Department of Medicine, Massachusetts General Hospital, Boston, MA 02114, United States.
Department of Medicine, Harvard Medical School, Boston, MA 02115, United States.
J Am Med Inform Assoc. 2023 Nov 17;30(12):1985-1994. doi: 10.1093/jamia/ocad166.
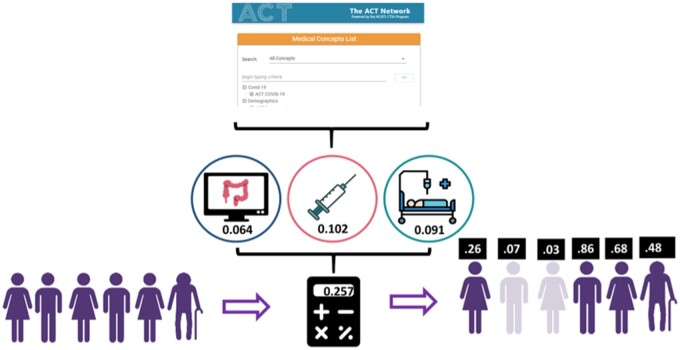
Patients who receive most care within a single healthcare system (colloquially called a "loyalty cohort" since they typically return to the same providers) have mostly complete data within that organization's electronic health record (EHR). Loyalty cohorts have low data missingness, which can unintentionally bias research results. Using proxies of routine care and healthcare utilization metrics, we compute a per-patient score that identifies a loyalty cohort.
We implemented a computable program for the widely adopted i2b2 platform that identifies loyalty cohorts in EHRs based on a machine-learning model, which was previously validated using linked claims data. We developed a novel validation approach, which tests, using only EHR data, whether patients returned to the same healthcare system after the training period. We evaluated these tools at 3 institutions using data from 2017 to 2019.
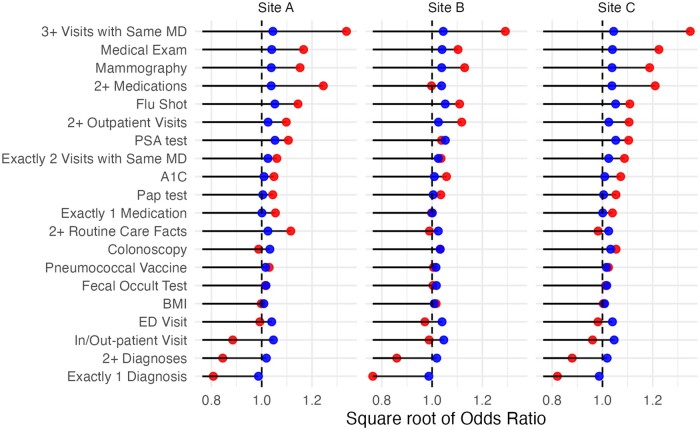
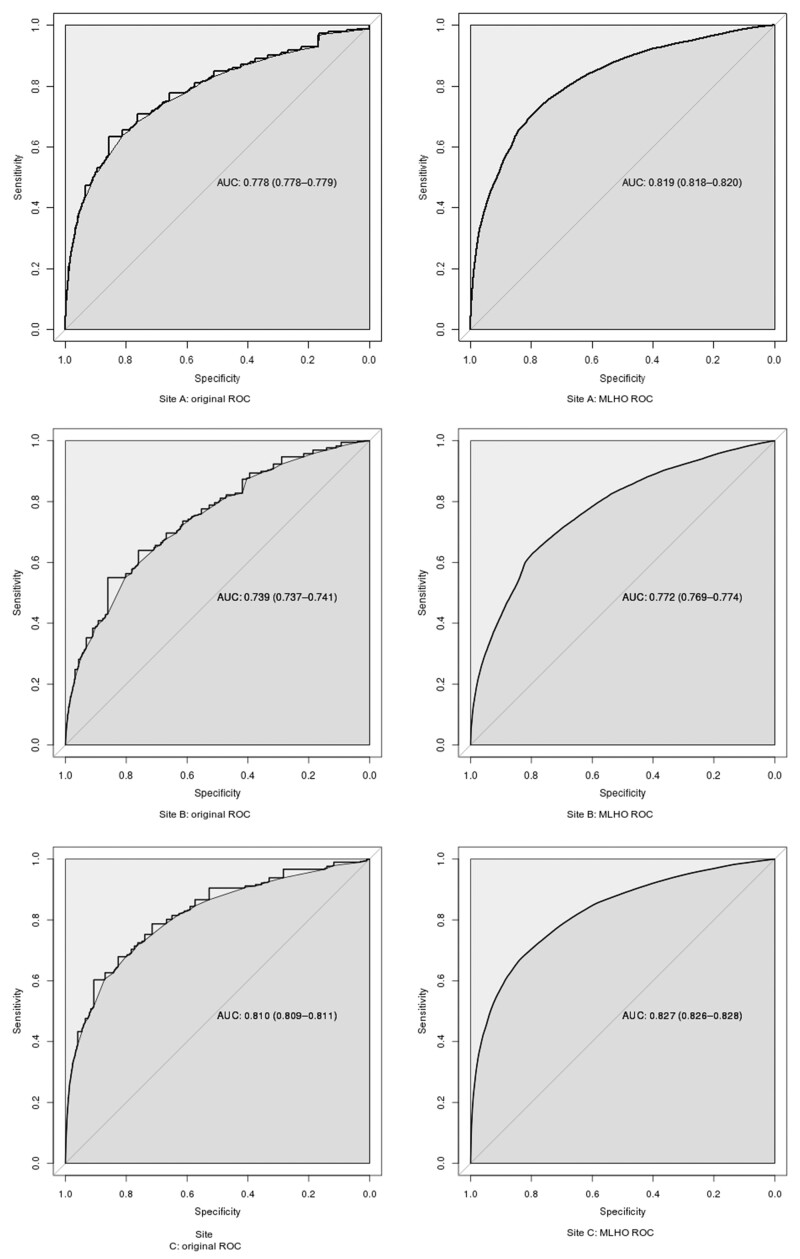
