Center for Brain Science, Harvard University, Cambridge, MA 02138, United States of America.
Center for Brain Science, Harvard University, Cambridge, MA 02138, United States of America.
Neural Netw. 2020 Dec;132:428-446. doi: 10.1016/j.neunet.2020.08.022. Epub 2020 Sep 5.
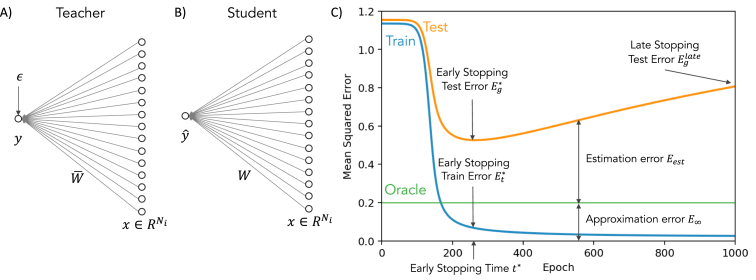
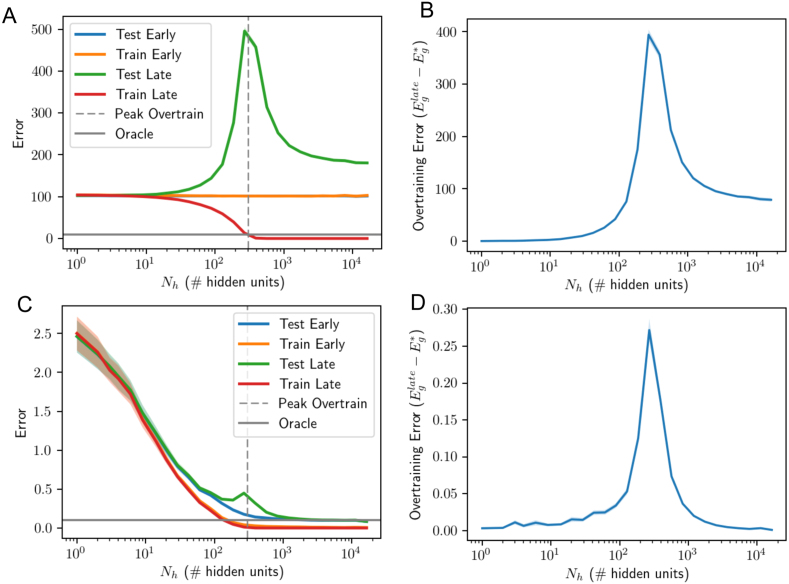
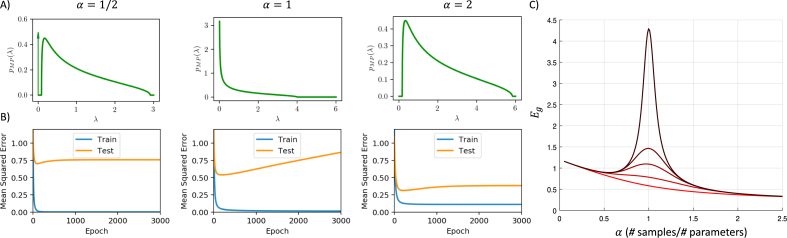
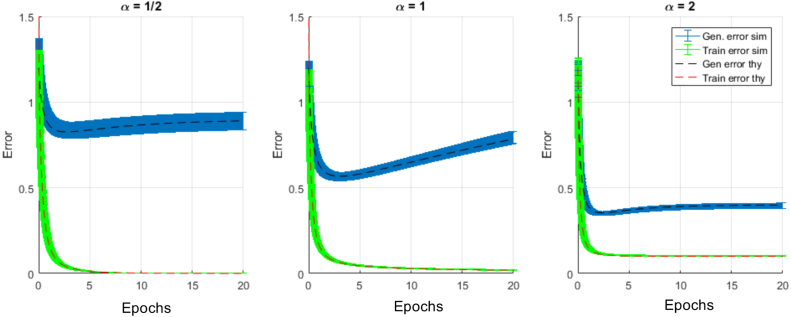
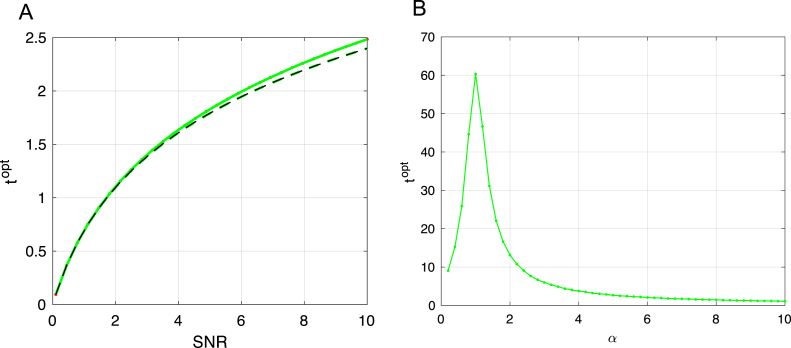
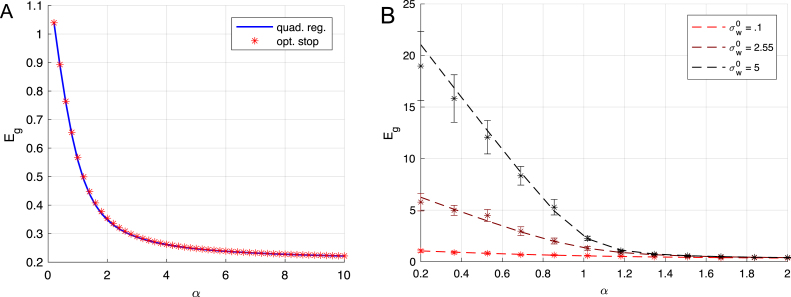
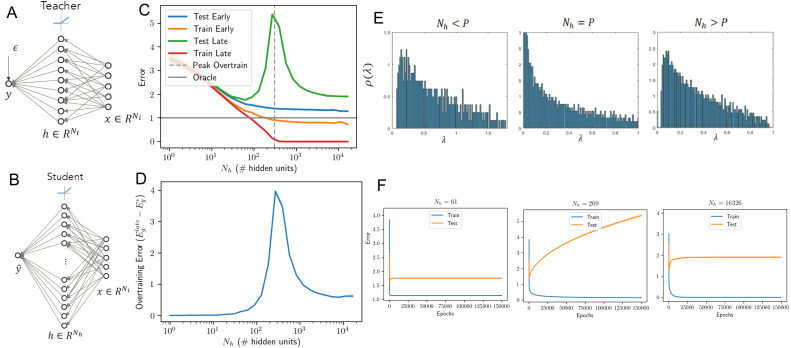
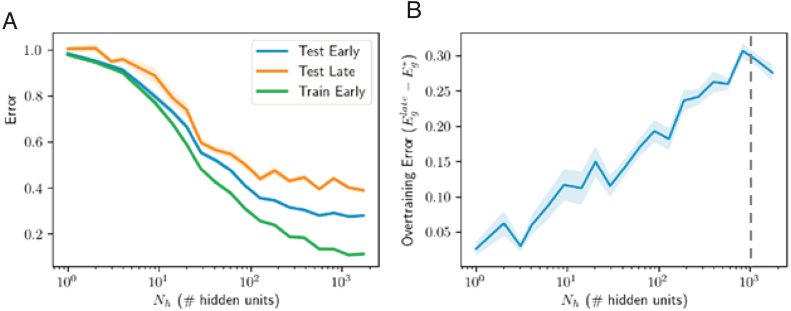
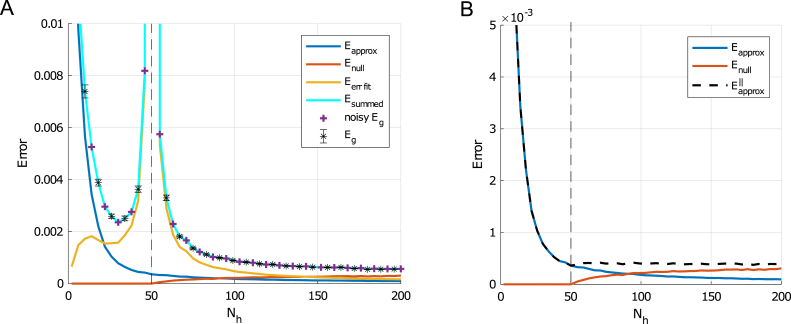
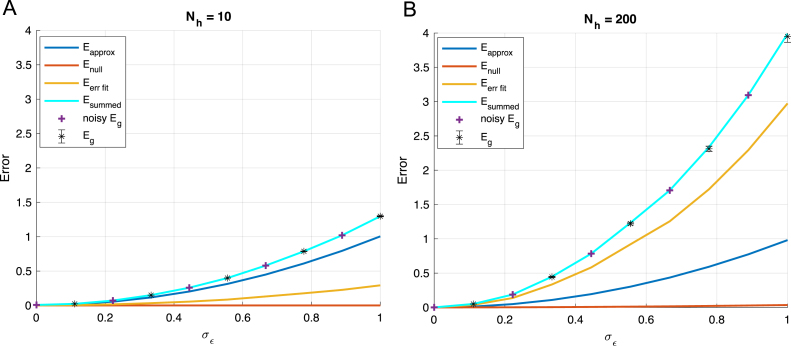
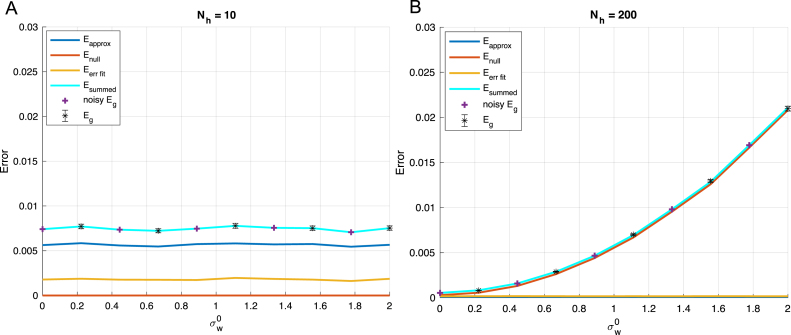
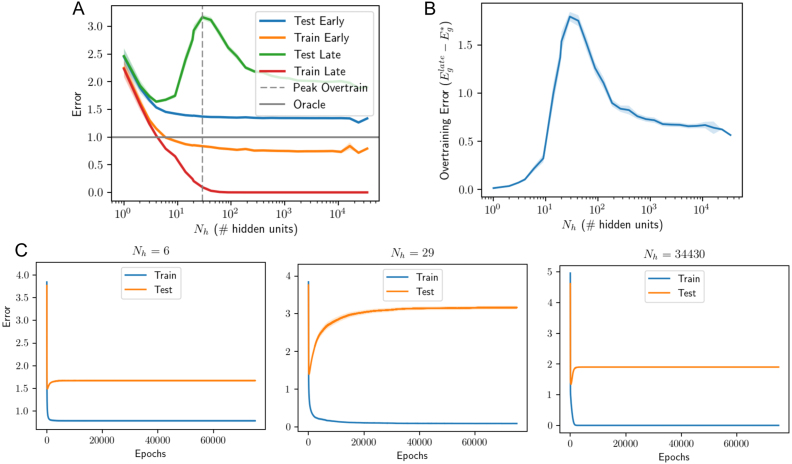
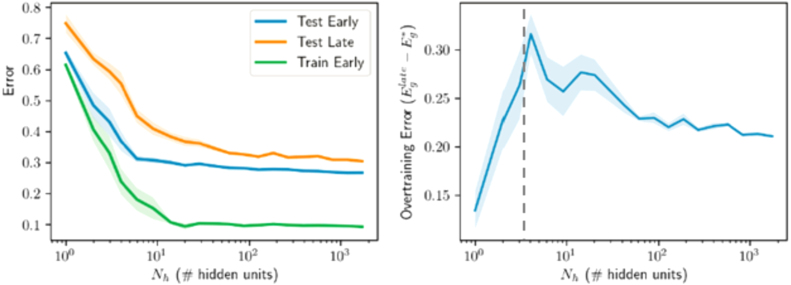
We perform an analysis of the average generalization dynamics of large neural networks trained using gradient descent. We study the practically-relevant "high-dimensional" regime where the number of free parameters in the network is on the order of or even larger than