Department of Medicine, Biomedical Informatics, Stanford University, Stanford, CA, United States.
Intermountain Health, Salt Lake City, UT, United States.
J Med Internet Res. 2021 Feb 22;23(2):e23026. doi: 10.2196/23026.
For the clinical care of patients with well-established diseases, randomized trials, literature, and research are supplemented with clinical judgment to understand disease prognosis and inform treatment choices. In the void created by a lack of clinical experience with COVID-19, artificial intelligence (AI) may be an important tool to bolster clinical judgment and decision making. However, a lack of clinical data restricts the design and development of such AI tools, particularly in preparation for an impending crisis or pandemic.
This study aimed to develop and test the feasibility of a "patients-like-me" framework to predict the deterioration of patients with COVID-19 using a retrospective cohort of patients with similar respiratory diseases.
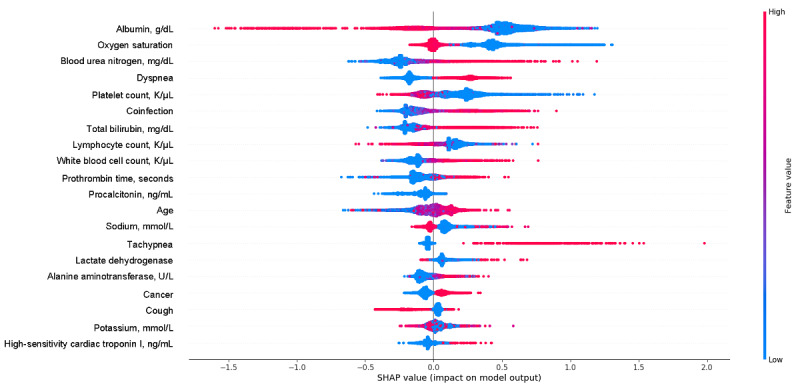
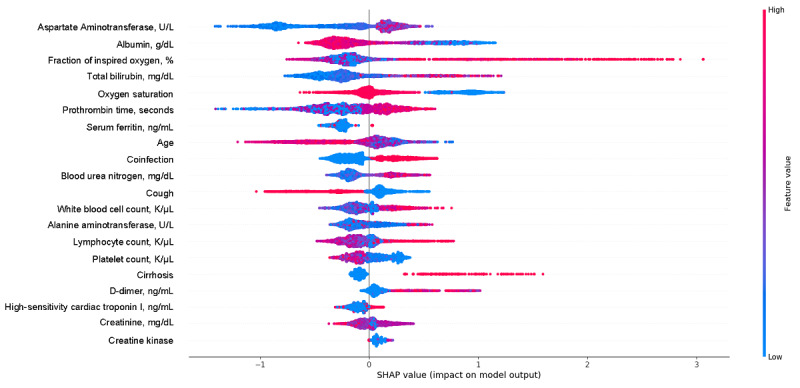
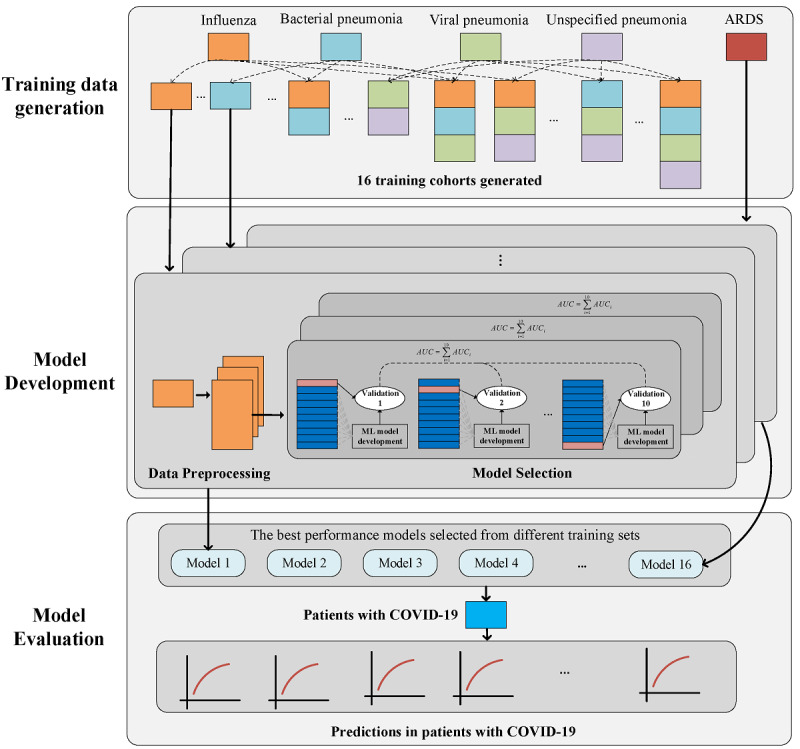
Our framework used COVID-19-like cohorts to design and train AI models that were then validated on the COVID-19 population. The COVID-19-like cohorts included patients diagnosed with bacterial pneumonia, viral pneumonia, unspecified pneumonia, influenza, and acute respiratory distress syndrome (ARDS) at an academic medical center from 2008 to 2019. In total, 15 training cohorts were created using different combinations of the COVID-19-like cohorts with the ARDS cohort for exploratory purposes. In this study, two machine learning models were developed: one to predict invasive