Raza Shaina, Schwartz Brian, Lakamana Sahithi, Ge Yao, Sarker Abeed
Dalla Lana School of Public Health, University of Toronto, Toronto, ON, Canada.
Vector Institute for Artificial Intelligence, Toronto, ON, Canada.
BMC Digit Health. 2023;1. doi: 10.1186/s44247-023-00029-w. Epub 2023 Aug 7.
Substance use, including the non-medical use of prescription medications, is a global health problem resulting in hundreds of thousands of overdose deaths and other health problems. Social media has emerged as a potent source of information for studying substance use-related behaviours and their consequences. Mining large-scale social media data on the topic requires the development of natural language processing (NLP) and machine learning frameworks customized for this problem. Our objective in this research is to develop a framework for conducting a content analysis of Twitter chatter about the non-medical use of a set of prescription medications.
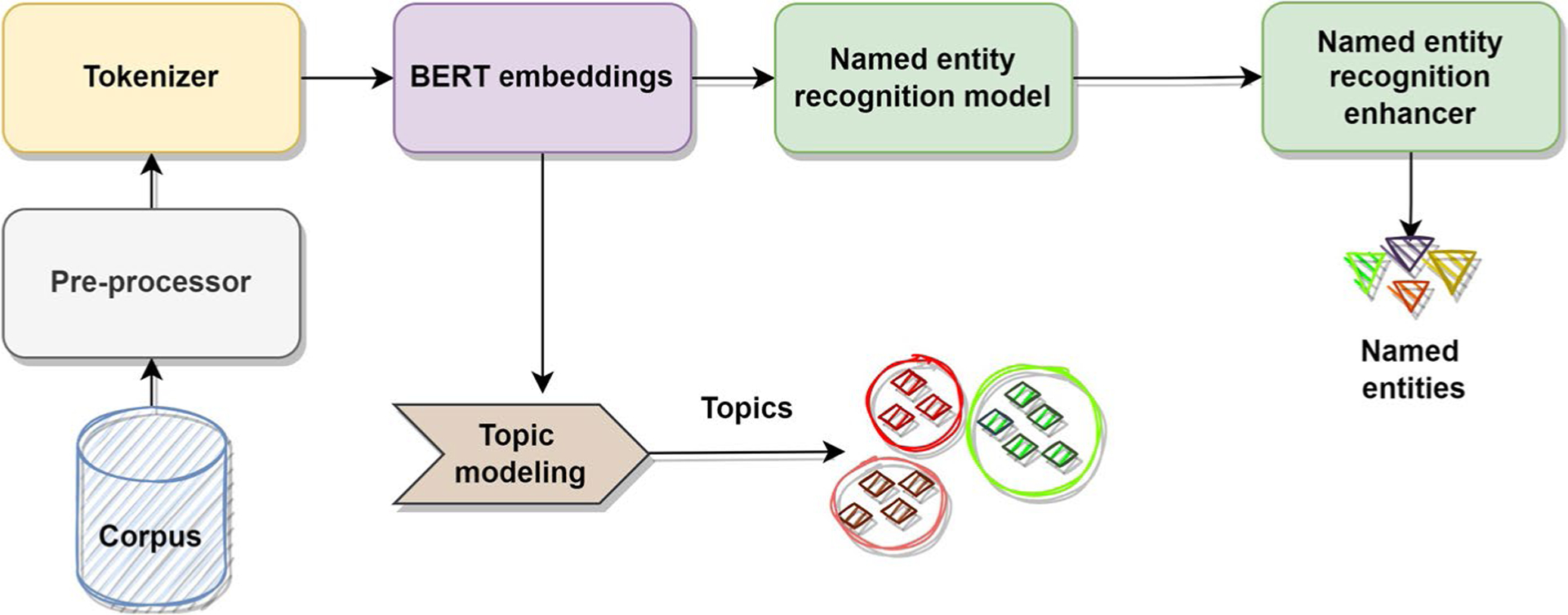
