Liu Zhichang, Deng Dun, Lu Huijie, Sun Jian, Lv Luchao, Li Shuhong, Peng Guanghui, Ma Xianyong, Li Jiazhou, Li Zhenming, Rong Ting, Wang Gang
Institute of Animal Science, Guangdong Academy of Agricultural Sciences, Guangzhou, China.
State Key Laboratory of Livestock and Poultry Breeding, Guangzhou, China.
Front Microbiol. 2020 Feb 6;11:48. doi: 10.3389/fmicb.2020.00048. eCollection 2020.
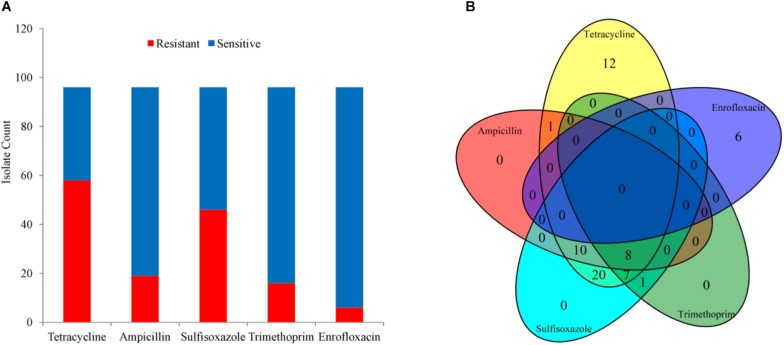
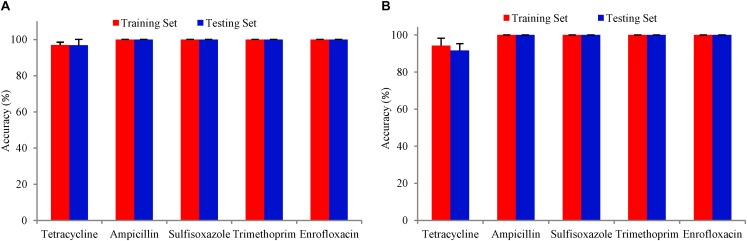
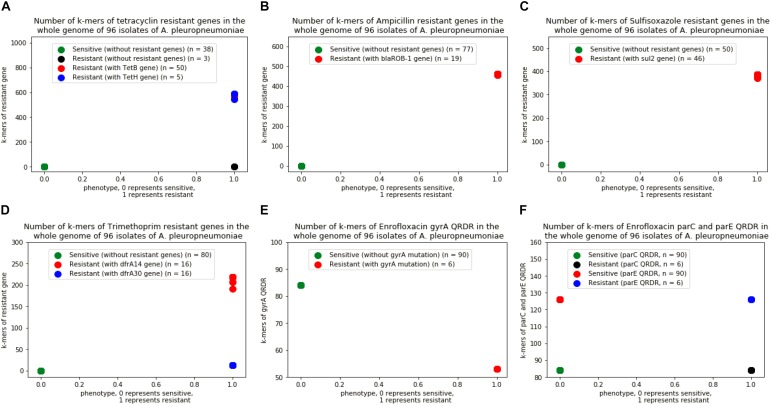
Antimicrobial resistance (AMR) is becoming a huge problem in countries all over the world, and new approaches to identifying strains resistant or susceptible to certain antibiotics are essential in fighting against antibiotic-resistant pathogens. Genotype-based machine learning methods showed great promise as a diagnostic tool, due to the increasing availability of genomic datasets and AST phenotypes. In this article, Support Vector Machine (SVM) and Set Covering Machine (SCM) models were used to learn and predict the resistance of the five drugs (Tetracycline, Ampicillin, Sulfisoxazole, Trimethoprim, and Enrofloxacin). The SVM model used the number of co-occurring k-mers between the genome of the isolates and the reference genes to learn and predict the phenotypes of the bacteria to a specific antimicrobial, while the SCM model uses a greedy approach to construct conjunction or disjunction of Boolean functions to find the most concise set of k-mers that allows for accurate prediction of the phenotype. Five-fold cross-validation was performed on the training set of the SVM and SCM model to select the best hyperparameter values to avoid model overfitting. The training accuracy (mean cross-validation score) and the testing accuracy of SVM and SCM models of five drugs were above 90% regardless of the resistant mechanism of which were acquired resistant or point mutation in the chromosome. The results of correlation between the phenotype and the model predictions of the five drugs indicated that both SVM and SCM models could significantly classify the resistant isolates from the sensitive isolates of the bacteria ( < 0.01), and would be used as potential tools in antimicrobial resistance surveillance and clinical diagnosis in veterinary medicine.
抗菌药物耐药性(AMR)在世界各国正成为一个巨大问题,而识别对某些抗生素耐药或敏感菌株的新方法对于对抗耐药病原体至关重要。基于基因型的机器学习方法由于基因组数据集和抗菌药物敏感性试验(AST)表型的可用性不断增加,显示出作为诊断工具的巨大潜力。在本文中,支持向量机(SVM)和集合覆盖机(SCM)模型被用于学习和预测五种药物(四环素、氨苄青霉素、磺胺异恶唑、甲氧苄啶和恩诺沙星)的耐药性。SVM模型利用分离株基因组与参考基因之间共现k-mer的数量来学习和预测细菌对特定抗菌药物的表型,而SCM模型采用贪心方法构建布尔函数的合取或析取,以找到能够准确预测表型的最简洁k-mer集合。对SVM和SCM模型的训练集进行五折交叉验证,以选择最佳超参数值,避免模型过拟合。无论耐药机制是获得性耐药还是染色体上的点突变,五种药物的SVM和SCM模型的训练准确率(平均交叉验证分数)和测试准确率均高于90%。五种药物的表型与模型预测之间的相关性结果表明,SVM和SCM模型均可显著区分细菌的耐药分离株和敏感分离株(<0.01),并将作为兽医学抗菌药物耐药性监测和临床诊断的潜在工具。