Laboratoire de Neurosciences Cognitives et Computationnelles, Institut National de la Santé et de la Recherche Médicale, Paris, France.
Département d'Études Cognitives, École Normale Supérieure, Paris, France.
PLoS Biol. 2020 Dec 8;18(12):e3001028. doi: 10.1371/journal.pbio.3001028. eCollection 2020 Dec.
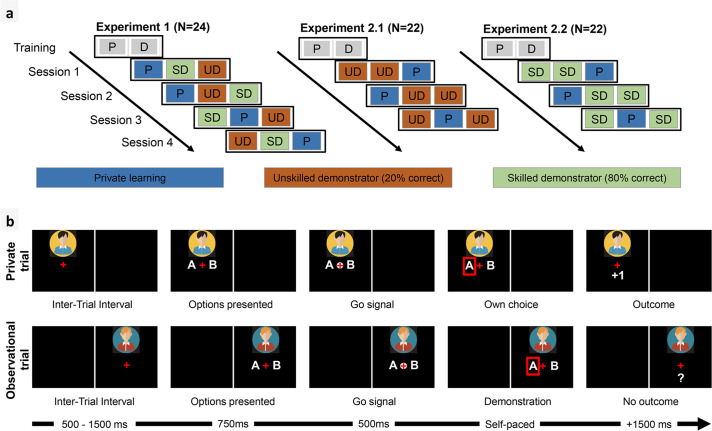
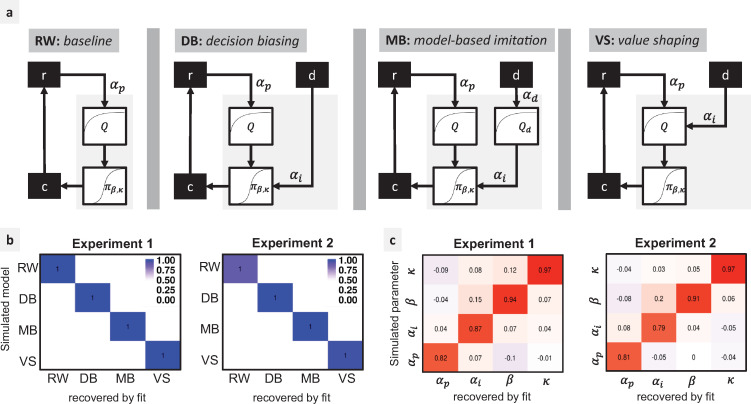
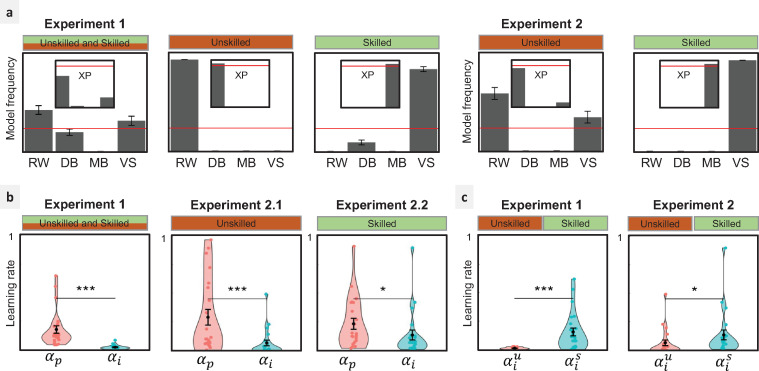
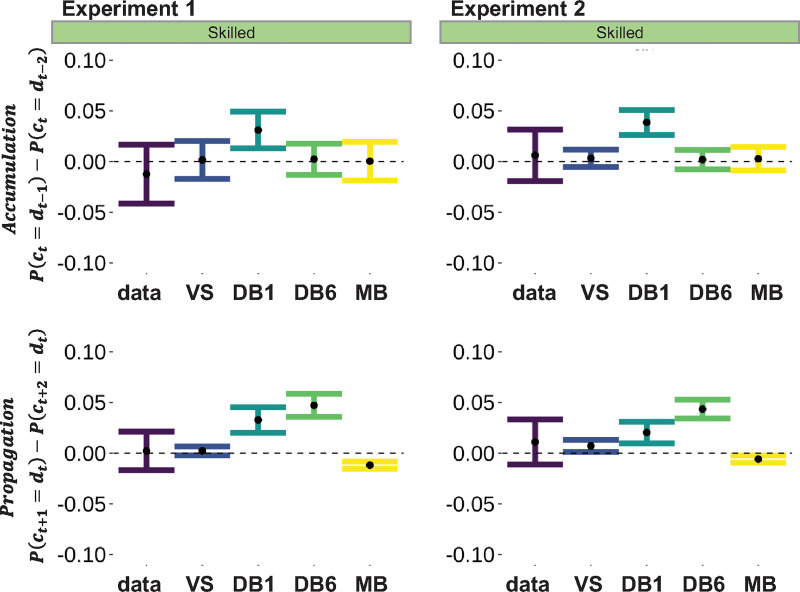
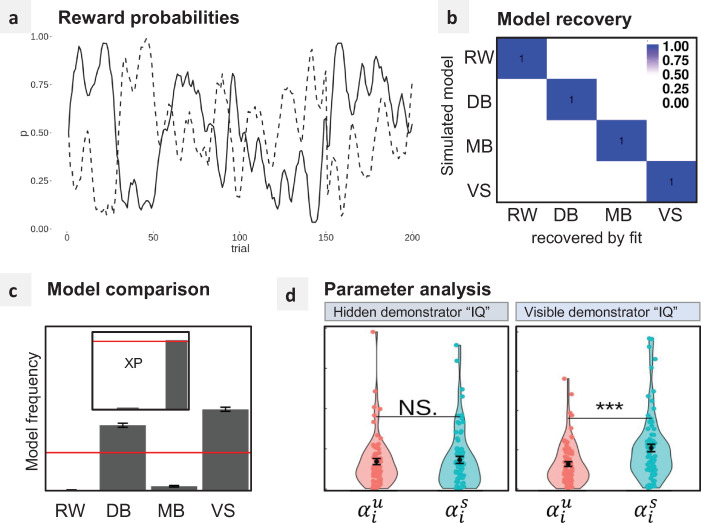
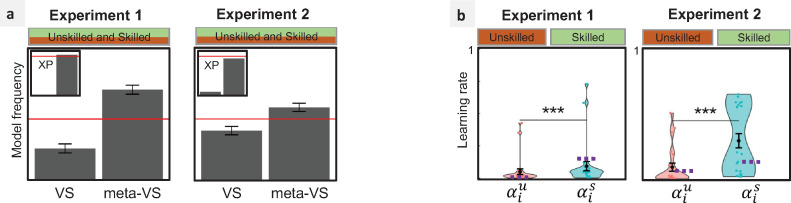
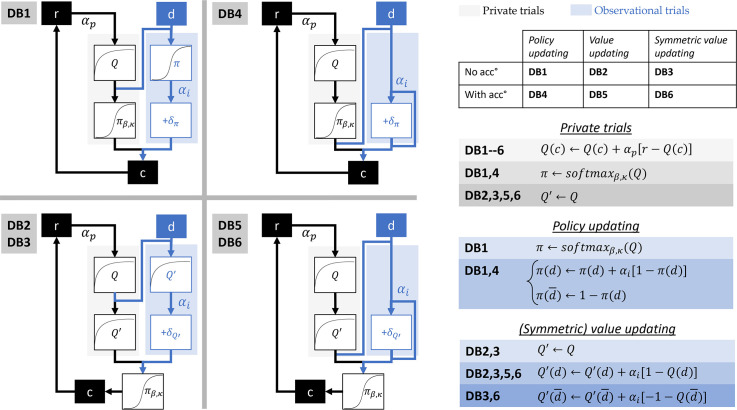
While there is no doubt that social signals affect human reinforcement learning, there is still no consensus about how this process is computationally implemented. To address this issue, we compared three psychologically plausible hypotheses about the algorithmic implementation of imitation in reinforcement learning. The first hypothesis, decision biasing (DB), postulates that imitation consists in transiently biasing the learner's action selection without affecting their value function. According to the second hypothesis, model-based imitation (MB), the learner infers the demonstrator's value function through inverse reinforcement learning and uses it to bias action selection. Finally, according to the third hypothesis, value shaping (VS), the demonstrator's actions directly affect the learner's value function. We