过精心整理的 75 个人类疾病研究的表达数据集的汇编。该汇编包括微阵列和 RNA-seq 测量,每个数据集都与相应疾病的预先编译的 GO/KEGG 相关性排名相关联。我们对 10 种主要的富集方法进行了全面评估,确定了它们在运行时间和 RNA-seq 数据适用性方面的显著差异、根据测试的零假设而变化的富集基因集比例,以及对预定义相关性排名的恢复程度。我们提出了如何有效地将最初为微阵列数据开发的方法应用于 RNA-seq 数据的实际建议,如何根据进行的基因集测试类型来解释结果,以及哪些方法最适合有效地对具有高表型相关性的基因集进行优先级排序。
http://bioconductor.org/packages/GSEABenchmarkeR。