Sun BaoLuo, Liu Lan, Miao Wang, Wirth Kathleen, Robins James, Tchetgen Tchetgen Eric J
Department of Biostatistics, Harvard T.H. Chan School of Public Health.
Beijing International Center for Mathematical Research, Peking University.
Stat Sin. 2018 Oct;28(4):1965-1983. doi: 10.5705/ss.202016.0324.
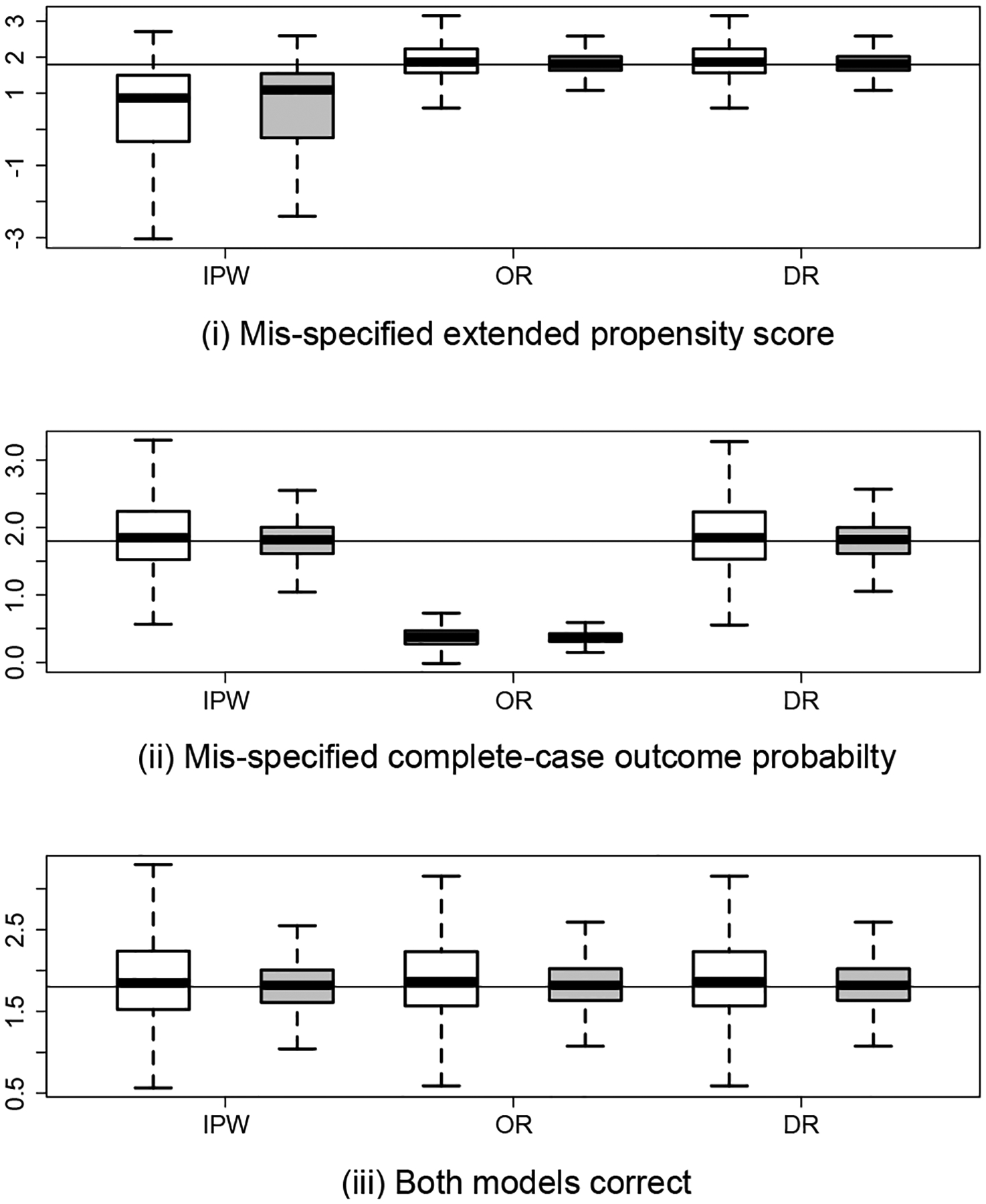
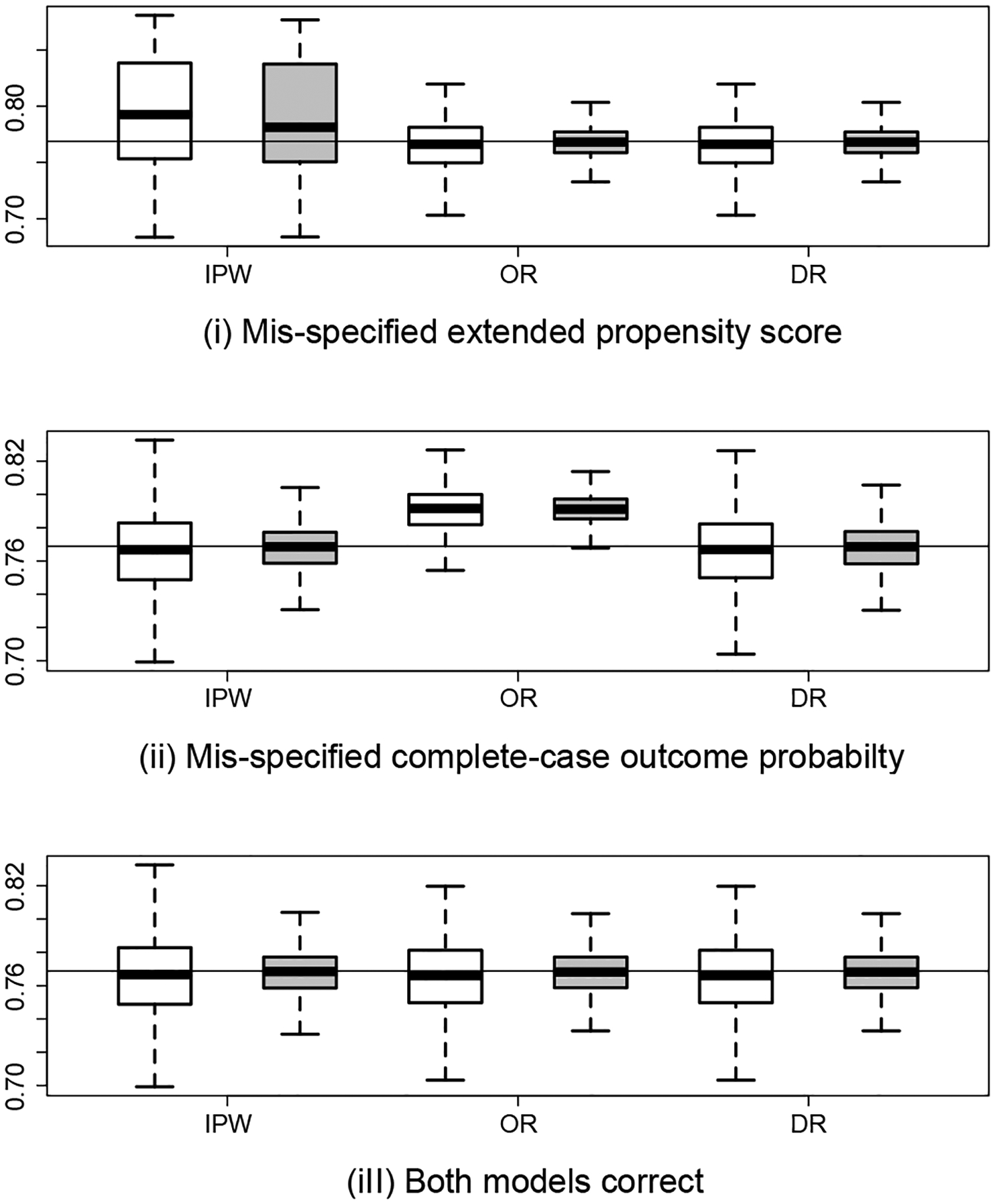
Missing data occur frequently in empirical studies in health and social sciences, often compromising our ability to make accurate inferences. An outcome is said to be missing not at random (MNAR) if, conditional on the observed variables, the missing data mechanism still depends on the unobserved outcome. In such settings, identification is generally not possible without imposing additional assumptions. Identification is sometimes possible, however, if an instrumental variable (IV) is observed for all subjects which satisfies the exclusion restriction that the IV affects the missingness process without directly influencing the outcome. In this paper, we provide necessary and sufficient conditions for nonparametric identification of the full data distribution under MNAR with