West Africa Center for Crop Improvement (WACCI), University of Ghana, Accra, Ghana.
International Maize and Wheat Improvement Center (CIMMYT), Texcoco, Mexico.
Theor Appl Genet. 2021 Jan;134(1):279-294. doi: 10.1007/s00122-020-03696-9. Epub 2020 Oct 10.
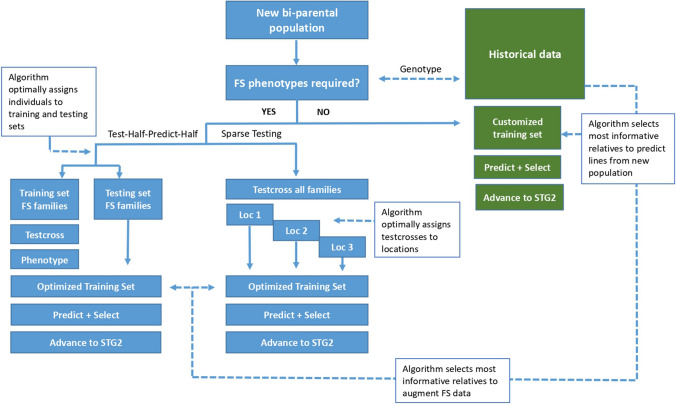
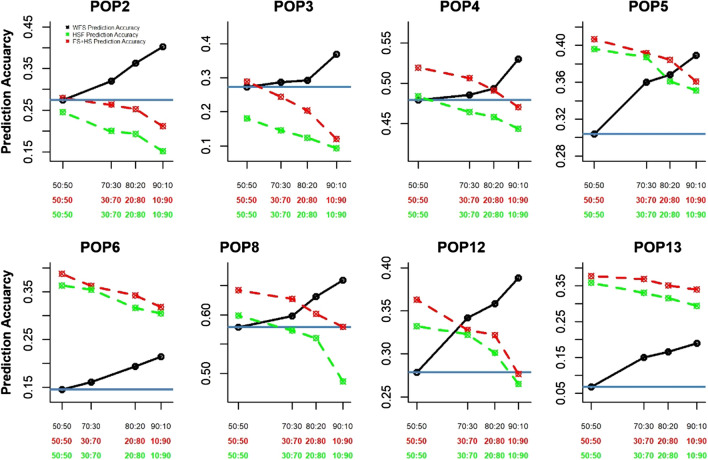
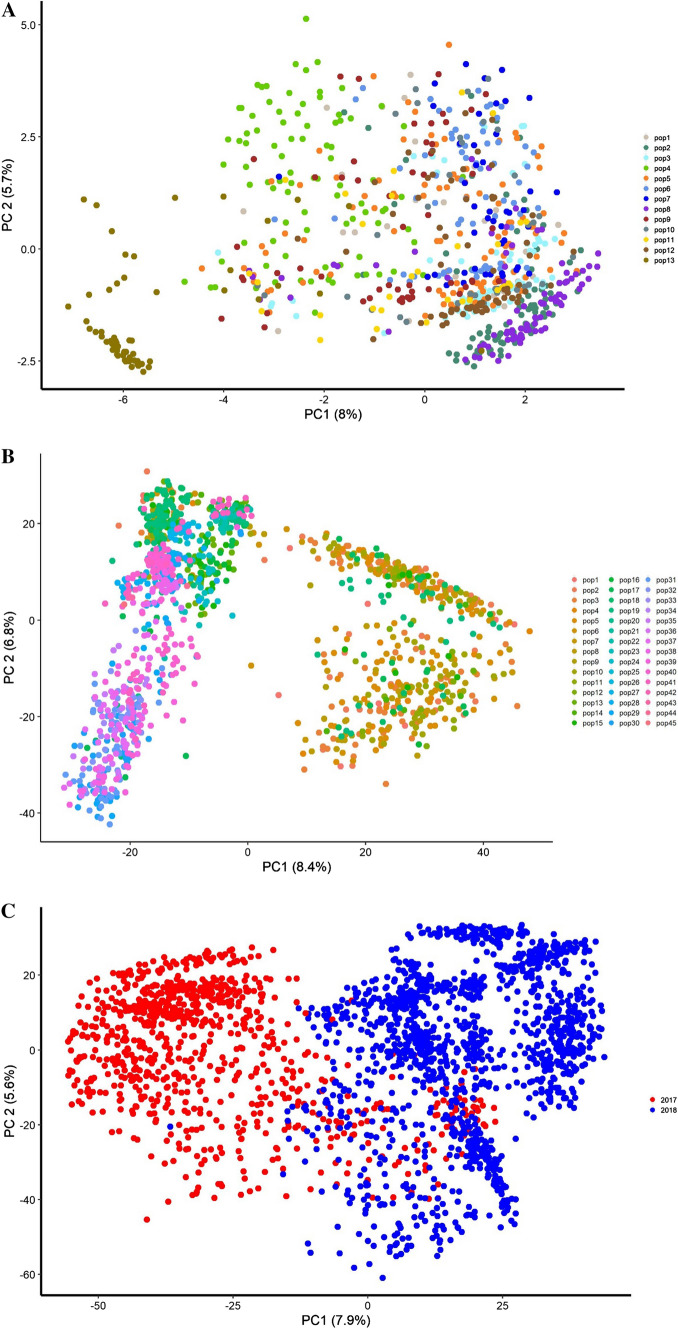
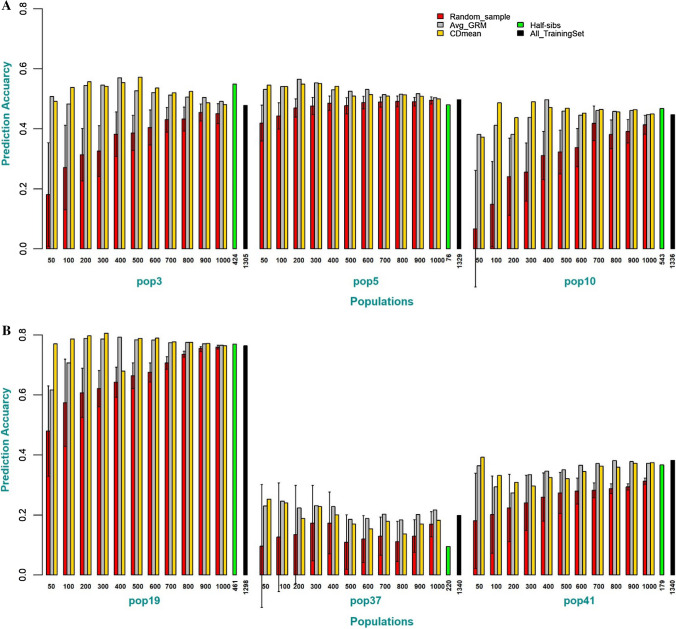
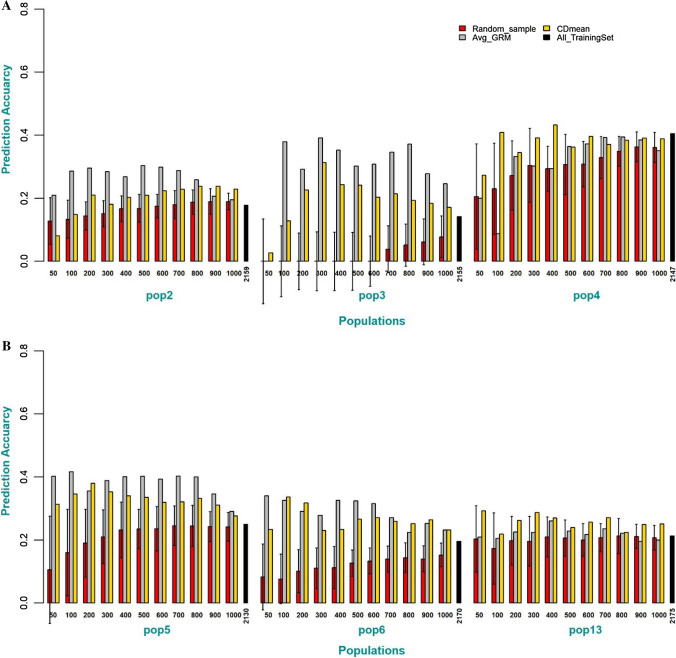
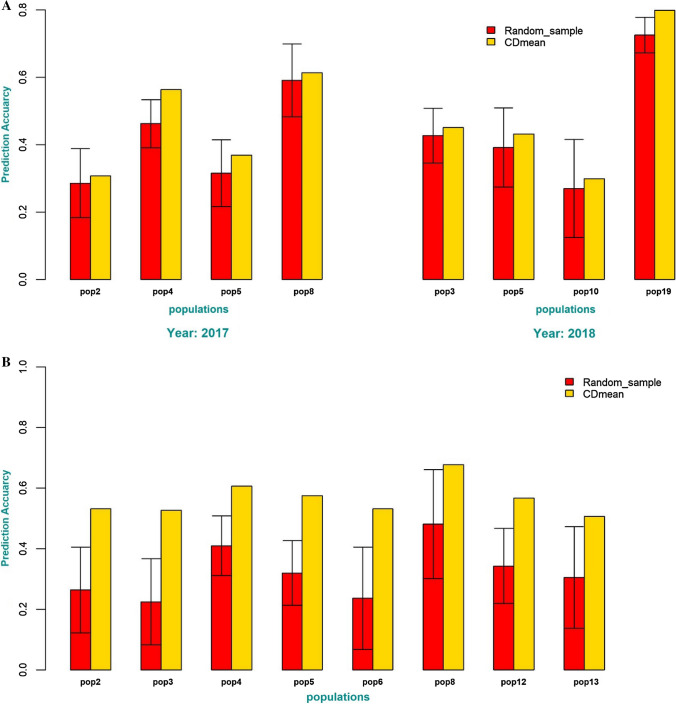
Historical data from breeding programs can be efficiently used to improve genomic selection accuracy, especially when the training set is optimized to subset individuals most informative of the target testing set. The current strategy for large-scale implementation of genomic selection (GS) at the International Maize and Wheat Improvement Center (CIMMYT) global maize breeding program has been to train models using information from full-sibs in a "test-half-predict-half approach." Although