Community Pediatrics and Adolescent Medicine, Mayo Clinic, Rochester, Minnesota, USA.
Pusan National University Yangsan Hospital, Yangsan, Republic of Korea.
BMJ Open Respir Res. 2020 Feb;7(1). doi: 10.1136/bmjresp-2019-000524.
The lack of effective, consistent, reproducible and efficient asthma ascertainment methods results in inconsistent asthma cohorts and study results for clinical trials or other studies. We aimed to assess whether application of expert artificial intelligence (AI)-based natural language processing (NLP) algorithms for two existing asthma criteria to electronic health records of a paediatric population systematically identifies childhood asthma and its subgroups with distinctive characteristics.
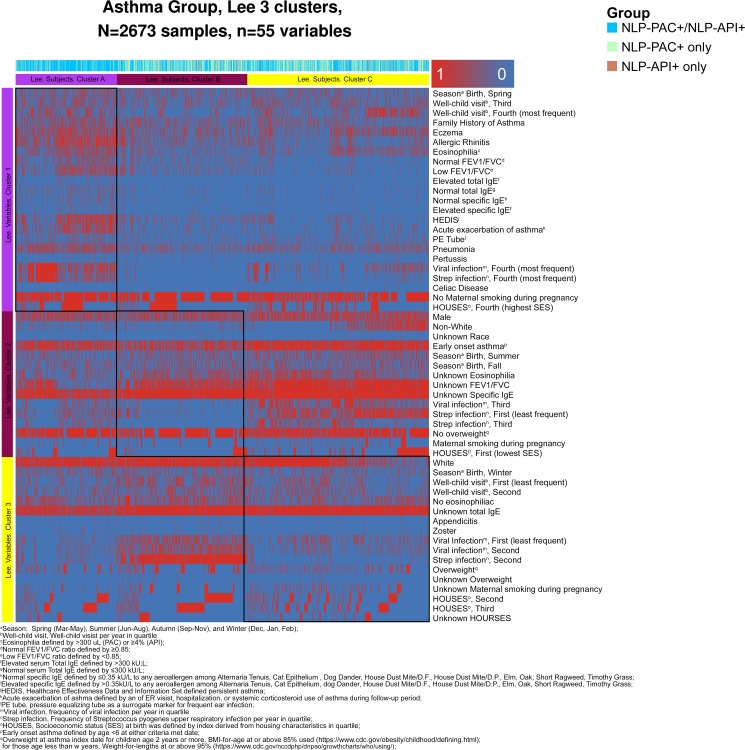
Using the 1997-2007 Olmsted County Birth Cohort, we applied validated NLP algorithms for Predetermined Asthma Criteria (NLP-PAC) as well as Asthma Predictive Index (NLP-API). We categorised subjects into four groups (both criteria positive (NLP-PAC/NLP-API); PAC positive only (NLP-PAC only); API positive only (NLP-API only); and both criteria negative (NLP-PAC/NLP-API)) and characterised them. Results were replicated in unsupervised cluster analysis for asthmatics and a random sample of 300 children using laboratory and pulmonary function tests (PFTs).
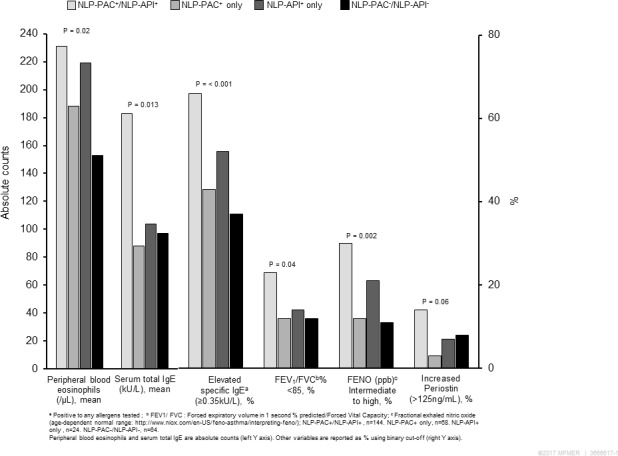
Of the 8196 subjects (51% male, 80% white), we identified 1614 (20%), NLP-PAC/NLP-API; 954 (12%), NLP-PAC only; 105 (1%), NLP-API only; and 5523 (67%), NLP-PAC/NLP-API. Asthmatic children classified as NLP-PAC/NLP-API showed earlier onset asthma, more Th2-high profile, poorer lung function, higher asthma exacerbation and higher risk of asthma-associated comorbidities compared with other groups. These results were consistent with those based on unsupervised cluster analysis and lab and PFT data of a random sample of study subjects.
Expert AI-based NLP algorithms for two asthma criteria systematically identify childhood asthma with distinctive characteristics. This approach may improve precision, reproducibility, consistency and efficiency of large-scale clinical studies for asthma and enable population management.
缺乏有效、一致、可重现和高效的哮喘确定方法会导致临床试验或其他研究中出现不一致的哮喘队列和研究结果。我们旨在评估应用专家人工智能 (AI) 基于自然语言处理 (NLP) 算法对两个现有的哮喘标准进行电子健康记录,是否可以系统地识别儿童哮喘及其具有独特特征的亚组。
使用 1997-2007 年奥姆斯特德县出生队列,我们应用了经过验证的预测性哮喘标准的 NLP 算法(NLP-PAC)和哮喘预测指数的 NLP 算法(NLP-API)。我们将受试者分为四组(两个标准均阳性(NLP-PAC/NLP-API);PAC 标准阳性仅(NLP-PAC 仅);API 标准阳性仅(NLP-API 仅);和两个标准均阴性(NLP-PAC/NLP-API)),并对其特征进行了描述。结果在使用实验室和肺功能测试 (PFT) 的哮喘患者和随机选择的 300 名儿童的无监督聚类分析中得到了复制。
在 8196 名受试者中(51%为男性,80%为白人),我们确定了 1614 名(20%),NLP-PAC/NLP-API;954 名(12%),NLP-PAC 仅;105 名(1%),NLP-API 仅;和 5523 名(67%),NLP-PAC/NLP-API。被归类为 NLP-PAC/NLP-API 的哮喘儿童哮喘发作更早,Th2 高特征更明显,肺功能更差,哮喘加重的风险更高,并且与哮喘相关的合并症的风险更高。这些结果与基于无监督聚类分析以及研究对象的随机样本的实验室和 PFT 数据的结果一致。
用于两种哮喘标准的专家 AI 基于 NLP 算法可以系统地识别具有独特特征的儿童哮喘。这种方法可以提高大规模哮喘临床研究的精度、重现性、一致性和效率,并能够进行人群管理。