From the Department of Biostatistics and Epidemiology, School of Public Health and Health Sciences, University of Massachusetts, Amherst, MA.
Kenya Medical Research Institute, Center for Microbiology Research, Nairobi, Kenya.
Epidemiology. 2020 Sep;31(5):620-627. doi: 10.1097/EDE.0000000000001215.
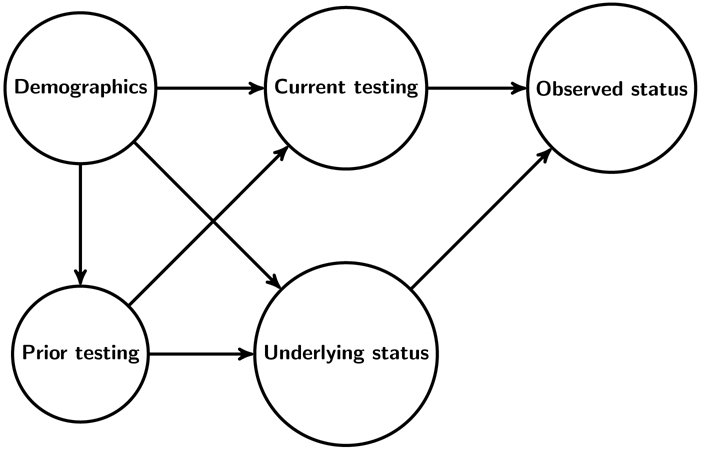
Population-level estimates of disease prevalence and control are needed to assess prevention and treatment strategies. However, available data often suffer from differential missingness. For example, population-level HIV viral suppression is the proportion of all HIV-positive persons with suppressed viral replication. Individuals with measured HIV status, and among HIV-positive individuals those with measured viral suppression, likely differ from those without such measurements.
We discuss three sets of assumptions to identify population-level suppression in the intervention arm of the SEARCH Study (NCT01864603), a community randomized trial in rural Kenya and Uganda (2013-2017). Using data on nearly 100,000 participants, we compare estimates from (1) an unadjusted approach assuming data are missing-completely-at-random (MCAR); (2) stratification on age group, sex, and community; and (3) targeted maximum likelihood estimation to adjust for a larger set of baseline and time-updated variables.
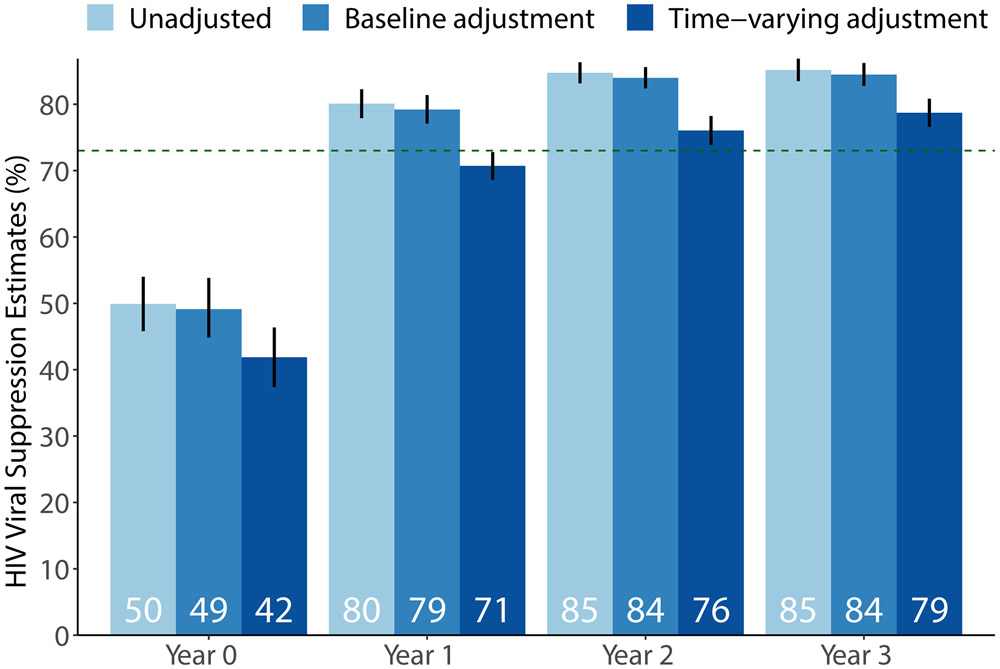
Despite high measurement coverage, estimates of population-level viral suppression varied by identification assumption. Unadjusted estimates were most optimistic: 50% (95% confidence interval [CI] = 46%, 54%) of HIV-positive persons suppressed at baseline, 80% (95% CI = 78%, 82%) at year 1, 85% (95% CI = 83%, 86%) at year 2, and 85% (95% CI = 83%, 87%) at year 3. Stratifying on baseline predictors yielded slightly lower estimates, and full adjustment reduced estimates meaningfully: 42% (95% CI = 37%, 46%) of HIV-positive persons suppressed at baseline, 71% (95% CI = 69%, 73%) at year 1, 76% (95% CI = 74%, 78%) at year 2, and 79% (95% CI = 77%, 81%) at year 3.
Estimation of population-level disease burden and control requires appropriate adjustment for missing data. Even in large studies with limited missingness, estimates relying on the MCAR assumption or baseline stratification should be interpreted cautiously.
为了评估预防和治疗策略,需要对疾病的流行率和控制进行人群水平的估计。然而,现有的数据往往存在差异缺失。例如,人群水平的 HIV 病毒抑制是所有 HIV 阳性者中病毒复制得到抑制的比例。有测量 HIV 状态的个体,以及 HIV 阳性者中有测量到病毒抑制的个体,可能与没有这些测量的个体不同。
我们讨论了 SEARCH 研究(NCT01864603)干预组中识别人群水平抑制的三组假设,这是一项在肯尼亚和乌干达农村地区进行的社区随机试验(2013-2017 年)。使用近 100,000 名参与者的数据,我们比较了(1)未调整的方法,假设数据是完全随机缺失(MCAR);(2)按年龄组、性别和社区分层;以及(3)靶向最大似然估计,以调整更大的一组基线和时间更新变量。
尽管测量覆盖率很高,但人群水平病毒抑制的估计值因识别假设而异。未调整的估计值最乐观:基线时,50%(95%置信区间 [CI] = 46%,54%)的 HIV 阳性者得到抑制,第 1 年时 80%(95% CI = 78%,82%),第 2 年时 85%(95% CI = 83%,86%),第 3 年时 85%(95% CI = 83%,87%)。按基线预测因子分层会得出略低的估计值,而完全调整会显著降低估计值:基线时,42%(95% CI = 37%,46%)的 HIV 阳性者得到抑制,第 1 年时 71%(95% CI = 69%,73%),第 2 年时 76%(95% CI = 74%,78%),第 3 年时 79%(95% CI = 77%,81%)。
疾病负担和控制的人群水平估计需要对缺失数据进行适当调整。即使在缺失率有限的大型研究中,也应谨慎解释依赖 MCAR 假设或基线分层的估计值。