Horne Elsie, Tibble Holly, Sheikh Aziz, Tsanas Athanasios
Usher Institute, Edinburgh Medical School, University of Edinburgh, Edinburgh, United Kingdom.
JMIR Med Inform. 2020 May 28;8(5):e16452. doi: 10.2196/16452.
In the current era of personalized medicine, there is increasing interest in understanding the heterogeneity in disease populations. Cluster analysis is a method commonly used to identify subtypes in heterogeneous disease populations. The clinical data used in such applications are typically multimodal, which can make the application of traditional cluster analysis methods challenging.
This study aimed to review the research literature on the application of clustering multimodal clinical data to identify asthma subtypes. We assessed common problems and shortcomings in the application of cluster analysis methods in determining asthma subtypes, such that they can be brought to the attention of the research community and avoided in future studies.
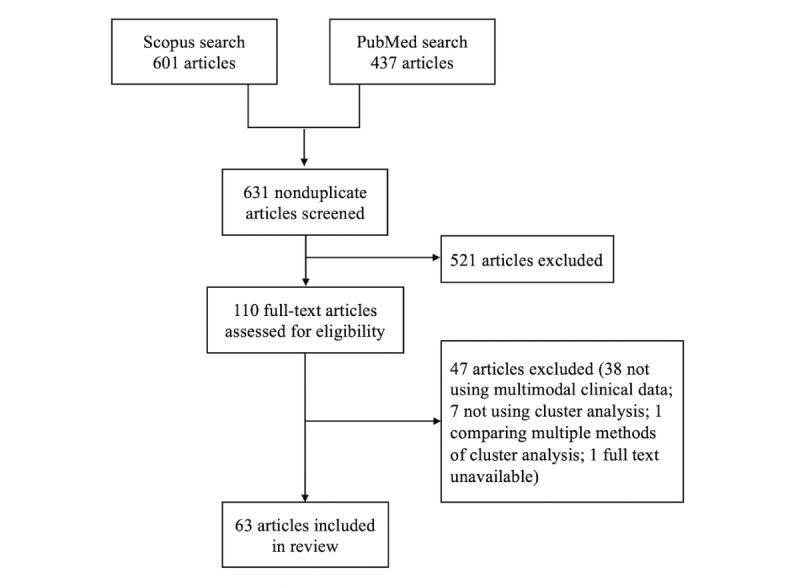
We searched PubMed and Scopus bibliographic databases with terms related to cluster analysis and asthma to identify studies that applied dissimilarity-based cluster analysis methods. We recorded the analytic methods used in each study at each step of the cluster analysis process.
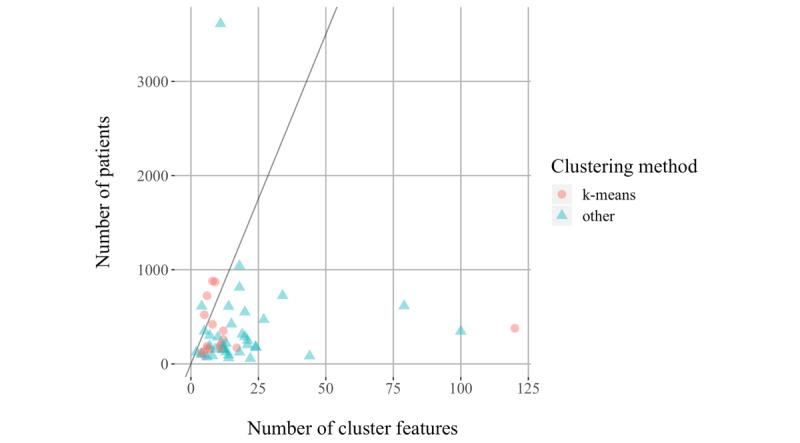
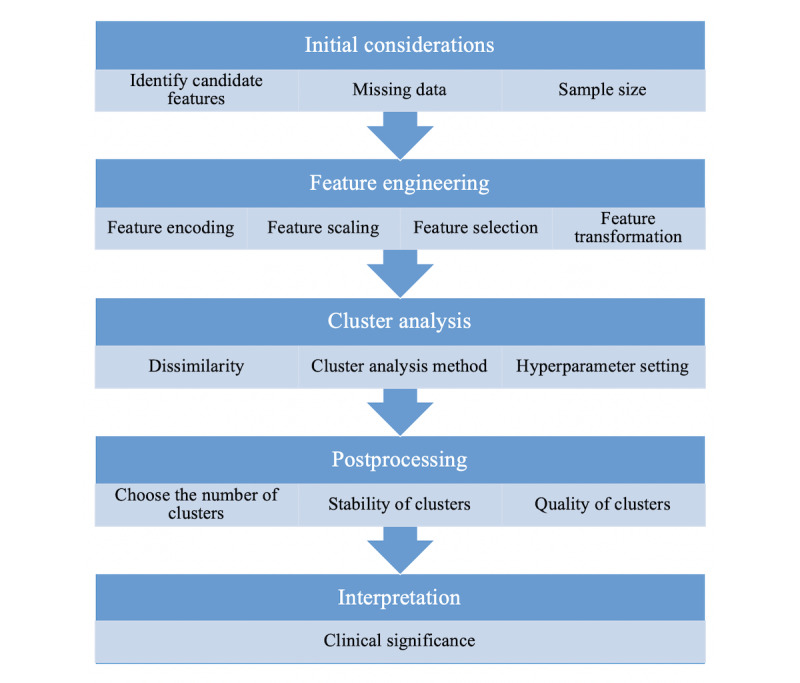
Our literature search identified 63 studies that applied cluster analysis to multimodal clinical data to identify asthma subtypes. The features fed into the cluster algorithms were of a mixed type in 47 (75%) studies and continuous in 12 (19%), and the feature type was unclear in the remaining 4 (6%) studies. A total of 23 (37%) studies used hierarchical clustering with Ward linkage, and 22 (35%) studies used k-means clustering. Of these 45 studies, 39 had mixed-type features, but only 5 specified dissimilarity measures that could handle mixed-type features. A further 9 (14%) studies used a preclustering step to create small clusters to feed on a hierarchical method. The