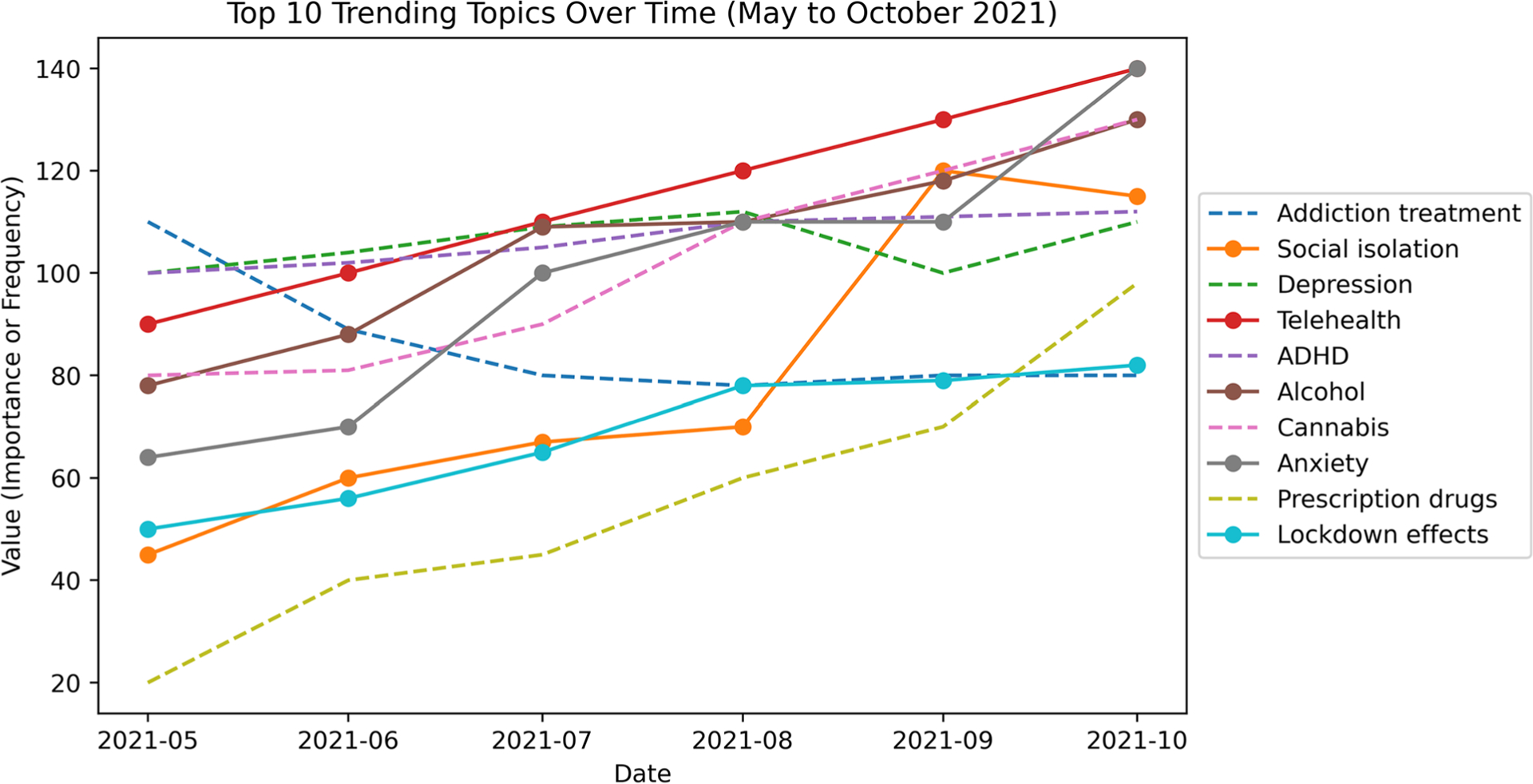
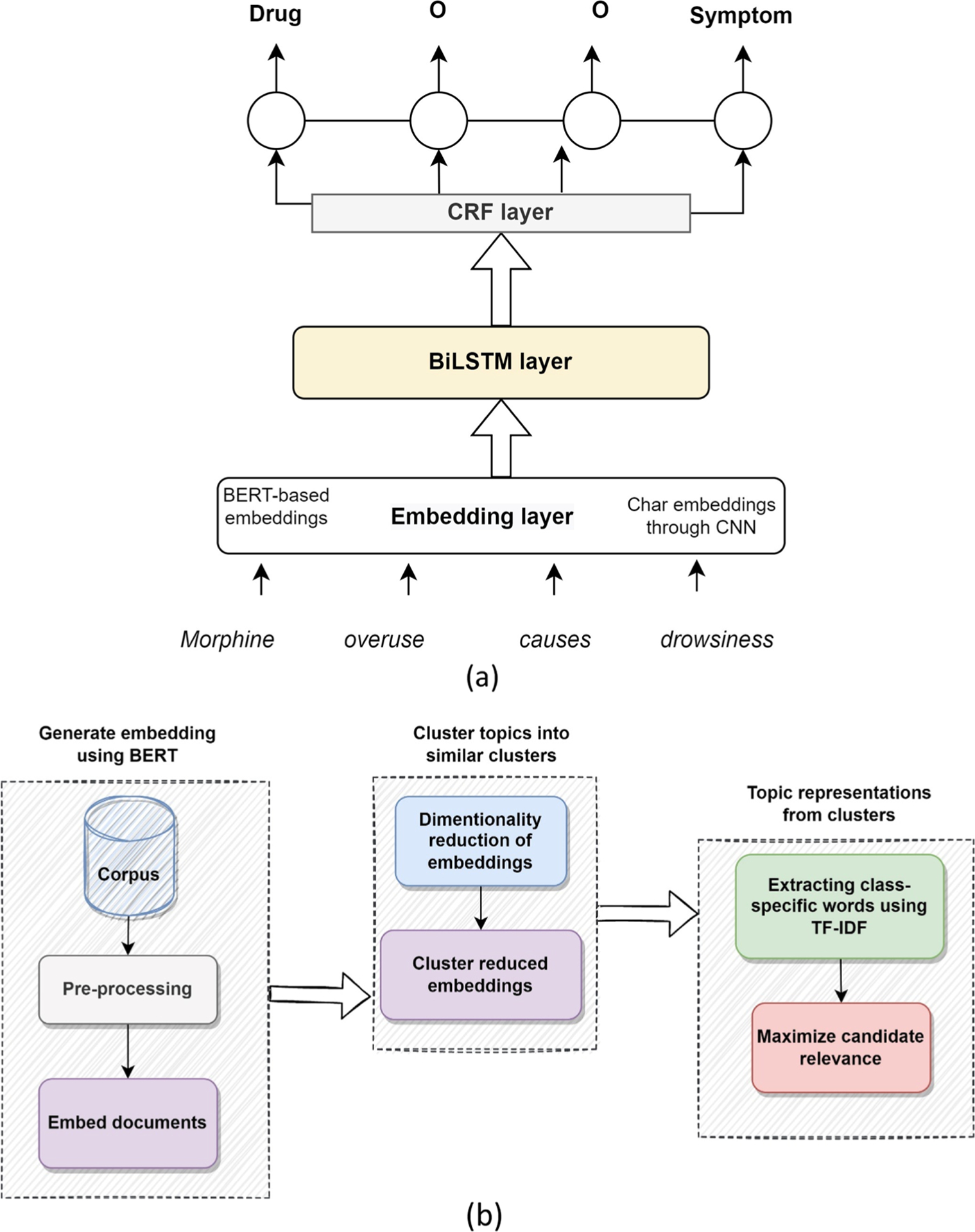
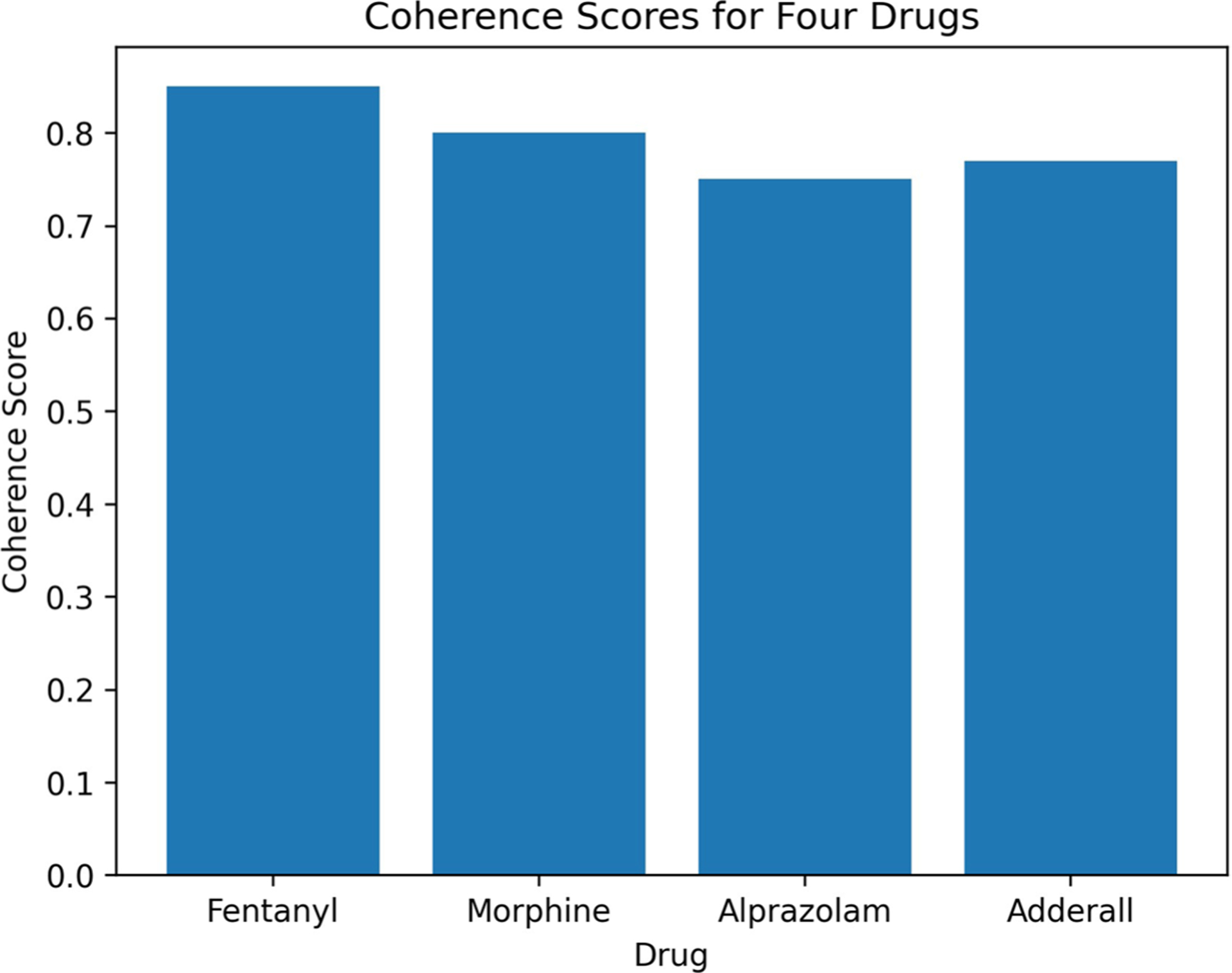
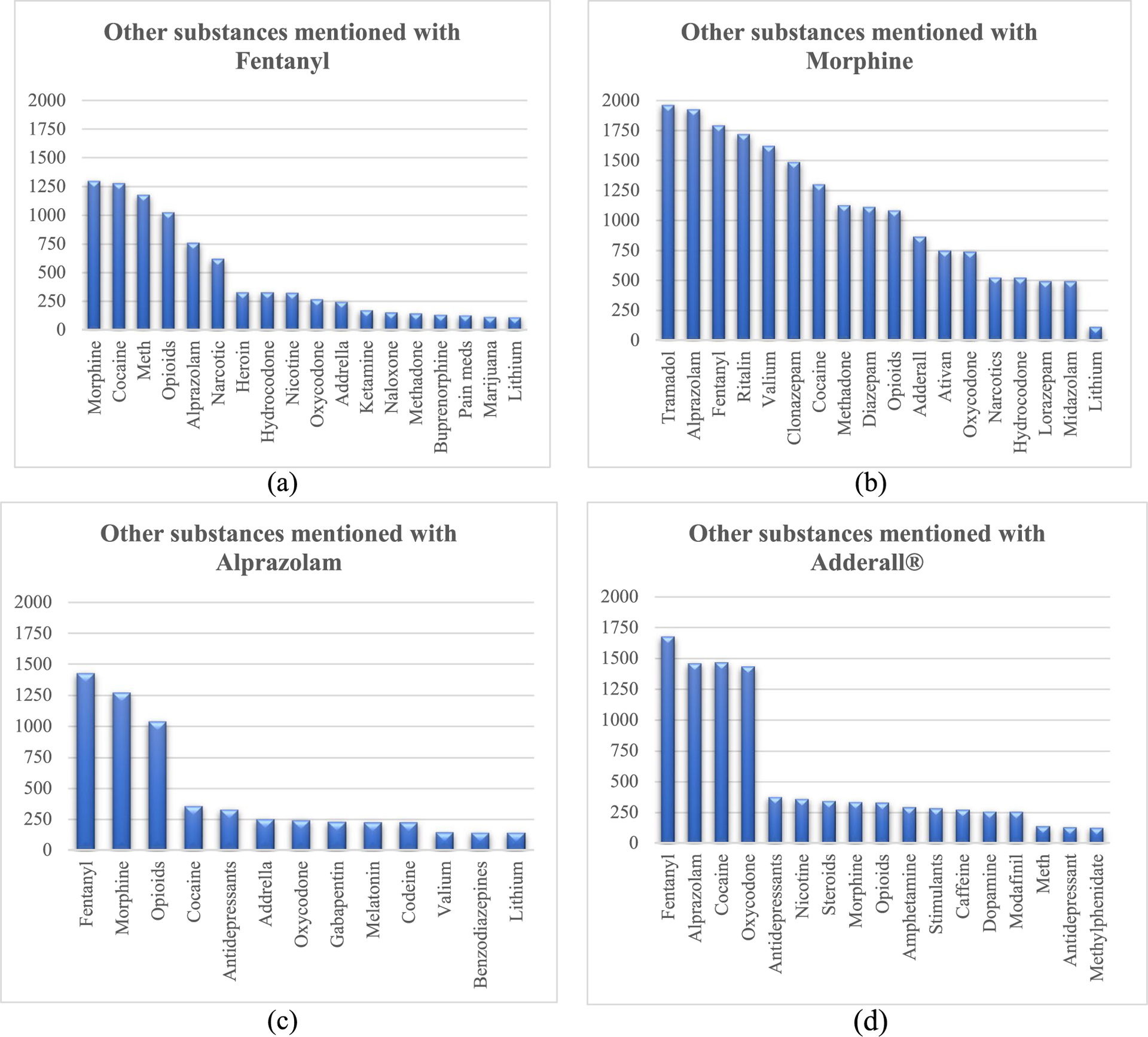
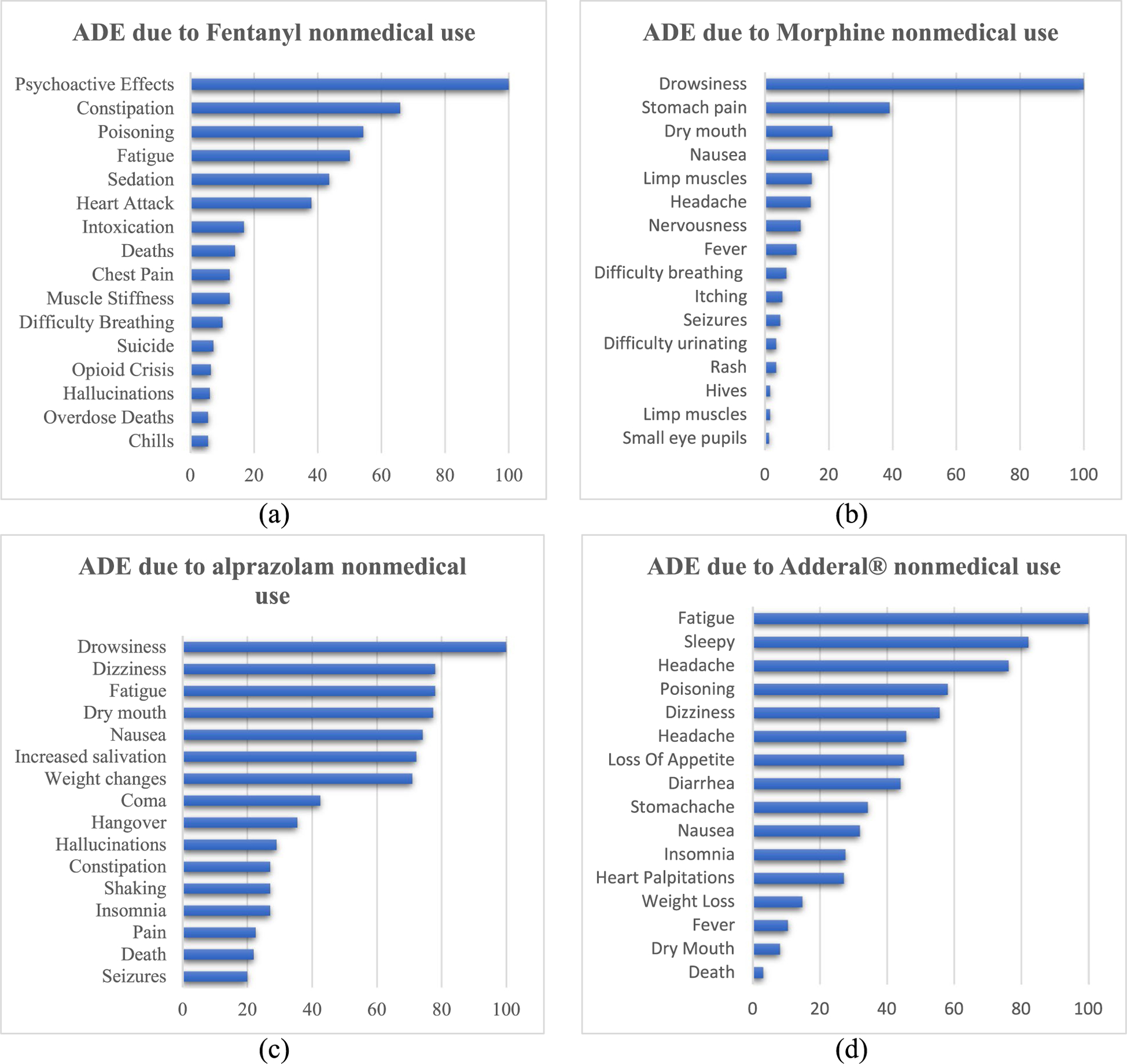
We collected Twitter data for four medications-fentanyl and morphine (opioids), alprazolam (benzodiazepine), and Adderall (stimulant), and identified posts that indicated non-medical use using an automatic machine learning classifier. In our NLP framework, we applied supervised named entity recognition (NER) to identify