Piao Jingchun, Chen Yunfan, Shin Hyunchul
Department of Electrical Engineering, Hanyang University, Ansan 15588, Korea.
Entropy (Basel). 2019 Jun 5;21(6):570. doi: 10.3390/e21060570.
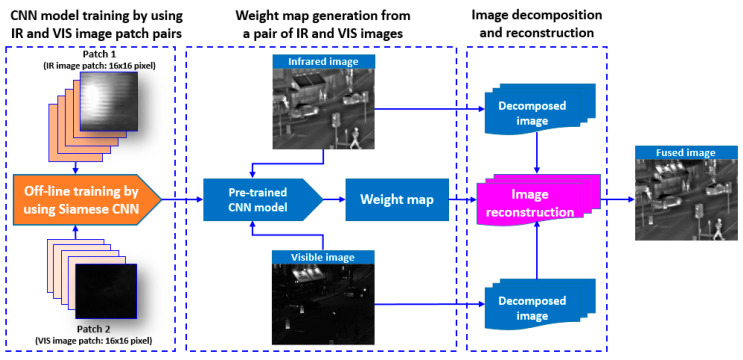
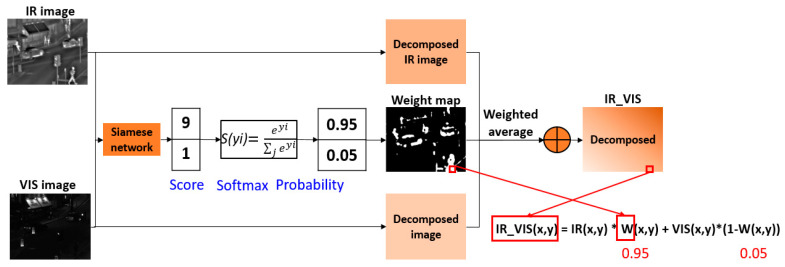
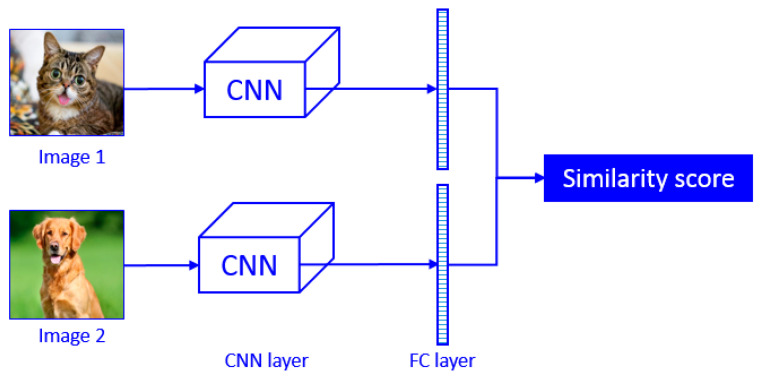
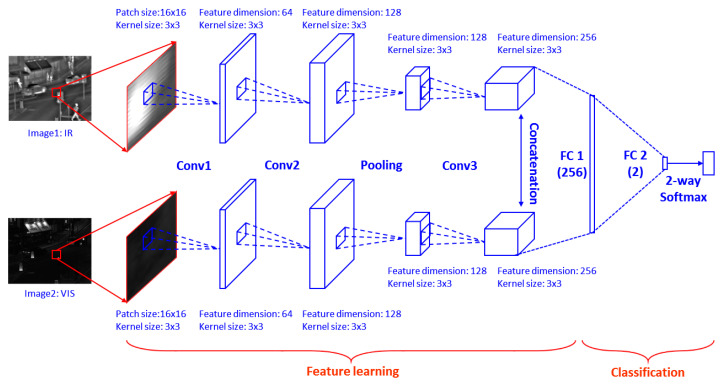
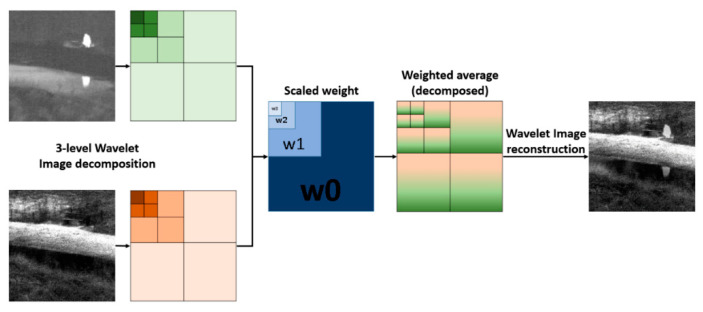
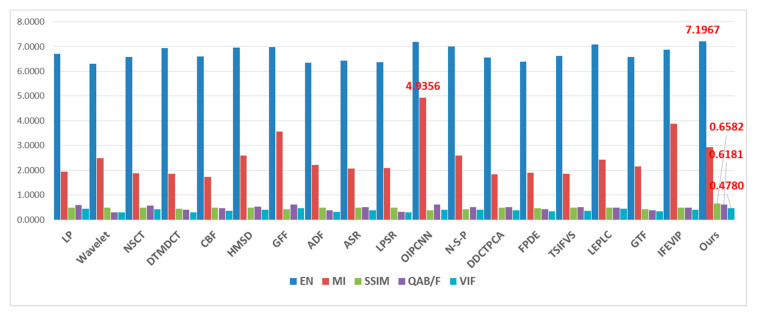
In this paper, we present a new effective infrared (IR) and visible (VIS) image fusion method by using a deep neural network. In our method, a Siamese convolutional neural network (CNN) is applied to automatically generate a weight map which represents the saliency of each pixel for a pair of source images. A CNN plays a role in automatic encoding an image into a feature domain for classification. By applying the proposed method, the key problems in image fusion, which are the activity level measurement and fusion rule design, can be figured out in one shot. The fusion is carried out through the multi-scale image decomposition based on wavelet transform, and the reconstruction result is more perceptual to a human visual system. In addition, the visual qualitative effectiveness of the proposed fusion method is evaluated by comparing pedestrian detection results with other methods, by using the YOLOv3 object detector using a public benchmark dataset. The experimental results show that our proposed method showed competitive results in terms of both quantitative assessment and visual quality.
在本文中,我们提出了一种利用深度神经网络的新型有效红外(IR)与可见光(VIS)图像融合方法。在我们的方法中,应用暹罗卷积神经网络(CNN)自动生成一个权重图,该权重图表示一对源图像中每个像素的显著性。CNN在将图像自动编码到特征域以进行分类方面发挥作用。通过应用所提出的方法,图像融合中的关键问题,即活动水平测量和融合规则设计,可以一次性解决。融合通过基于小波变换的多尺度图像分解来进行,并且重建结果对人类视觉系统更具感知性。此外,通过使用公共基准数据集,利用YOLOv3目标检测器将行人检测结果与其他方法进行比较,对所提出融合方法的视觉定性有效性进行评估。实验结果表明,我们提出的方法在定量评估和视觉质量方面都显示出具有竞争力的结果。