Arús-Pous Josep, Johansson Simon Viet, Prykhodko Oleksii, Bjerrum Esben Jannik, Tyrchan Christian, Reymond Jean-Louis, Chen Hongming, Engkvist Ola
Hit Discovery, Discovery Sciences, R&D, AstraZeneca Gothenburg, Mölndal, Sweden.
Department of Chemistry and Biochemistry, University of Bern, Freiestrasse 3, 3012, Bern, Switzerland.
J Cheminform. 2019 Nov 21;11(1):71. doi: 10.1186/s13321-019-0393-0.
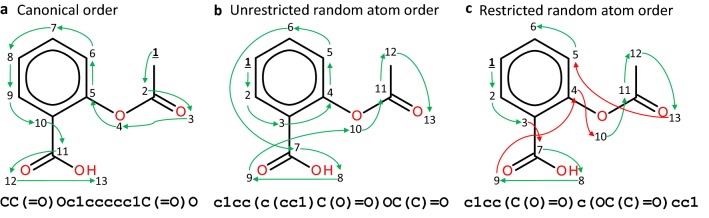
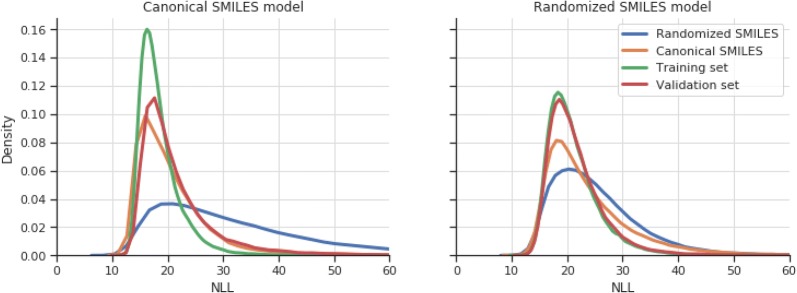
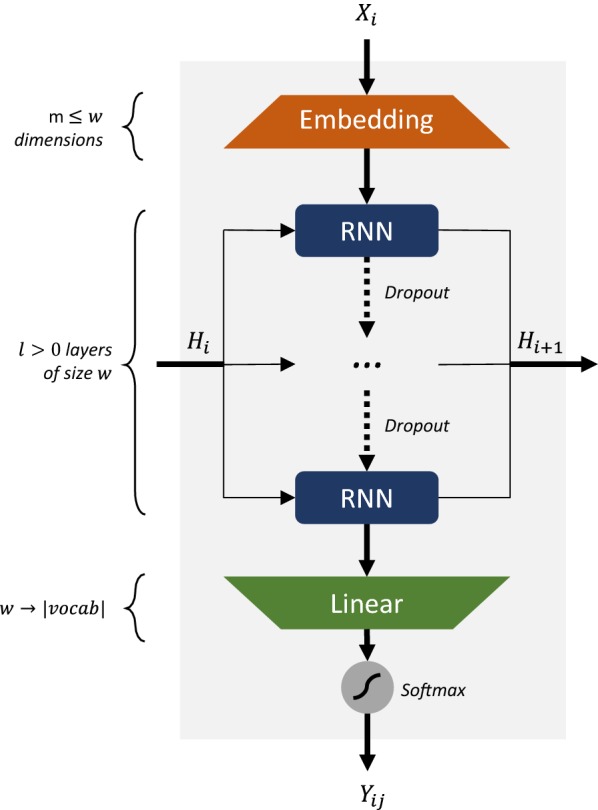
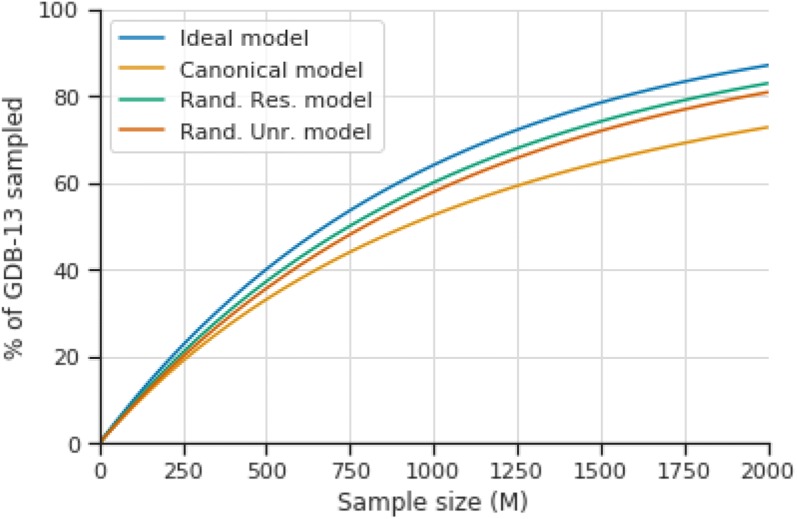
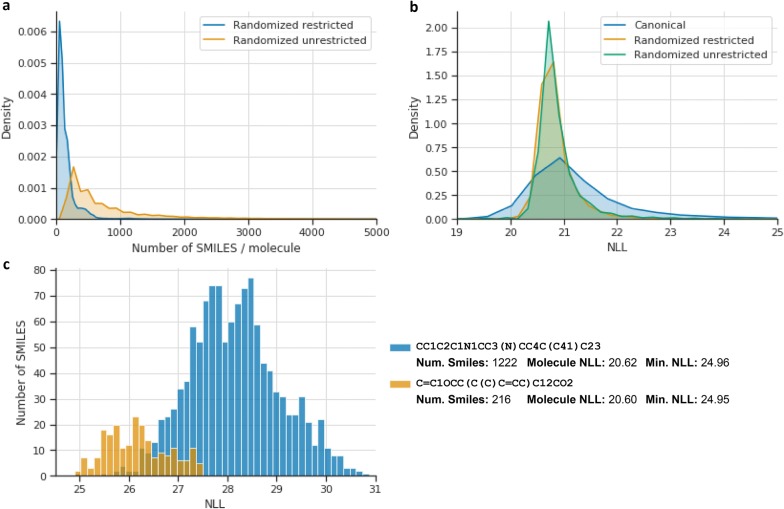
Recurrent Neural Networks (RNNs) trained with a set of molecules represented as unique (canonical) SMILES strings, have shown the capacity to create large chemical spaces of valid and meaningful structures. Herein we perform an extensive benchmark on models trained with subsets of GDB-13 of different sizes (1 million, 10,000 and 1000), with different SMILES variants (canonical, randomized and DeepSMILES), with two different recurrent cell types (LSTM and GRU) and with different hyperparameter combinations. To guide the benchmarks new metrics were developed that define how well a model has generalized the training set. The generated chemical space is evaluated with respect to its uniformity, closedness and completeness. Results show that models that use LSTM cells trained with 1 million