Lin Kueiyu Joshua, Rosenthal Gary E, Murphy Shawn N, Mandl Kenneth D, Jin Yinzhu, Glynn Robert J, Schneeweiss Sebastian
Division of Pharmacoepidemiology and Pharmacoeconomics, Department of Medicine, Brigham and Women's Hospital, Harvard Medical School, Boston, MA, USA.
Department of Medicine, Massachusetts General Hospital, Harvard Medical School, Boston, MA, USA.
Clin Epidemiol. 2020 Feb 4;12:133-141. doi: 10.2147/CLEP.S232540. eCollection 2020.
Electronic health records (EHR) data-discontinuity, i.e. receiving care outside of a particular EHR system, may cause misclassification of study variables. We aimed to validate an algorithm to identify patients with high EHR data-continuity to reduce such bias.
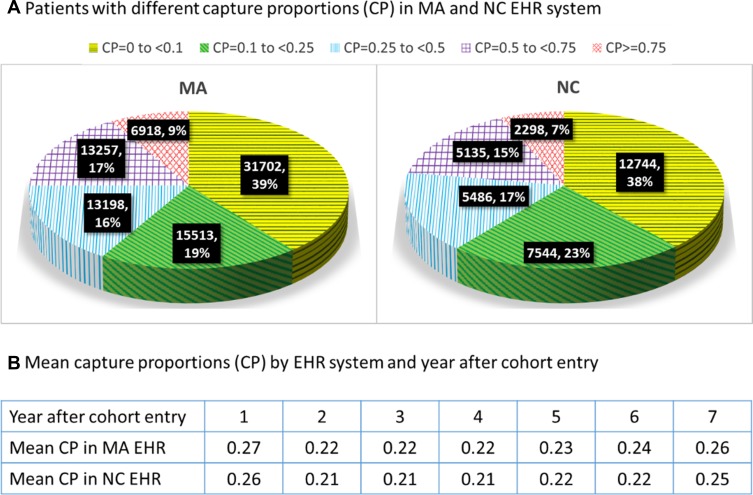
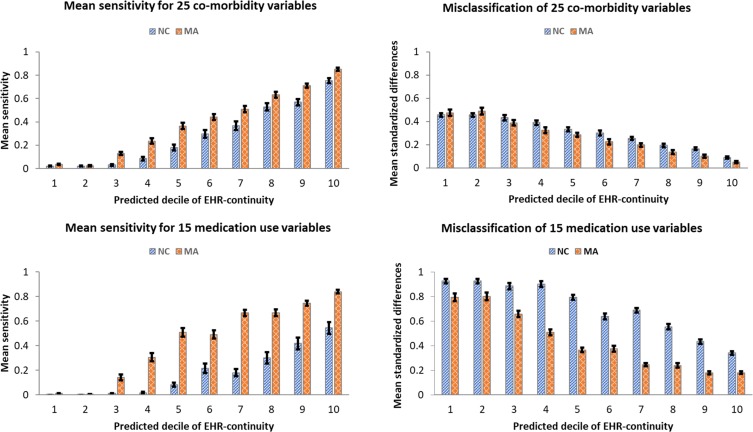
We analyzed data from two EHR systems linked with Medicare claims data from 2007 through 2014, one in Massachusetts (MA, n=80,588) and the other in North Carolina (NC, n=33,207). We quantified EHR data-continuity by Mean Proportion of Encounters Captured (MPEC) by the EHR system when compared to complete recording in claims data. The prediction model for MPEC was developed in MA and validated in NC. Stratified by predicted EHR data-continuity, we quantified misclassification of 40 key variables by Mean Standardized Differences (MSD) between the proportions of these variables based on EHR alone vs the linked claims-EHR data.
The mean MPEC was 27% in the MA and 26% in the NC system. The predicted and observed EHR data-continuity was highly correlated (Spearman correlation=0.78 and 0.73, respectively). The misclassification (MSD) of 40 variables in patients of the predicted EHR data-continuity cohort was significantly smaller (44%, 95% CI: 40-48%) than that in the remaining population.
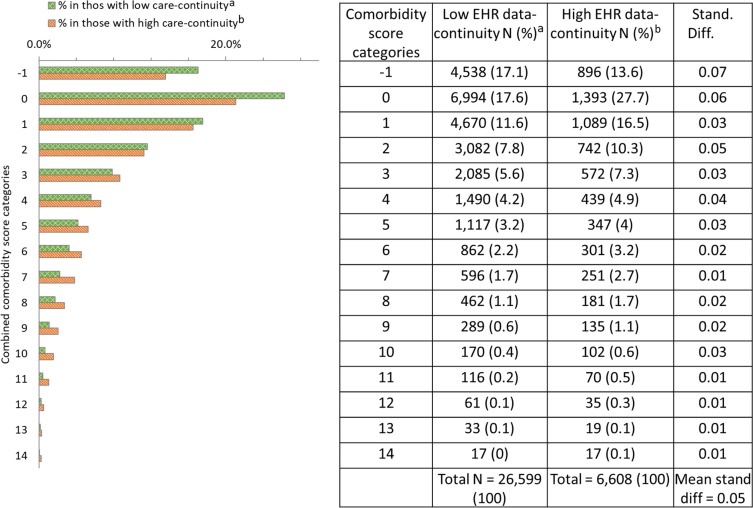
The comorbidity profiles were similar in patients with high vs low EHR data-continuity. Therefore, restricting an analysis to patients with high EHR data-continuity may reduce information bias while preserving the representativeness of the study cohort.
We have successfully validated an algorithm that can identify a high EHR data-continuity cohort representative of the source population.
电子健康记录(EHR)数据不连续性,即患者在特定EHR系统之外接受治疗,可能导致研究变量的错误分类。我们旨在验证一种算法,以识别具有高EHR数据连续性的患者,从而减少此类偏差。
我们分析了两个与2007年至2014年医疗保险索赔数据相关联的EHR系统的数据,一个在马萨诸塞州(MA,n = 80,588),另一个在北卡罗来纳州(NC,n = 33,207)。与索赔数据中的完整记录相比,我们通过EHR系统的捕获就诊平均比例(MPEC)来量化EHR数据连续性。MPEC的预测模型在MA开发,并在NC进行验证。根据预测的EHR数据连续性进行分层,我们通过仅基于EHR的这些变量比例与关联的索赔-EHR数据之间的平均标准化差异(MSD)来量化40个关键变量的错误分类。
MA系统的平均MPEC为27%,NC系统为26%。预测的和观察到的EHR数据连续性高度相关(Spearman相关性分别为0.78和0.73)。预测的EHR数据连续性队列患者中40个变量的错误分类(MSD)明显小于其余人群(44%,95%CI:40 - 48%)。
EHR数据连续性高与低的患者合并症情况相似。因此,将分析限制在EHR数据连续性高的患者中,可能会减少信息偏差,同时保持研究队列的代表性。
我们成功验证了一种算法,该算法可以识别代表源人群的高EHR数据连续性队列。