University of Aberdeen, Aberdeen, UK.
KTH-The Royal Institute of Technology, Stockholm, Sweden.
BMC Bioinformatics. 2020 Jul 29;21(1):336. doi: 10.1186/s12859-020-03659-3.
Machine learning models for repeated measurements are limited. Using topological data analysis (TDA), we present a classifier for repeated measurements which samples from the data space and builds a network graph based on the data topology. A machine learning model with cross-validation is then applied for classification. When test this on three case studies, accuracy exceeds an alternative support vector machine (SVM) voting model in most situations tested, with additional benefits such as reporting data subsets with high purity along with feature values.
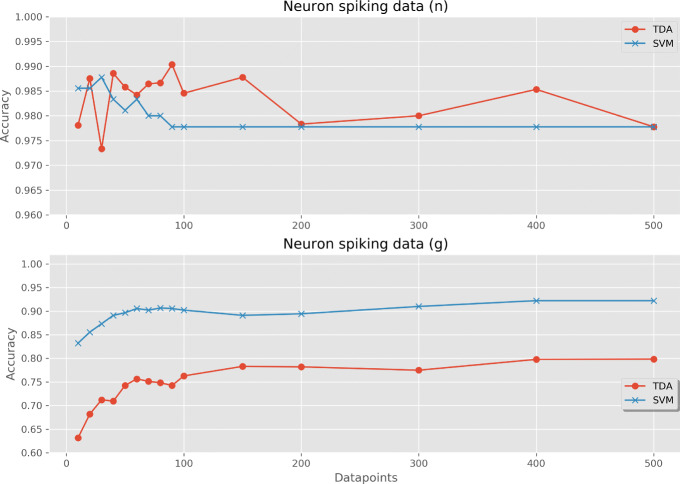
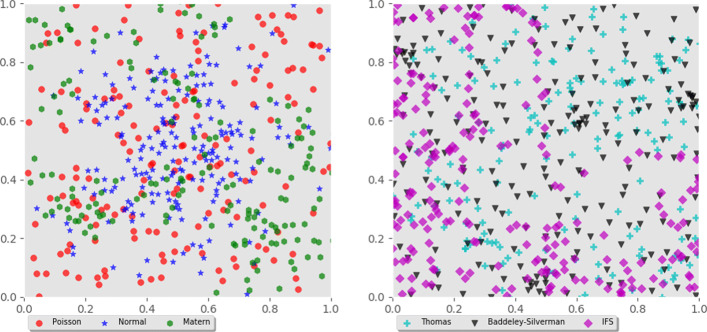
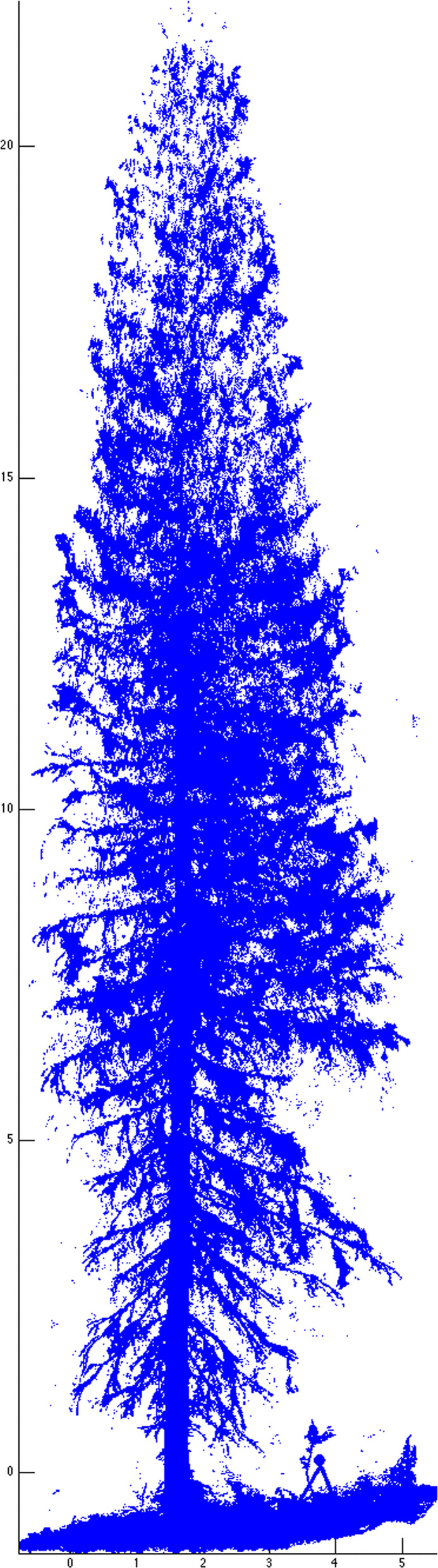
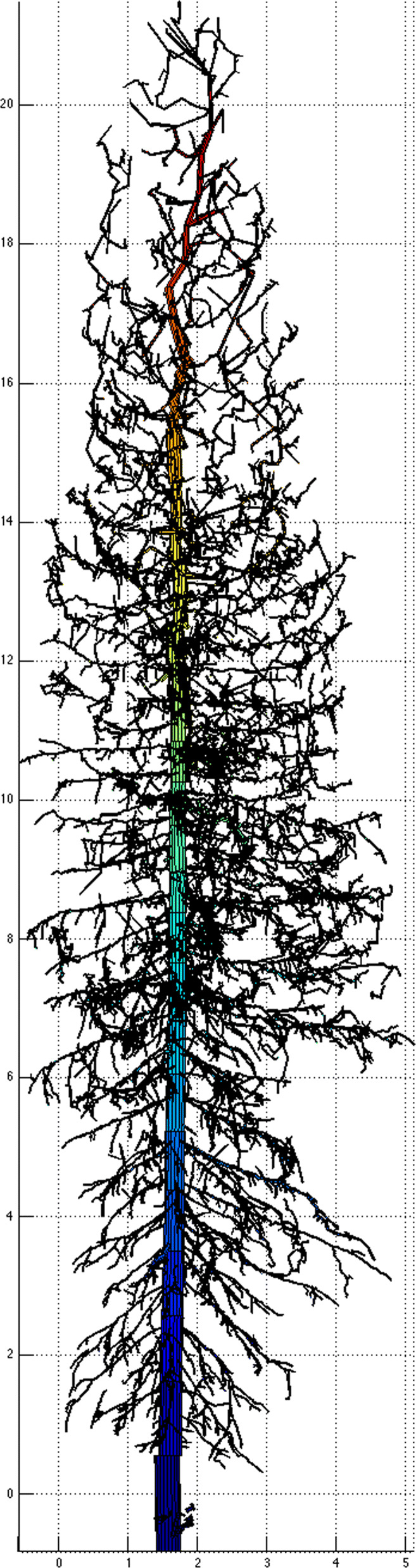
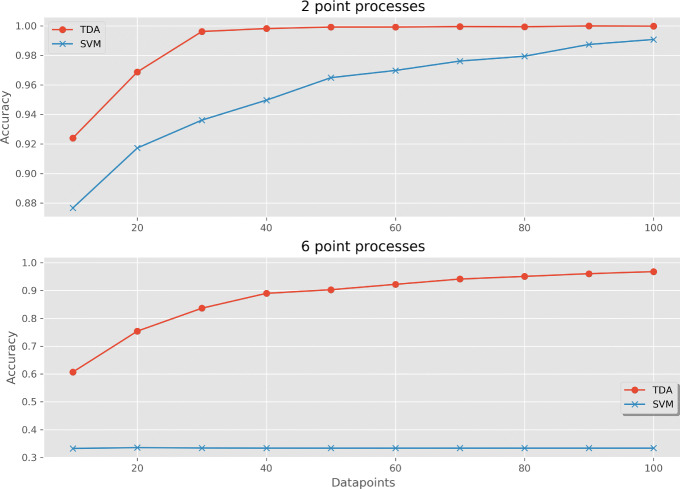
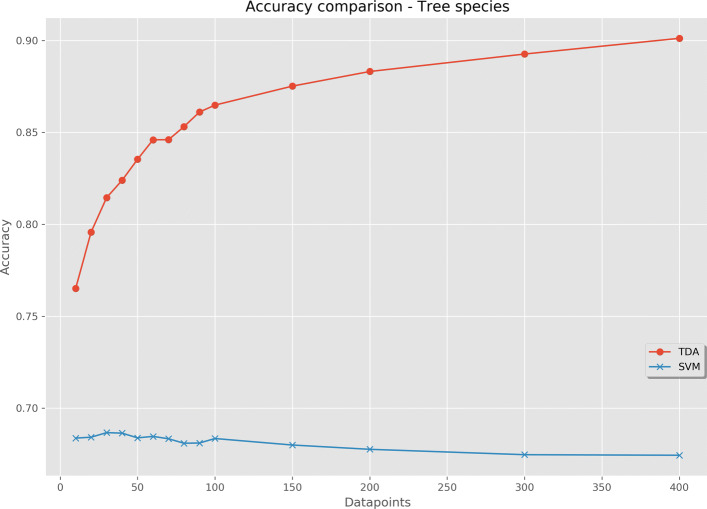