mechanical ventilation (IMV) within 48 hours for each hospitalized day, and one to predict all-cause mortality at the time of admission. Model performance was assessed using the area under the receiver operating characteristic curve (AUROC), sensitivity, specificity, positive predictive value, and negative predictive value. We established model interpretability by calculating SHapley Additive exPlanations (SHAP) scores to identify important features.
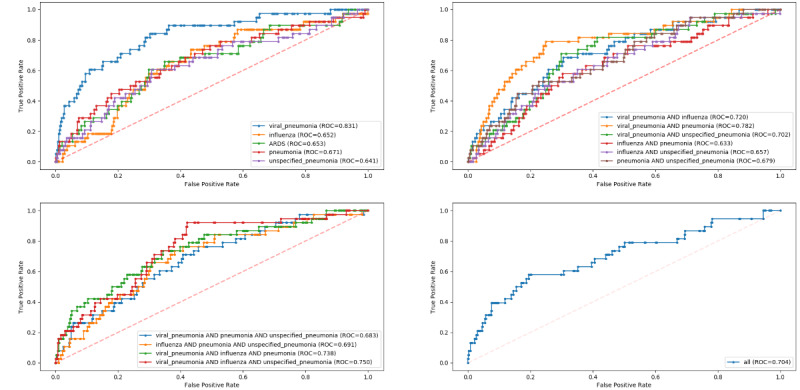
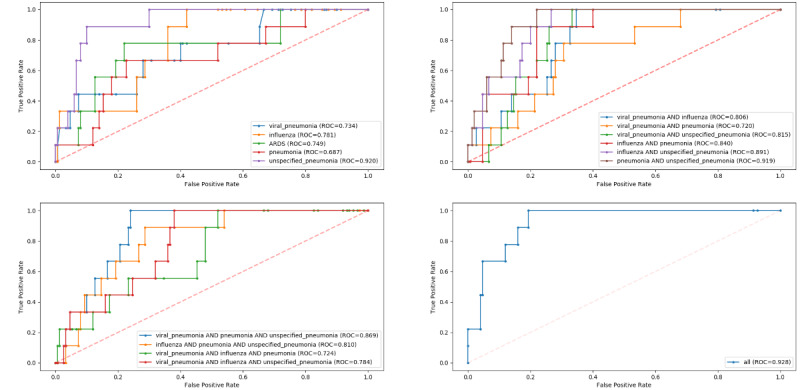
Compared to the COVID-19-like cohorts (n=16,509), the patients hospitalized with COVID-19 (n=159) were significantly younger, with a higher proportion of patients of Hispanic ethnicity, a lower proportion of patients with smoking history, and fewer patients with comorbidities (P<.001). Patients with COVID-19 had a lower IMV rate (15.1 versus 23.2, P=.02) and shorter time to IMV (2.9 versus 4.1 days, P<.001) compared to the COVID-19-like patients. In the COVID-19-like training data, the top models achieved excellent performance (AUROC>0.90). Validating in the COVID-19 cohort, the top-performing model for predicting IMV was the XGBoost model (AUROC=0.826) trained on the viral pneumonia cohort. Similarly, the XGBoost model trained on all 4 COVID-19-like cohorts without ARDS achieved the best performance (AUROC=0.928) in predicting mortality. Important predictors included demographic information (age), vital signs (oxygen saturation), and laboratory values (white blood cell count, cardiac troponin, albumin, etc). Our models had class imbalance, which resulted in high negative predictive values and low positive predictive values.