other substances mentioned, symptoms, and adverse events. We applied unsupervised topic modelling to identify latent topics associated with the chatter for each medication.
The quantitative analysis demonstrated the performance of the proposed NER approach in identifying substance-related entities from data with a high degree of accuracy compared to the baseline methods. The performance evaluation of the topic modelling was also notable. The qualitative analysis revealed knowledge about the use, non-medical use, and side effects of these medications in individuals and communities.
NLP-based analyses of Twitter chatter associated with prescription medications belonging to different categories provide multi-faceted insights about their use and consequences. Our developed framework can be applied to chatter about other substances. Further research can validate the predictive value of this information on the prevention, assessment, and management of these disorders.
物质使用,包括非医疗目的使用处方药,是一个全球性的健康问题,导致数十万例过量用药死亡及其他健康问题。社交媒体已成为研究物质使用相关行为及其后果的有力信息来源。挖掘关于该主题的大规模社交媒体数据需要开发针对此问题定制的自然语言处理(NLP)和机器学习框架。我们这项研究的目的是开发一个框架,用于对推特上有关一组处方药非医疗使用的讨论进行内容分析。
我们收集了四种药物——芬太尼和吗啡(阿片类药物)、阿普唑仑(苯二氮䓬类药物)以及安非他明(兴奋剂)的推特数据,并使用自动机器学习分类器识别表明非医疗使用的帖子。在我们的NLP框架中,我们应用监督式命名实体识别(NER)来识别提及的其他物质、症状和不良事件。我们应用无监督主题建模来识别与每种药物讨论相关的潜在主题。
定量分析表明,与基线方法相比,所提出的NER方法在从数据中高度准确地识别与物质相关的实体方面表现出色。主题建模的性能评估也很显著。定性分析揭示了关于这些药物在个人和社区中的使用、非医疗使用及副作用的知识。
基于NLP对与不同类别处方药相关的推特讨论进行分析,能提供关于其使用和后果的多方面见解。我们开发的框架可应用于关于其他物质的讨论。进一步的研究可以验证这些信息在这些疾病的预防、评估和管理方面的预测价值。