Korean Genomics Center (KOGIC), Ulsan National Institute of Science and Technology (UNIST), Ulsan 44919, Republic of Korea.
Department of Biomedical Engineering, School of Life Sciences, UNIST, Ulsan 44919, Republic of Korea.
Sci Adv. 2020 May 27;6(22):eaaz7835. doi: 10.1126/sciadv.aaz7835. eCollection 2020 May.
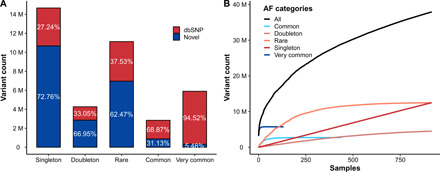
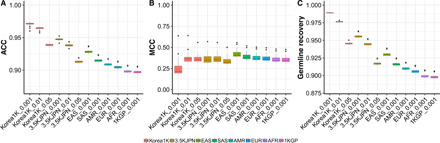
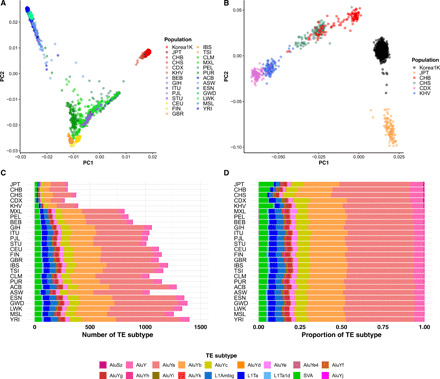
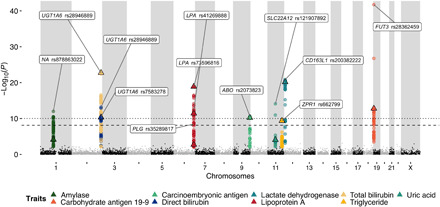
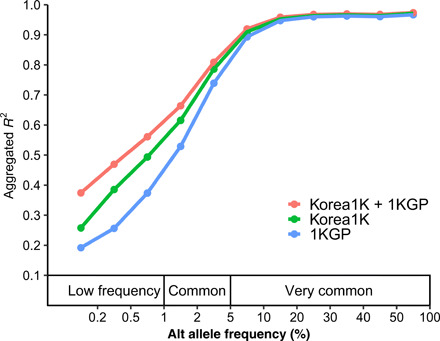
We present the initial phase of the Korean Genome Project (Korea1K), including 1094 whole genomes (sequenced at an average depth of 31×), along with data of 79 quantitative clinical traits. We identified 39 million single-nucleotide variants and indels of which half were singleton or doubleton and detected Korean-specific patterns based on several types of genomic variations. A genome-wide association study illustrated the power of whole-genome sequences for analyzing clinical traits, identifying nine more significant candidate alleles than previously reported from the same linkage disequilibrium blocks. Also, Korea1K, as a reference, showed better imputation accuracy for Koreans than the 1KGP panel. As proof of utility, germline variants in cancer samples could be filtered out more effectively when the Korea1K variome was used as a panel of normals compared to non-Korean variome sets. Overall, this study shows that Korea1K can be a useful genotypic and phenotypic resource for clinical and ethnogenetic studies.
我们呈现了韩国基因组计划(Korea1K)的初始阶段,包括 1094 个全基因组(平均测序深度为 31×),以及 79 项定量临床特征数据。我们鉴定了 3900 万个单核苷酸变异和插入缺失,其中一半是单倍体或双倍体,并基于几种类型的基因组变异检测到了韩国特有的模式。全基因组关联研究说明了全基因组序列在分析临床特征方面的强大功能,鉴定出了比以前在相同连锁不平衡块中报道的 9 个更显著的候选等位基因。此外,Korea1K 作为参考,对韩国人的基因分型准确性优于 1KGP 面板。作为实用性的证明,与非韩国变体组相比,当将 Korea1K 变体组用作正常人群面板时,癌症样本中的种系变体可以更有效地被过滤掉。总体而言,这项研究表明 Korea1K 可以成为临床和种族研究的有用的基因型和表型资源。