We provided a feasible framework for modeling patient deterioration using existing data and AI technology to address data limitations during the onset of a novel, rapidly changing pandemic.
对于已确立疾病的患者临床护理,随机试验、文献和研究补充了临床判断,以了解疾病预后并为治疗选择提供信息。在缺乏 COVID-19 临床经验的情况下,人工智能 (AI) 可能是增强临床判断和决策的重要工具。然而,临床数据的缺乏限制了此类 AI 工具的设计和开发,特别是在为即将到来的危机或大流行做准备时。
本研究旨在开发和测试“与我相似的患者”框架的可行性,该框架使用类似于 COVID-19 的队列来预测 COVID-19 患者的病情恶化,使用具有类似呼吸系统疾病的患者的回顾性队列进行预测。
我们的框架使用 COVID-19 样本来设计和训练 AI 模型,然后在 COVID-19 人群中进行验证。COVID-19 样本人群包括 2008 年至 2019 年在学术医疗中心诊断为细菌性肺炎、病毒性肺炎、未明确肺炎、流感和急性呼吸窘迫综合征 (ARDS) 的患者。总共使用 COVID-19 样本人群的不同组合与 ARDS 队列创建了 15 个训练队列,用于探索目的。在这项研究中,开发了两种机器学习模型:一种用于预测每个住院日的 48 小时内需要进行有创机械通气 (IMV),另一种用于预测入院时的全因死亡率。使用接收器操作特征曲线下的面积 (AUROC)、敏感性、特异性、阳性预测值和阴性预测值评估模型性能。我们通过计算 Shapley Additive exPlanations (SHAP) 分数来建立模型可解释性,以确定重要特征。
与 COVID-19 样本人群 (n=16,509) 相比,COVID-19 住院患者 (n=159) 明显更年轻,具有更高比例的西班牙裔患者,更低比例的吸烟史患者,以及更少的合并症患者 (P<.001)。与 COVID-19 样本人群相比,COVID-19 患者的 IMV 发生率 (15.1% vs 23.2%,P=.02) 和 IMV 时间 (2.9 天 vs 4.1 天,P<.001) 均较低。在 COVID-19 样本人群的训练数据中,顶级模型表现出色(AUROC>0.90)。在 COVID-19 队列中验证时,在病毒性肺炎队列上训练的 XGBoost 模型(AUROC=0.826)是预测 IMV 的最佳模型。同样,在没有 ARDS 的所有 4 个 COVID-19 样本人群上训练的 XGBoost 模型在预测死亡率方面表现最佳(AUROC=0.928)。重要的预测因素包括人口统计学信息(年龄)、生命体征(血氧饱和度)和实验室值(白细胞计数、肌钙蛋白、白蛋白等)。我们的模型存在类别不平衡,导致阳性预测值低而阴性预测值高。
我们提供了一种使用现有数据和人工智能技术建模患者恶化的可行框架,以解决新型快速变化的大流行开始时的数据限制。