Department of Biomedical Informatics, School of Medicine, Emory University, 101 Woodruff Circle, Atlanta, GA, 30322, USA.
Department of Biostatistics, Epidemiology and Informatics, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, 19104, USA.
BMC Med Inform Decis Mak. 2021 Jan 26;21(1):27. doi: 10.1186/s12911-021-01394-0.
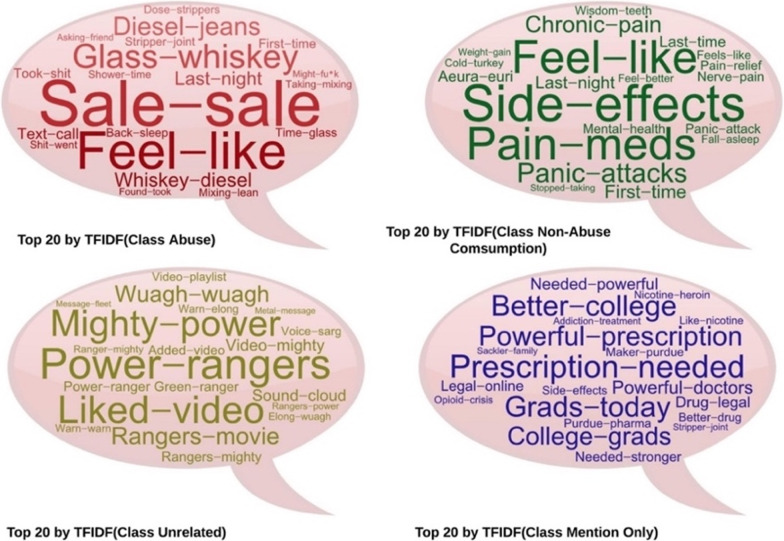
Prescription medication (PM) misuse/abuse has emerged as a national crisis in the United States, and social media has been suggested as a potential resource for performing active monitoring. However, automating a social media-based monitoring system is challenging-requiring advanced natural language processing (NLP) and machine learning methods. In this paper, we describe the development and evaluation of automatic text classification models for detecting self-reports of PM abuse from Twitter.
We experimented with state-of-the-art bi-directional transformer-based language models, which utilize tweet-level representations that enable transfer learning (e.g., BERT, RoBERTa, XLNet, AlBERT, and DistilBERT), proposed fusion-based approaches, and compared the developed models with several traditional machine learning, including deep learning, approaches. Using a public dataset, we evaluated the performances of the classifiers on their abilities to classify the non-majority "abuse/misuse" class.
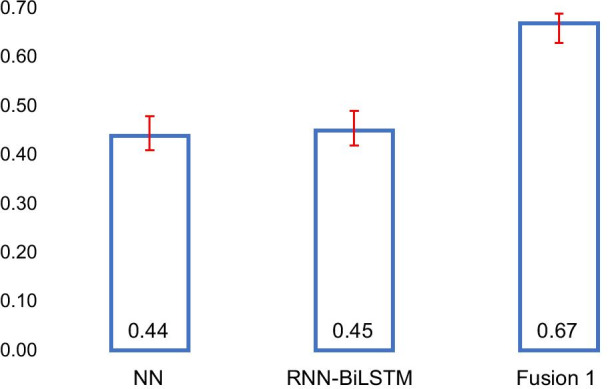
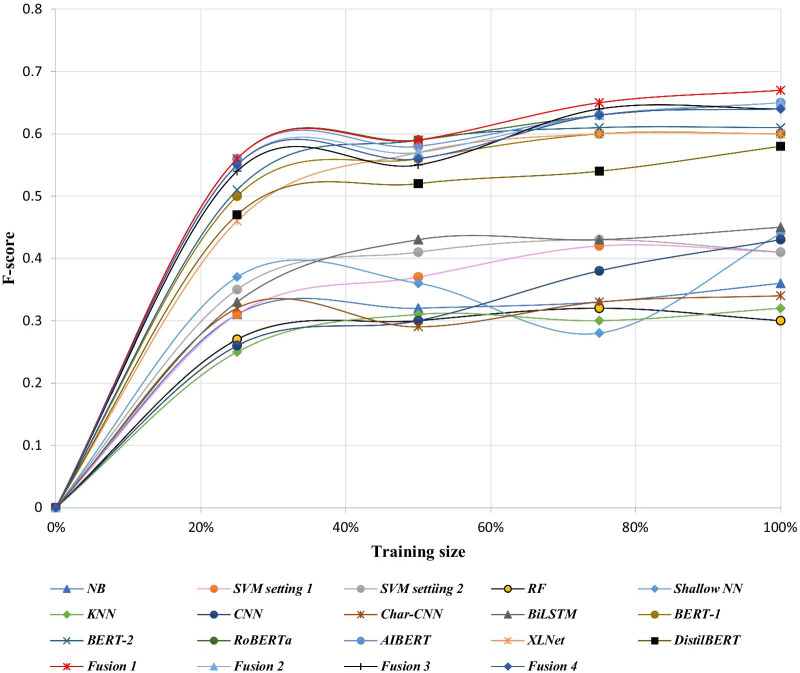
Our proposed fusion-based model performs significantly better than the best traditional model (F-score [95% CI]: 0.67 [0.64-0.69] vs. 0.45 [0.42-0.48]). We illustrate, via experimentation using varying training set sizes, that the transformer-based models are more stable and require less annotated data compared to the other models. The significant improvements achieved by our best-performing classification model over past approaches makes it suitable for automated continuous monitoring of nonmedical PM use from Twitter.
BERT, BERT-like and fusion-based models outperform traditional machine learning and deep learning models, achieving substantial improvements over many years of past research on the topic of prescription medication misuse/abuse classification from social media, which had been shown to be a complex task due to the unique ways in which information about nonmedical use is presented. Several challenges associated with the lack of context and the nature of social media language need to be overcome to further improve BERT and BERT-like models. These experimental driven challenges are represented as potential future research directions.
处方药物(PM)的滥用已成为美国的全国性危机,社交媒体已被提议作为主动监测的潜在资源。然而,自动化社交媒体监测系统具有挑战性,需要先进的自然语言处理(NLP)和机器学习方法。在本文中,我们描述了从 Twitter 检测 PM 滥用自我报告的自动文本分类模型的开发和评估。
我们尝试了基于双向转换器的最先进的语言模型,这些模型利用了能够进行迁移学习的推文级表示(例如 BERT、RoBERTa、XLNet、AlBERT 和 DistilBERT)、提出了基于融合的方法,并将所开发的模型与几种传统机器学习方法(包括深度学习)进行了比较。我们使用公共数据集评估了分类器在分类非主要“滥用/误用”类别的能力。
我们提出的基于融合的模型的性能明显优于最佳传统模型(F 分数[95%置信区间]:0.67[0.64-0.69] 与 0.45[0.42-0.48])。通过使用不同的训练集大小进行实验,我们表明基于转换器的模型比其他模型更稳定,并且需要更少的注释数据。与过去的方法相比,我们表现最佳的分类模型取得的显著改进使其适用于从 Twitter 自动连续监测非医疗 PM 的使用。
BERT、BERT 类模型和基于融合的模型优于传统机器学习和深度学习模型,在过去多年社交媒体上处方药滥用/误用分类的研究中取得了实质性的改进,由于非医疗使用信息呈现的独特方式,该研究被证明是一项复杂的任务。需要克服与缺乏上下文和社交媒体语言性质相关的几个挑战,以进一步改进 BERT 和 BERT 类模型。这些由实验驱动的挑战代表了潜在的未来研究方向。