Gagalova Kristina K, Leon Elizalde M Angelica, Portales-Casamar Elodie, Görges Matthias
Canada's Michael Smith Genome Sciences Centre, BC Cancer, Vancouver, BC, Canada.
Bioinformatics Graduate Program, University of British Columbia, Vancouver, BC, Canada.
JMIR Form Res. 2020 Aug 27;4(8):e17687. doi: 10.2196/17687.
Integrated data repositories (IDRs), also referred to as clinical data warehouses, are platforms used for the integration of several data sources through specialized analytical tools that facilitate data processing and analysis. IDRs offer several opportunities for clinical data reuse, and the number of institutions implementing an IDR has grown steadily in the past decade.
The architectural choices of major IDRs are highly diverse and determining their differences can be overwhelming. This review aims to explore the underlying models and common features of IDRs, provide a high-level overview for those entering the field, and propose a set of guiding principles for small- to medium-sized health institutions embarking on IDR implementation.
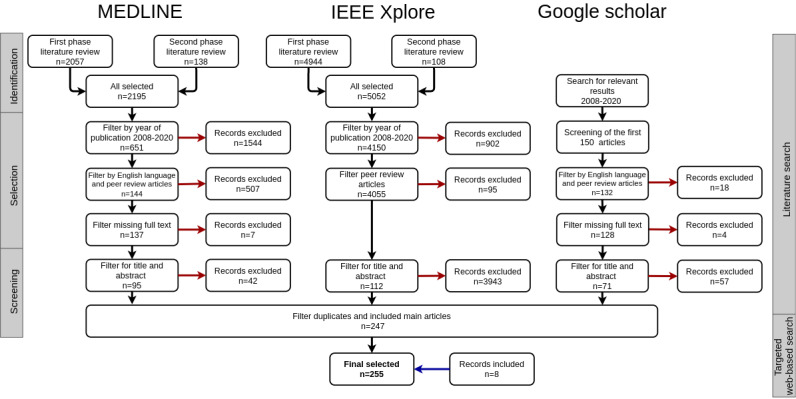
We reviewed manuscripts published in peer-reviewed scientific literature between 2008 and 2020, and selected those that specifically describe IDR architectures. Of 255 shortlisted articles, we found 34 articles describing 29 different architectures. The different IDRs were analyzed for common features and classified according to their data processing and integration solution choices.
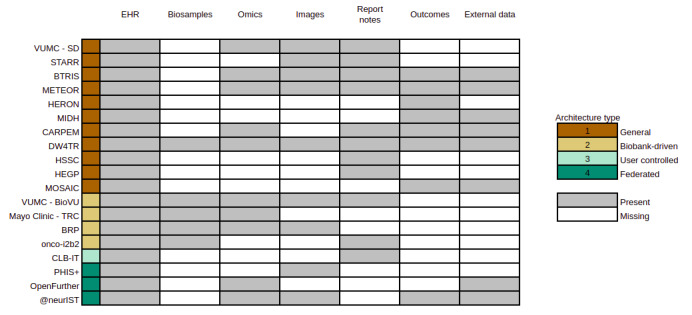
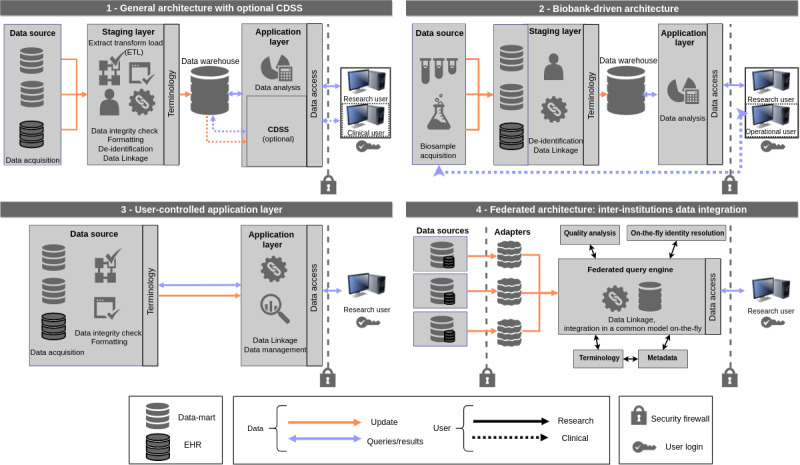
Despite common trends in the selection of standard terminologies and data models, the IDRs examined showed heterogeneity in the underlying architecture design. We identified 4 common architecture models that use different approaches for data processing and integration. These different approaches were driven by a variety of features such as data sources, whether the IDR was for a single institution or a collaborative project, the intended primary data user, and purpose (research-only or including clinical or operational decision making).
IDR implementations are diverse and complex undertakings, which benefit from being preceded by an evaluation of requirements and definition of scope in the early planning stage. Factors such as data source diversity and intended users of the IDR influence data flow and synchronization, both of which are crucial factors in IDR architecture planning.
集成数据存储库(IDR),也被称为临床数据仓库,是通过专门的分析工具来集成多个数据源的平台,这些工具有助于数据处理和分析。IDR为临床数据的重复利用提供了多种机会,在过去十年中,实施IDR的机构数量稳步增长。
主要IDR的架构选择高度多样,确定它们之间的差异可能会让人应接不暇。本综述旨在探讨IDR的潜在模型和共同特征,为初入该领域的人提供高层次的概述,并为中小型医疗机构实施IDR提出一套指导原则。
我们回顾了2008年至2020年间发表在同行评审科学文献中的手稿,并选择了那些专门描述IDR架构的文章。在255篇入围文章中,我们发现有34篇文章描述了29种不同的架构。对不同的IDR进行了共同特征分析,并根据其数据处理和集成解决方案的选择进行了分类。
尽管在标准术语和数据模型的选择上存在共同趋势,但所研究的IDR在底层架构设计上表现出异质性。我们确定了4种常见的架构模型,它们使用不同的数据处理和集成方法。这些不同的方法受到多种特征的驱动,如数据源、IDR是用于单个机构还是合作项目、预期的主要数据用户以及目的(仅用于研究还是包括临床或运营决策)。
IDR的实施是多样且复杂的任务,在早期规划阶段进行需求评估和范围定义会有所助益。诸如数据源多样性和IDR的预期用户等因素会影响数据流和同步,而这两者都是IDR架构规划中的关键因素。