Department of Human Movement Sciences, Vrije Universiteit Amsterdam, 1081 BT, Amsterdam, The Netherlands.
Sci Rep. 2021 Jan 29;11(1):2667. doi: 10.1038/s41598-020-80155-x.
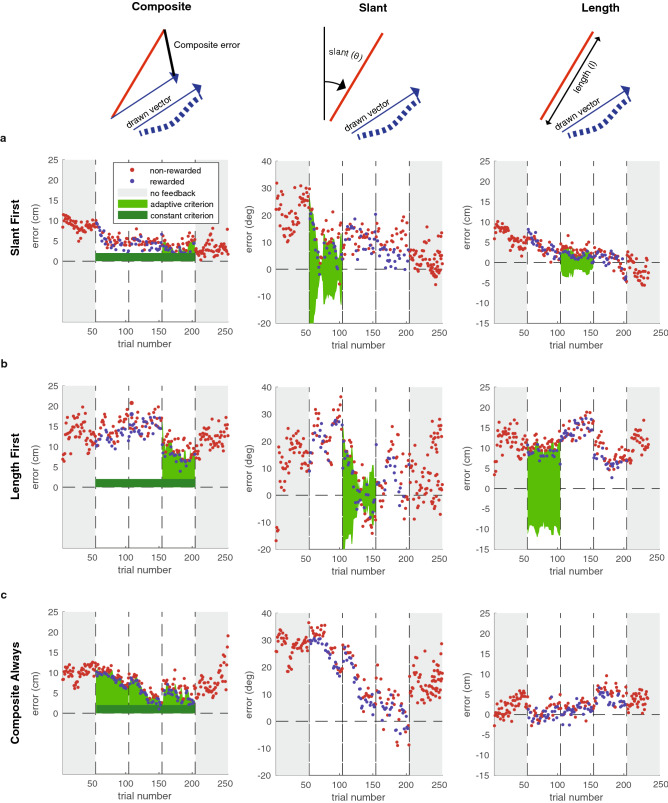
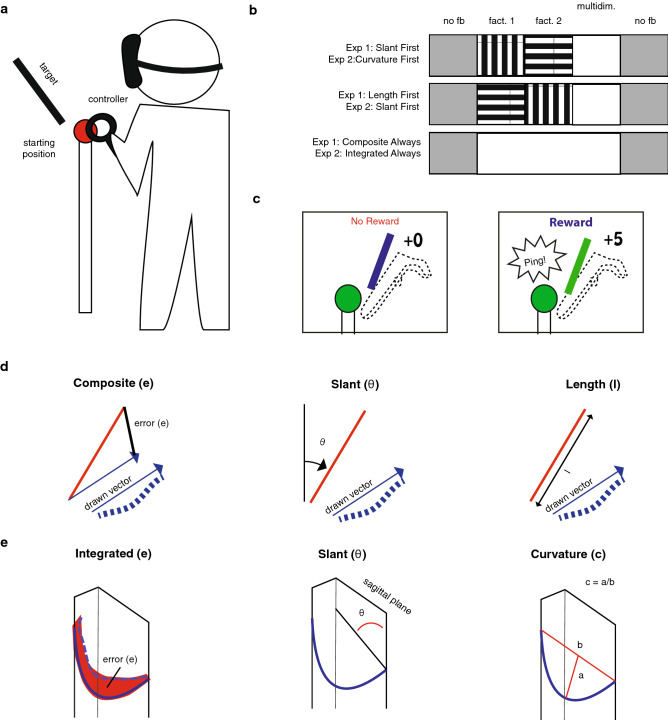
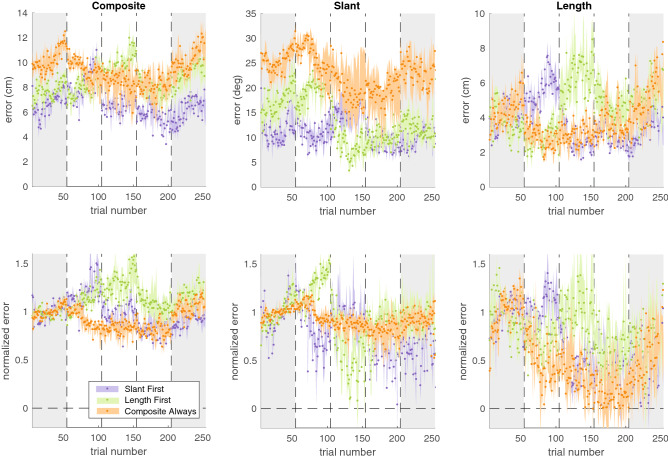
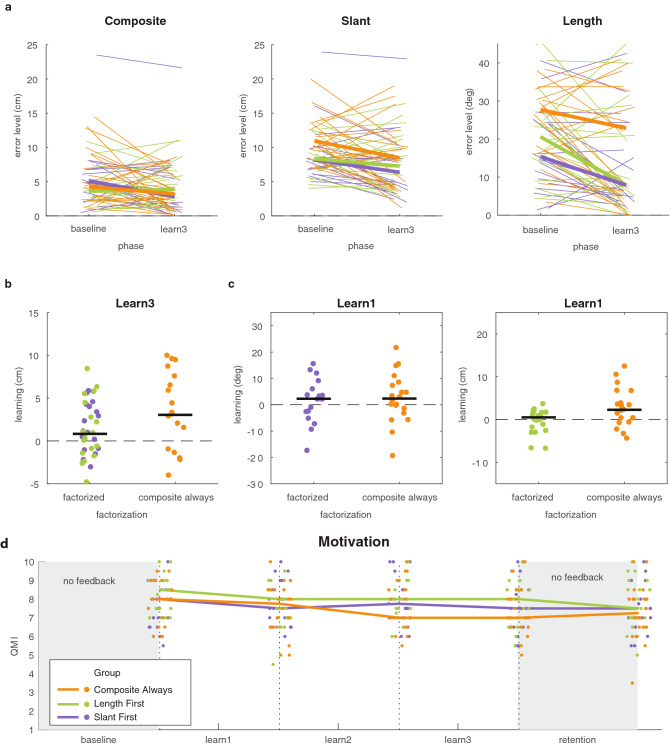
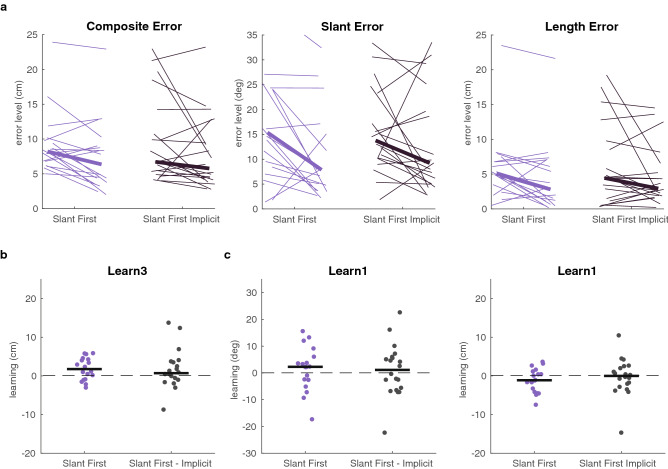
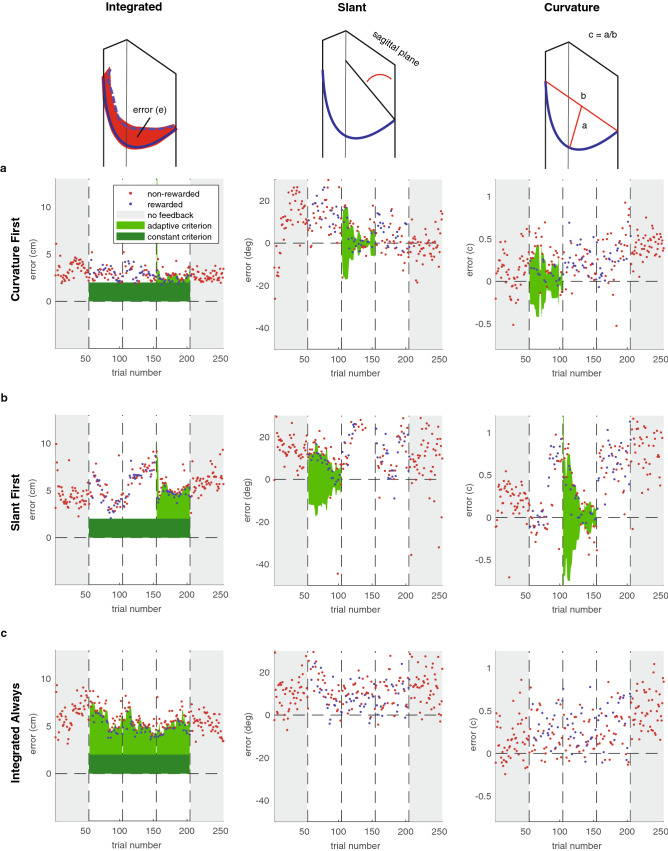
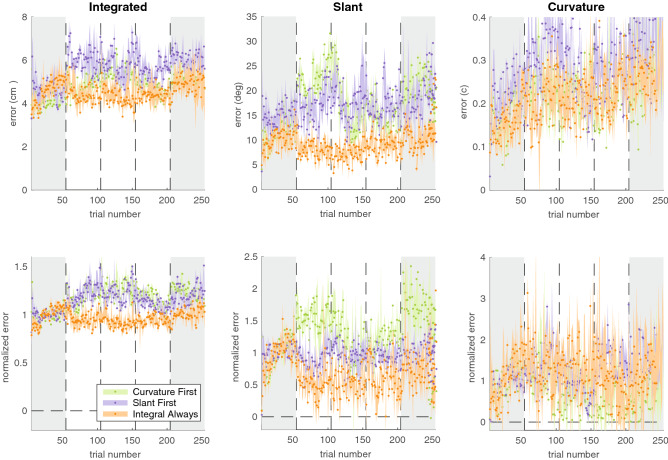
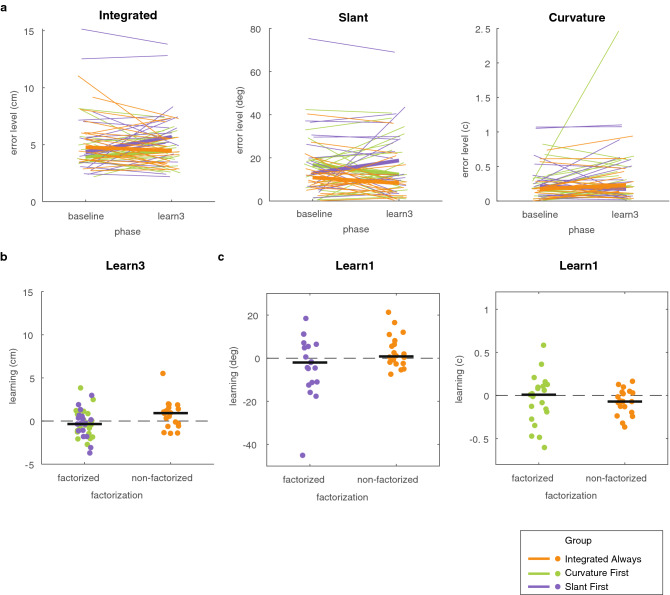
Binary reward feedback on movement success is sufficient for learning some simple sensorimotor mappings in a reaching task, but not for some other tasks in which multiple kinematic factors contribute to performance. The critical condition for learning in more complex tasks remains unclear. Here, we