Kaliyar Rohit Kumar, Goswami Anurag, Narang Pratik
Departement of Computer Science Engineering, Bennett University, Greater Noida, India.
Departement of CSIS, BITS Pilani, Pilani, Rajasthan India.
Multimed Tools Appl. 2021;80(8):11765-11788. doi: 10.1007/s11042-020-10183-2. Epub 2021 Jan 7.
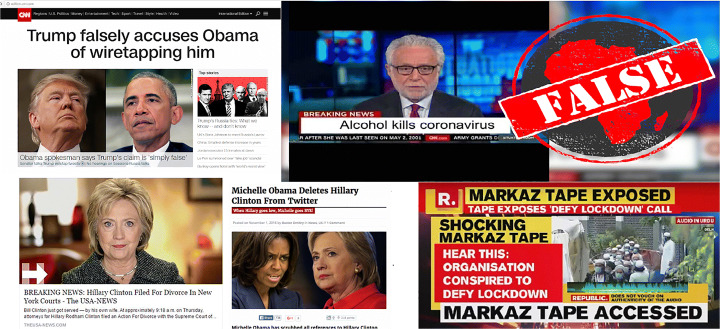
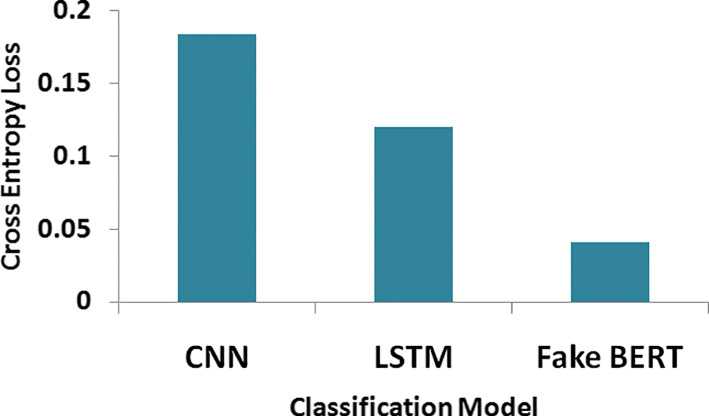
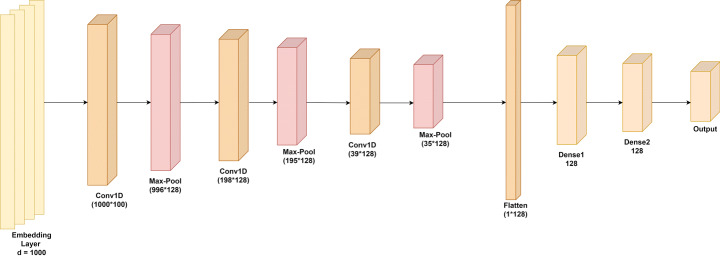
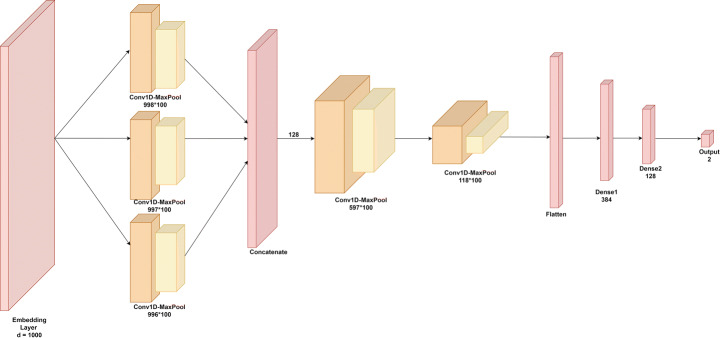
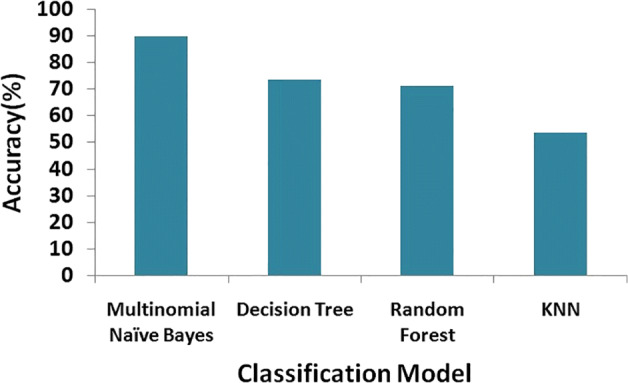
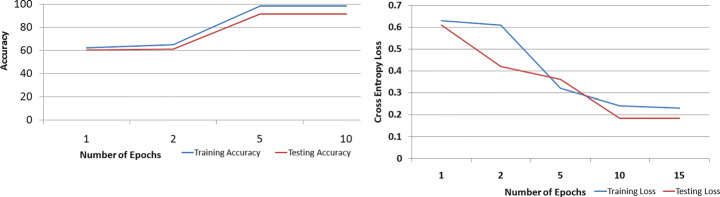
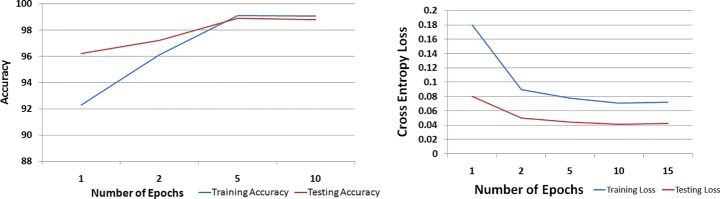
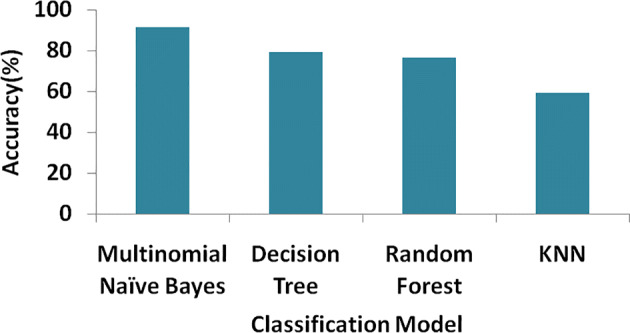
In the modern era of computing, the news ecosystem has transformed from old traditional print media to social media outlets. Social media platforms allow us to consume news much faster, with less restricted editing results in the spread of fake news at an incredible pace and scale. In recent researches, many useful methods for fake news detection employ sequential neural networks to encode news content and social context-level information where the text sequence was analyzed in a unidirectional way. Therefore, a