the aid of an IV. In addition, we give sufficient identification conditions that are more straightforward to verify in practice. For inference, we focus on estimation of a population outcome mean, for which we develop a suite of semiparametric estimators that extend methods previously developed for data missing at random. Specifically, we propose inverse probability weighted estimation, outcome regression-based estimation and doubly robust estimation of the mean of an outcome subject to MNAR. For illustration, the methods are used to account for selection bias induced by HIV testing refusal in the evaluation of HIV seroprevalence in Mochudi, Botswana, using interviewer characteristics such as gender, age and years of experience as IVs.
缺失数据在健康与社会科学的实证研究中频繁出现,常常影响我们做出准确推断的能力。如果在观测变量的条件下,缺失数据机制仍依赖于未观测到的结果,则称该结果为非随机缺失(MNAR)。在这种情况下,若不施加额外假设,通常无法进行识别。然而,如果为所有受试者观测到一个满足排除限制的工具变量(IV),即该IV影响缺失过程但不直接影响结果,那么有时是可以进行识别的。在本文中,我们给出了借助IV在MNAR情况下对完整数据分布进行非参数识别的充要条件。此外,我们还给出了在实践中更易于验证的充分识别条件。对于推断,我们专注于总体结果均值的估计,为此我们开发了一套半参数估计量,扩展了先前为随机缺失数据开发的方法。具体而言,我们提出了针对MNAR结果均值的逆概率加权估计、基于结果回归的估计和双重稳健估计。为作说明,这些方法被用于在博茨瓦纳莫丘迪评估艾滋病毒血清流行率时,利用诸如性别、年龄和工作年限等访员特征作为IV来处理因拒绝艾滋病毒检测导致的选择偏差。