the number of examples in the dataset. Using random matrix theory and exact solutions in linear models, we derive the generalization error and training error dynamics of learning and analyze how they depend on the dimensionality of data and signal to noise ratio of the learning problem. We find that the dynamics of gradient descent learning naturally protect against overtraining and overfitting in large networks. Overtraining is worst at intermediate network sizes, when the effective number of free parameters equals the number of samples, and thus can be reduced by making a network smaller or larger. Additionally, in the high-dimensional regime, low generalization error requires starting with small initial weights. We then turn to non-linear neural networks, and show that making networks very large does not harm their generalization performance. On the contrary, it can in fact reduce overtraining, even without early stopping or regularization of any sort. We identify two novel phenomena underlying this behavior in overcomplete models: first, there is a frozen subspace of the weights in which no learning occurs under gradient descent; and second, the statistical properties of the high-dimensional regime yield better-conditioned input correlations which protect against overtraining. We demonstrate that standard application of theories such as Rademacher complexity are inaccurate in predicting the generalization performance of deep neural networks, and derive an alternative bound which incorporates the frozen subspace and conditioning effects and qualitatively matches the behavior observed in simulation.
我们对使用梯度下降训练的大型神经网络的平均泛化动态进行了分析。我们研究了实际相关的“高维”情况,其中网络中的自由参数数量与数据集中的示例数量相同或更大。使用随机矩阵理论和线性模型的精确解,我们推导出学习的泛化误差和训练误差动态,并分析它们如何取决于数据的维度和学习问题的信噪比。我们发现,梯度下降学习的动态自然可以防止大型网络中的过度训练和过拟合。在中间网络大小下,过度训练最严重,此时有效自由参数数量等于样本数量,因此可以通过使网络更小或更大来减少过度训练。此外,在高维情况下,低泛化误差需要从较小的初始权重开始。然后,我们转向非线性神经网络,并表明使网络非常大不会损害其泛化性能。相反,即使没有任何早期停止或正则化,它实际上也可以减少过度训练。我们确定了过完备模型中这种行为的两个新现象:首先,在梯度下降下,权重存在一个冻结子空间,其中不会发生学习;其次,高维情况下的统计特性产生了条件更好的输入相关性,从而防止了过度训练。我们证明,诸如 Rademacher 复杂度之类的理论的标准应用在预测深度神经网络的泛化性能方面是不准确的,并且推导出了一个替代的界,该界包含了冻结子空间和条件作用,并定性地匹配了模拟中观察到的行为。