bidirectional training approach is a priority for modelling the relevant information of fake news that is capable of improving the classification performance with the ability to capture semantic and long-distance dependencies in sentences. In this paper, we propose a BERT-based (Bidirectional Encoder Representations from Transformers) deep learning approach (FakeBERT) by combining different parallel blocks of the single-layer deep Convolutional Neural Network (CNN) having different kernel sizes and filters with the BERT. Such a combination is useful to handle ambiguity, which is the greatest challenge to natural language understanding. Classification results demonstrate that our proposed model (FakeBERT) outperforms the existing models with an accuracy of 98.90%.
在现代计算时代,新闻生态系统已从传统的印刷媒体转变为社交媒体平台。社交媒体平台使我们能够更快地获取新闻,然而编辑限制较少导致假新闻以惊人的速度和规模传播。在最近的研究中,许多用于检测假新闻的有用方法采用顺序神经网络来编码新闻内容和社会背景层面的信息,其中文本序列是以单向方式进行分析的。因此,双向训练方法对于对假新闻的相关信息进行建模至关重要,它能够通过捕捉句子中的语义和长距离依赖关系来提高分类性能。在本文中,我们通过将具有不同内核大小和滤波器的单层深度卷积神经网络(CNN)的不同并行块与BERT相结合,提出了一种基于BERT(来自变换器的双向编码器表示)的深度学习方法(FakeBERT)。这种组合有助于处理模糊性,而模糊性是自然语言理解面临的最大挑战。分类结果表明,我们提出的模型(FakeBERT)以98.90%的准确率优于现有模型。