tested these three hypotheses in 2 experiments (N = 24 and N = 44) featuring a new variant of a social reinforcement learning task. We show through model comparison and model simulation that VS provides the best explanation of learner's behavior. Results replicated in a third independent experiment featuring a larger cohort and a different design (N = 302). In our experiments, we also manipulated the quality of the demonstrators' choices and found that learners were able to adapt their imitation rate, so that only skilled demonstrators were imitated. We proposed and tested an efficient meta-learning process to account for this effect, where imitation is regulated by the agreement between the learner and the demonstrator. In sum, our findings provide new insights and perspectives on the computational mechanisms underlying adaptive imitation in human reinforcement learning.
虽然社会信号无疑会影响人类的强化学习,但对于这一过程是如何在计算上实现的,仍然没有共识。为了解决这个问题,我们比较了强化学习中模仿的算法实现的三个心理上合理的假设。第一个假设是决策偏向(Decision Biasing,DB),它假定模仿包括暂时偏向学习者的动作选择,而不影响他们的价值函数。根据第二个假设,基于模型的模仿(Model-based Imitation,MB),学习者通过逆强化学习推断出示范者的价值函数,并使用它来偏向动作选择。最后,根据第三个假设,价值塑造(Value Shaping,VS),示范者的动作直接影响学习者的价值函数。我们在两个实验(N=24 和 N=44)中测试了这三个假设,这些实验具有一个社会强化学习任务的新变体。通过模型比较和模型模拟,我们表明 VS 提供了对学习者行为的最佳解释。在第三个独立实验中,我们使用更大的队列和不同的设计(N=302)重复了结果。在我们的实验中,我们还操纵了示范者选择的质量,发现学习者能够调整他们的模仿率,只模仿熟练的示范者。我们提出并测试了一个有效的元学习过程来解释这种效应,其中模仿受到学习者和示范者之间一致性的调节。总之,我们的发现为人类强化学习中适应性模仿的计算机制提供了新的见解和视角。