Center for Biomedical Informatics Research, Stanford University, Stanford, CA, USA.
Elsevier Health Markets, Philadelphia, PA, USA.
Sci Data. 2021 Jan 21;8(1):24. doi: 10.1038/s41597-021-00797-y.
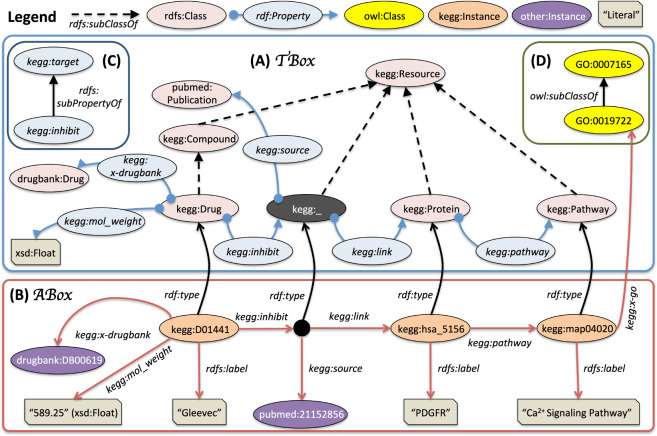
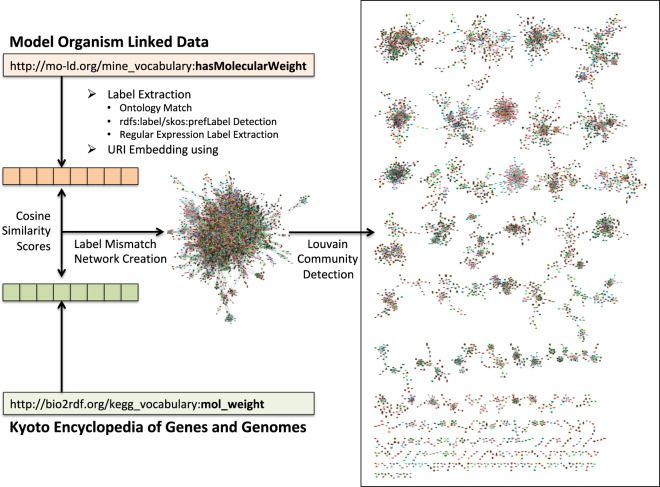
While the biomedical community has published several "open data" sources in the last decade, most researchers still endure severe logistical and technical challenges to discover, query, and integrate heterogeneous data and knowledge from multiple sources. To tackle these challenges, the community has experimented with Semantic Web and linked data technologies to create the Life Sciences Linked Open Data (LSLOD) cloud. In this paper, we extract schemas from more than 80 biomedical linked open data sources into an LSLOD schema graph and conduct an empirical meta-analysis to evaluate the extent of semantic heterogeneity across the LSLOD cloud. We observe that several LSLOD sources exist as stand-alone data sources that are not inter-linked with other sources, use unpublished schemas with minimal reuse or mappings, and have elements that are not useful for data integration from a biomedical perspective. We envision that the LSLOD schema graph and the findings from this research will aid researchers who wish to query and integrate data and knowledge from multiple biomedical sources simultaneously on the Web.
虽然生物医学界在过去十年中发布了几个“开放数据”资源,但大多数研究人员在发现、查询和整合来自多个来源的异构数据和知识方面仍然面临严重的后勤和技术挑战。为了解决这些挑战,该社区尝试了语义 Web 和链接数据技术,以创建生命科学链接开放数据 (LSLOD) 云。在本文中,我们从 80 多个生物医学链接开放数据资源中提取模式到 LSLOD 模式图中,并进行实证元分析来评估 LSLOD 云中语义异构的程度。我们观察到,一些 LSLOD 资源作为独立数据源存在,与其他数据源没有相互链接,使用未公开的模式,最小限度地重用或映射,并且从生物医学角度来看,有些元素对于数据集成没有用处。我们设想 LSLOD 模式图和这项研究的结果将帮助那些希望在 Web 上同时查询和整合来自多个生物医学源的数据和知识的研究人员。