Hoogland Jeroen, van Barreveld Marit, Debray Thomas P A, Reitsma Johannes B, Verstraelen Tom E, Dijkgraaf Marcel G W, Zwinderman Aeilko H
Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht University, Utrecht, The Netherlands.
Department of Clinical Epidemiology, Biostatistics, & Bioinformatics, Academic Medical Center, Amsterdam University Medical Centers, Amsterdam, The Netherlands.
Stat Med. 2020 Nov 10;39(25):3591-3607. doi: 10.1002/sim.8682. Epub 2020 Jul 20.
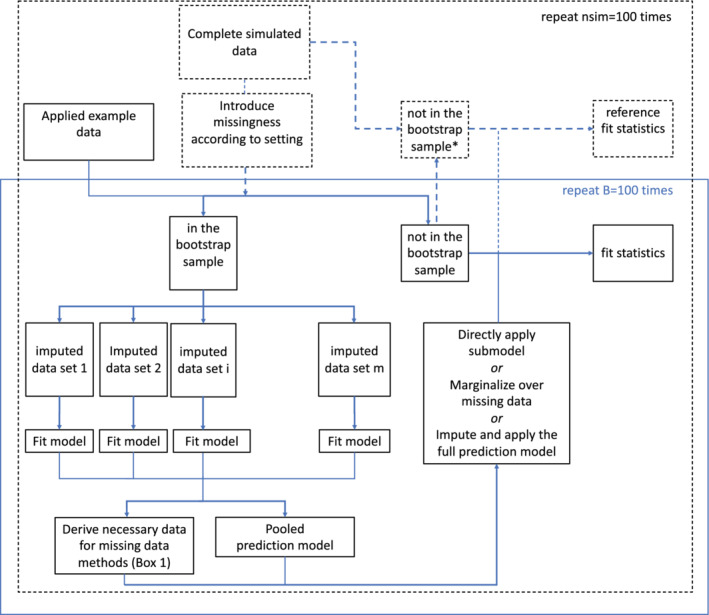
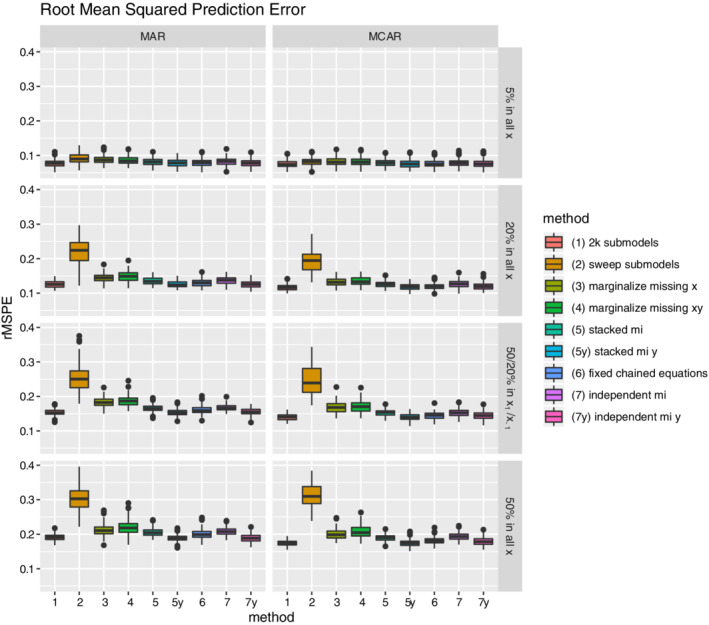
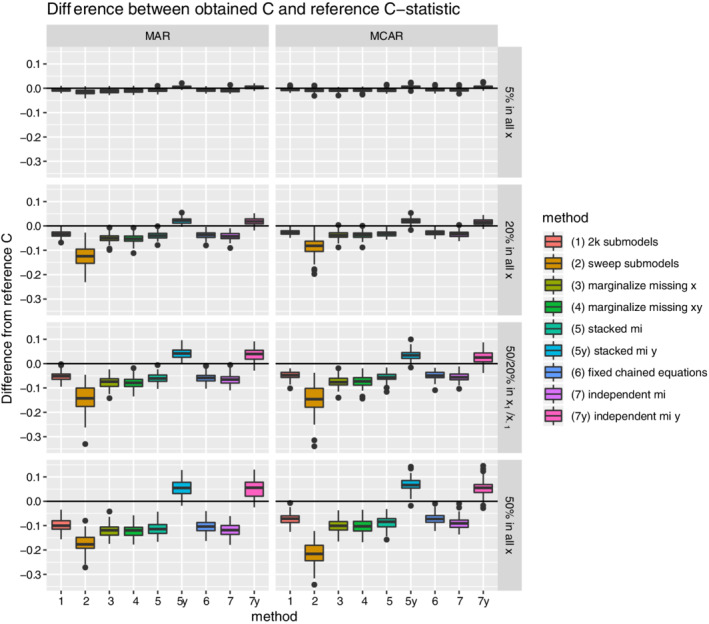
Missing data present challenges for development and real-world application of clinical prediction models. While these challenges have received considerable attention in the development setting, there is only sparse research on the handling of missing data in applied settings. The main unique feature of handling missing data in these settings is that missing data methods have to be performed for a single new individual, precluding direct application of mainstay methods used during model development. Correspondingly, we propose that it is desirable to perform model validation using missing data methods that transfer to practice in single new patients. This article compares existing and new methods to account for missing data for a new individual in the context of prediction. These methods are based on (i) submodels based on observed data only, (ii) marginalization over the missing variables, or (iii) imputation based on fully conditional specification (also known as chained equations). They were compared in an internal validation setting to highlight the use of missing data methods that transfer to practice while validating a model. As a reference, they were compared to the use of multiple imputation by chained equations in a set of test patients, because this has been used in validation studies in the past. The methods were evaluated in a simulation study where performance was measured by means of optimism corrected C-statistic and mean squared prediction error. Furthermore, they were applied in data from a large Dutch cohort of prophylactic implantable cardioverter defibrillator patients.
缺失数据给临床预测模型的开发和实际应用带来了挑战。虽然这些挑战在开发环境中已受到相当多的关注,但在应用环境中处理缺失数据的研究却很少。在这些环境中处理缺失数据的主要独特之处在于,缺失数据方法必须针对单个新个体执行,这排除了直接应用模型开发期间使用的主要方法。相应地,我们建议使用能够应用于单个新患者实际情况的缺失数据方法来进行模型验证。本文比较了在预测背景下针对新个体处理缺失数据的现有方法和新方法。这些方法基于:(i)仅基于观测数据的子模型;(ii)对缺失变量进行边缘化;或(iii)基于完全条件设定的插补(也称为链式方程)。在内部验证环境中对它们进行了比较,以突出在验证模型时能够应用于实际情况的缺失数据方法的使用。作为参考,在一组测试患者中将它们与使用链式方程进行多次插补的情况进行了比较,因为过去在验证研究中曾使用过这种方法。在一项模拟研究中对这些方法进行了评估,通过乐观校正C统计量和均方预测误差来衡量性能。此外,它们还应用于来自荷兰一个大型预防性植入式心脏复律除颤器患者队列的数据。