Loyalty cohort calculations to identify patients who returned during a 1-year follow-up yielded a mean area under the receiver operating characteristic curve of 0.77 using the original model and 0.80 after calibrating the model at individual sites. Factors such as multiple medications or visits contributed significantly at all sites. Screening tests' contributions (eg, colonoscopy) varied across sites, likely due to coding and population differences.
This open-source implementation of a "loyalty score" algorithm had good predictive power. Enriching research cohorts by utilizing these low-missingness patients is a way to obtain the data completeness necessary for accurate causal analysis.
i2b2 sites can use this approach to select cohorts with mostly complete EHR data.
在单一医疗保健系统中接受大部分护理的患者(由于他们通常返回同一医疗服务提供者,因此俗称“忠诚队列”)在该组织的电子健康记录(EHR)中拥有大部分完整的数据。忠诚队列的数据缺失率较低,这可能会无意中影响研究结果。使用常规护理和医疗保健利用指标的代理,我们计算出每个患者的分数,以确定忠诚队列。
我们在广泛采用的 i2b2 平台上实现了一个可计算的程序,该程序根据先前使用链接索赔数据验证的机器学习模型,在 EHR 中识别忠诚队列。我们开发了一种新颖的验证方法,该方法仅使用 EHR 数据测试患者在培训期后是否返回同一医疗保健系统。我们在 3 家机构中使用 2017 年至 2019 年的数据评估了这些工具。
使用原始模型,忠诚度队列计算以识别在 1 年随访期间返回的患者,其受试者工作特征曲线下的平均面积为 0.77,在单个站点校准模型后为 0.80。所有站点的多种药物或就诊等因素都有重要贡献。筛选测试的贡献(例如结肠镜检查)因站点而异,可能是由于编码和人群差异所致。
这种“忠诚度评分”算法的开源实现具有良好的预测能力。通过利用这些低缺失率患者丰富研究队列,可以获得进行准确因果分析所需的完整数据。
i2b2 站点可以使用此方法选择具有大部分完整 EHR 数据的队列。