randomized SMILES, a non-unique molecular string representation, are able to generalize to larger chemical spaces than the other approaches and they represent more accurately the target chemical space. Specifically, a model was trained with randomized SMILES that was able to generate almost all molecules from GDB-13 with a quasi-uniform probability. Models trained with smaller samples show an even bigger improvement when trained with randomized SMILES models. Additionally, models were trained on molecules obtained from ChEMBL and illustrate again that training with randomized SMILES lead to models having a better representation of the drug-like chemical space. Namely, the model trained with randomized SMILES was able to generate at least double the amount of unique molecules with the same distribution of properties comparing to one trained with canonical SMILES.
用一组表示为独特(规范)SMILES字符串的分子训练的循环神经网络(RNN),已显示出创建有效且有意义结构的大型化学空间的能力。在此,我们对使用不同大小(100万、1万和1000)的GDB - 13子集、不同SMILES变体(规范、随机化和DeepSMILES)、两种不同循环单元类型(LSTM和GRU)以及不同超参数组合训练的模型进行了广泛的基准测试。为指导基准测试,开发了新的指标来定义模型对训练集的泛化程度。根据生成化学空间的均匀性、封闭性和完整性对其进行评估。结果表明,使用100万个随机化SMILES(一种非唯一分子字符串表示)训练的LSTM单元模型,比其他方法能够泛化到更大的化学空间,并且能更准确地表示目标化学空间。具体而言,一个用随机化SMILES训练的模型能够以近似均匀的概率生成GDB - 13中的几乎所有分子。用较小样本训练的模型在使用随机化SMILES模型训练时显示出更大的改进。此外,对从ChEMBL获得的分子进行了模型训练,再次说明使用随机化SMILES训练会使模型对类药物化学空间有更好的表示。也就是说,与使用规范SMILES训练的模型相比,使用随机化SMILES训练的模型能够生成至少两倍数量的具有相同性质分布的独特分子。