effective, this approach has limitations, as it requires large full-sib populations and limits the ability to shorten variety testing and breeding cycle times. The primary objective of this study was to identify optimal experimental and training set designs to maximize prediction accuracy of GS in CIMMYT's maize breeding programs. Training set (TS) design strategies were evaluated to determine the most efficient use of phenotypic data collected on relatives for genomic prediction (GP) using datasets containing 849 (DS1) and 1389 (DS2) DH-lines evaluated as testcrosses in 2017 and 2018, respectively. Our results show there is merit in the use of multiple bi-parental populations as TS when selected using algorithms to maximize relatedness between the training and prediction sets. In a breeding program where relevant past breeding information is not readily available, the phenotyping expenditure can be spread across connected bi-parental populations by phenotyping only a small number of lines from each population. This significantly improves prediction accuracy compared to within-population prediction, especially when the TS for within full-sib prediction is small. Finally, we demonstrate that prediction accuracy in either sparse testing or "test-half-predict-half" can further be improved by optimizing which lines are planted for phenotyping and which lines are to be only genotyped for advancement based on GP.
历史繁殖计划的数据可以有效地用于提高基因组选择的准确性,尤其是当训练集被优化为包含对目标测试集最有信息的个体子集时。国际玉米小麦改良中心(CIMMYT)全球玉米育种计划大规模实施基因组选择(GS)的当前策略一直是使用全同胞的信息在“测试半预测半”方法中训练模型。虽然有效,但这种方法有其局限性,因为它需要大量的全同胞群体,并限制了缩短品种测试和育种周期时间的能力。本研究的主要目的是确定最佳的实验和训练集设计,以最大限度地提高 CIMMYT 玉米育种计划中 GS 的预测准确性。评估了训练集(TS)设计策略,以确定使用包含 849 个(DS1)和 1389 个(DS2)DH 系的数据集收集的亲缘关系数据在基因组预测(GP)中最有效地利用,这些系分别在 2017 年和 2018 年作为测验交进行评估。我们的结果表明,当使用算法选择训练集和预测集之间的亲缘关系最大化时,使用多个双亲群体作为 TS 是有价值的。在一个不容易获得相关过去育种信息的育种计划中,可以通过仅对每个群体的少数系进行表型鉴定,将表型鉴定支出分散到相关的双亲群体中。与群体内预测相比,这显著提高了预测准确性,尤其是当用于群体内全同胞预测的 TS 较小时。最后,我们证明,通过优化用于表型鉴定的系和仅基于 GP 进行选择的系的种植,可以进一步提高稀疏测试或“测试半预测半”中的预测准确性。