Ive Julia, Viani Natalia, Kam Joyce, Yin Lucia, Verma Somain, Puntis Stephen, Cardinal Rudolf N, Roberts Angus, Stewart Robert, Velupillai Sumithra
1Department of Computing, Imperial College London, London, SW7 2AZ UK.
2IoPPN, King's College London, SE5 8AF London, UK.
NPJ Digit Med. 2020 May 14;3:69. doi: 10.1038/s41746-020-0267-x. eCollection 2020.
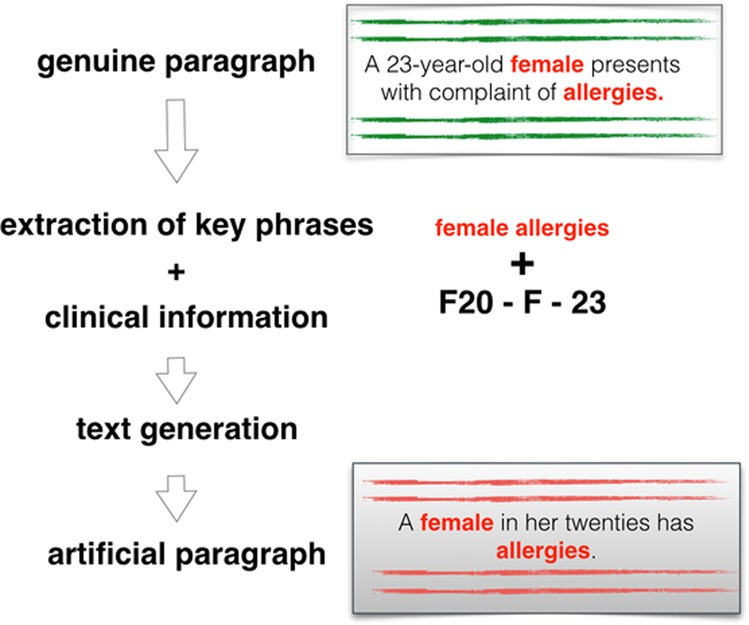
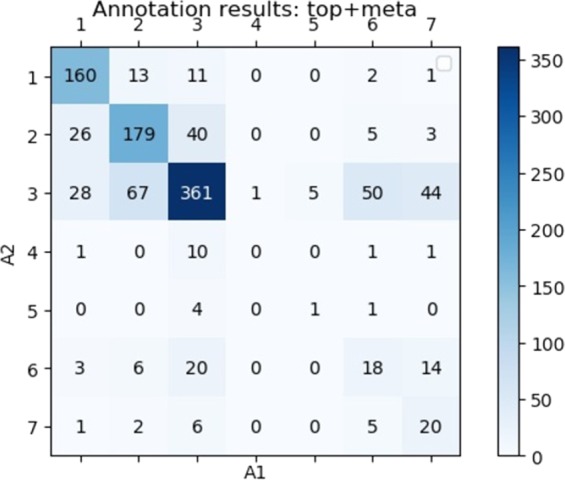
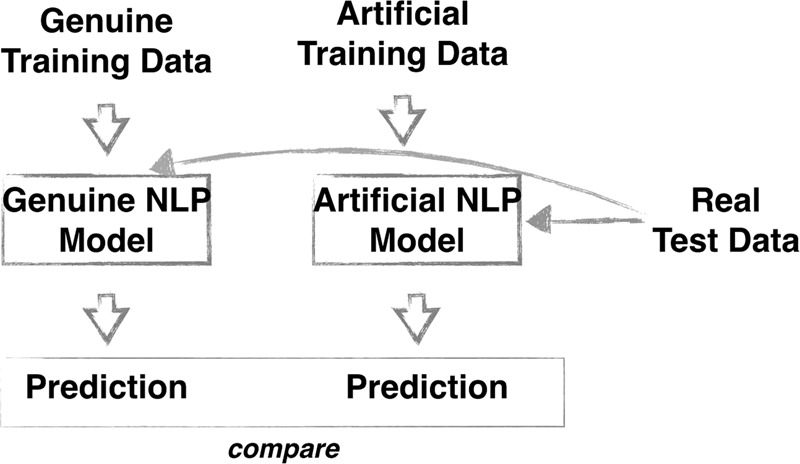
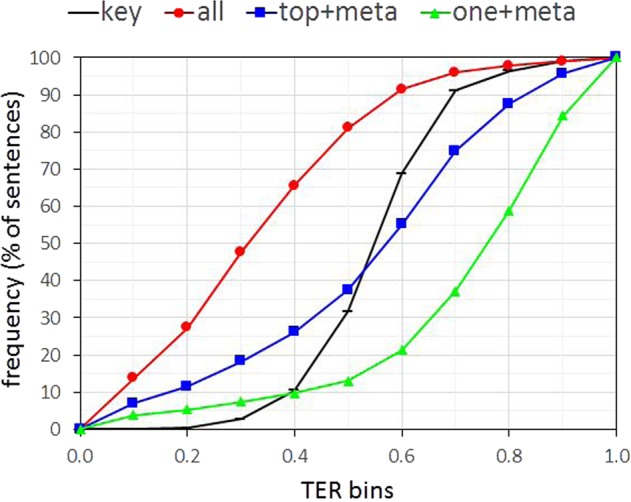
A serious obstacle to the development of Natural Language Processing (NLP) methods in the clinical domain is the accessibility of textual data. The mental health domain is particularly challenging, partly because clinical documentation relies heavily on free text that is difficult to de-identify completely. This problem could be tackled by using artificial medical data. In this work, we present an approach to generate artificial clinical documents. We apply this approach to discharge summaries from a large mental healthcare provider and discharge summaries from an intensive care unit. We perform an extensive intrinsic evaluation where we (1) apply several measures of text preservation; (2) measure how much the model memorises training data; and (3) estimate clinical validity of the generated text based on a human evaluation task. Furthermore, we perform an extrinsic evaluation by studying the impact of using artificial text in a downstream NLP text classification task. We found that using this artificial data as training data can lead to classification results that are comparable to the original results. Additionally, using only a small amount of information from the original data to condition the generation of the artificial data is successful, which holds promise for reducing the risk of these artificial data retaining rare information from the original data. This is an important finding for our long-term goal of being able to generate artificial clinical data that can be released to the wider research community and accelerate advances in developing computational methods that use healthcare data.
临床领域中自然语言处理(NLP)方法发展的一个严重障碍是文本数据的可获取性。心理健康领域尤其具有挑战性,部分原因是临床文档严重依赖难以完全去识别的自由文本。这个问题可以通过使用人工医疗数据来解决。在这项工作中,我们提出了一种生成人工临床文档的方法。我们将此方法应用于一家大型心理健康护理机构的出院小结以及重症监护病房的出院小结。我们进行了广泛的内在评估,其中我们:(1)应用多种文本保留度量;(2)测量模型对训练数据的记忆程度;(3)基于一项人工评估任务估计生成文本的临床有效性。此外,我们通过研究在下游NLP文本分类任务中使用人工文本的影响来进行外在评估。我们发现,将这些人工数据用作训练数据可得出与原始结果相当的分类结果。此外,仅使用原始数据中的少量信息来调整人工数据的生成是成功的,这有望降低这些人工数据保留原始数据中稀有信息的风险。对于我们能够生成可发布给更广泛研究群体的人工临床数据,并加速使用医疗保健数据的计算方法发展这一长期目标而言,这是一项重要发现。