original sample sizes in these 9 studies ranged from 84 to 349. The remaining studies used hierarchical clustering with other linkages (n=3), medoid-based methods (n=3), spectral clustering (n=1), and multiple kernel k-means clustering (n=1), and in 1 study, the methods were unclear. Of 63 studies, 54 (86%) explained the methods used to determine the number of clusters, 24 (38%) studies tested the quality of their cluster solution, and 11 (17%) studies tested the stability of their solution. Reporting of the cluster analysis was generally poor in terms of the methods employed and their justification.
This review highlights common issues in the application of cluster analysis to multimodal clinical data to identify asthma subtypes. Some of these issues were related to the multimodal nature of the data, but many were more general issues in the application of cluster analysis. Although cluster analysis may be a useful tool for investigating disease subtypes, we recommend that future studies carefully consider the implications of clustering multimodal data, the cluster analysis process itself, and the reporting of methods to facilitate replication and interpretation of findings.
在当前个性化医疗时代,人们越来越关注疾病群体中的异质性。聚类分析是一种常用于识别异质性疾病群体中不同亚型的方法。此类应用中使用的临床数据通常是多模态的,这可能会使传统聚类分析方法的应用具有挑战性。
本研究旨在回顾关于应用聚类多模态临床数据来识别哮喘亚型的研究文献。我们评估了聚类分析方法在确定哮喘亚型应用中的常见问题和不足,以便引起研究界的关注并在未来研究中避免。
我们在PubMed和Scopus文献数据库中搜索与聚类分析和哮喘相关的术语,以识别应用基于差异的聚类分析方法的研究。我们记录了聚类分析过程每个步骤中每项研究使用的分析方法。
我们的文献检索确定了63项将聚类分析应用于多模态临床数据以识别哮喘亚型的研究。输入聚类算法的特征在47项(75%)研究中为混合类型,在12项(19%)研究中为连续类型,其余4项(6%)研究的特征类型不明确。共有23项(37%)研究使用了Ward链接的层次聚类,22项(35%)研究使用了k均值聚类。在这45项研究中,39项具有混合类型特征,但只有5项指定了可处理混合类型特征的差异度量。另外9项(14%)研究使用了预聚类步骤来创建小聚类以供层次方法使用。这9项研究中的原始样本量从84到349不等。其余研究使用了其他链接的层次聚类(n = 3)、基于中心点的方法(n = 3)、谱聚类(n = 1)和多核k均值聚类(n = 1),在1项研究中,方法不明确。在63项研究中,54项(86%)解释了用于确定聚类数量的方法,24项(38%)研究测试了其聚类解决方案的质量,11项(17%)研究测试了其解决方案的稳定性。就所采用的方法及其合理性而言,聚类分析的报告总体较差。
本综述强调了在应用聚类分析于多模态临床数据以识别哮喘亚型方面的常见问题。其中一些问题与数据的多模态性质有关,但许多是聚类分析应用中更普遍的问题。尽管聚类分析可能是研究疾病亚型的有用工具,但我们建议未来的研究仔细考虑聚类多模态数据的影响、聚类分析过程本身以及方法的报告,以促进研究结果的复制和解释。