For 100 examples of 3 different tree species, the model reached 80% classification accuracy after 30 datapoints, which was improved to 90% after increased sampling to 400 datapoints. The alternative SVM classifier achieved a maximum accuracy of 68.7%. Using data from 100 examples from each class of 6 different random point processes, the classifier achieved 96.8% accuracy, vastly outperforming the SVM. Using two outcomes in neuron spiking data, the TDA classifier was similarly accurate to the SVM in one case (both converged to 97.8% accuracy), but was outperformed in the other (relative accuracies 79.8% and 92.2%, respectively).
This algorithm and software can be beneficial for repeated measurement data common in biological sciences, as both an accurate classifier and a feature selection tool.
用于重复测量的机器学习模型有限。我们使用拓扑数据分析(TDA),提出了一种从数据空间中采样并基于数据拓扑构建网络图的重复测量分类器。然后应用具有交叉验证的机器学习模型进行分类。在三个案例研究中进行测试时,在大多数测试情况下,准确性超过了替代的支持向量机(SVM)投票模型,并且具有额外的优势,例如报告具有高纯度的数据子集以及特征值。
对于 3 个不同树种的 100 个示例,在 30 个数据点后,该模型达到了 80%的分类准确性,在增加到 400 个数据点的采样后,准确性提高到了 90%。替代的 SVM 分类器的最大准确性达到了 68.7%。使用来自 6 种不同随机点过程的每个类别的 100 个示例的数据,分类器的准确性达到了 96.8%,大大优于 SVM。对于神经元尖峰数据的两个结果,在一种情况下,TDA 分类器与 SVM 的准确性相同(都收敛到 97.8%的准确性),但在另一种情况下表现更好(相对准确性分别为 79.8%和 92.2%)。
该算法和软件可用于生物学中常见的重复测量数据,既是一种准确的分类器,也是一种特征选择工具。