investigate whether reward-based motor learning is possible in a multi-dimensional trajectory matching task and whether simplifying the task by providing feedback on one factor at a time ('factorized feedback') can improve learning. In two experiments, participants performed a trajectory matching task in which learning was measured as a reduction in the error. In Experiment 1, participants matched a straight trajectory slanted in depth. We factorized the task by providing feedback on the slant error, the length error, or on their composite. In Experiment 2, participants matched a curved trajectory, also slanted in depth. In this experiment, we factorized the feedback by providing feedback on the slant error, the curvature error, or on the integral difference between the matched and target trajectory. In Experiment 1, there was anecdotal evidence that participants learnt the multidimensional task. Factorization did not improve learning. In Experiment 2, there was anecdotal evidence the multidimensional task could not be learnt. We conclude that, within a complexity range, multiple kinematic factors can be learnt in parallel.
二进制奖励反馈对运动成功是足够的,用于学习一些简单的感觉运动映射在一个任务中,但不是为其他一些任务,其中多个运动因素对性能有贡献。对于更复杂任务的学习的关键条件仍然不清楚。在这里,我们研究了基于奖励的运动学习是否可能在多维轨迹匹配任务中,以及通过一次提供一个因素的反馈(“因子化反馈”)来简化任务是否可以提高学习效果。在两个实验中,参与者执行了一个轨迹匹配任务,学习效果是通过减少误差来衡量的。在实验 1 中,参与者匹配了一条在深度上倾斜的直线轨迹。我们通过提供倾斜误差、长度误差或它们的综合反馈来对任务进行因子化。在实验 2 中,参与者匹配了一条在深度上也倾斜的曲线轨迹。在这个实验中,我们通过提供倾斜误差、曲率误差或匹配轨迹和目标轨迹之间的积分差的反馈来对反馈进行因子化。在实验 1 中,有一些迹象表明参与者学习了多维任务。因子化并没有提高学习效果。在实验 2 中,有一些迹象表明多维任务无法学习。我们的结论是,在一定的复杂性范围内,可以并行学习多个运动因素。