Alshahrani Mona, Thafar Maha A, Essack Magbubah
Department of Computer Science and Engineering, Jubail University College, Jubail, Saudi Arabia.
Computer, Electrical and Mathematical Sciences and Engineering Division (CEMSE), Computational Bioscience Research Center (CBRC), King Abdullah University of Science and Technology (KAUST), Thuwal, Saudi Arabia.
PeerJ Comput Sci. 2021 Feb 18;7:e341. doi: 10.7717/peerj-cs.341. eCollection 2021.
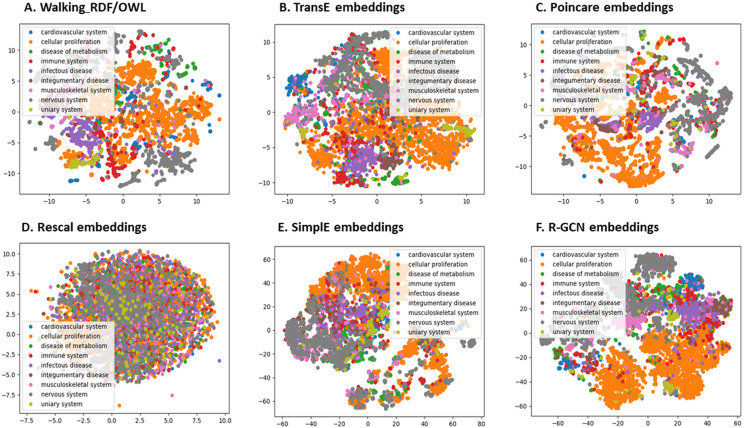
Linked data and bio-ontologies enabling knowledge representation, standardization, and dissemination are an integral part of developing biological and biomedical databases. That is, linked data and bio-ontologies are employed in databases to maintain data integrity, data organization, and to empower search capabilities. However, linked data and bio-ontologies are more recently being used to represent information as multi-relational heterogeneous graphs, "knowledge graphs". The reason being, entities and relations in the knowledge graph can be represented as embedding vectors in semantic space, and these embedding vectors have been used to predict relationships between entities. Such knowledge graph embedding methods provide a practical approach to data analytics and increase chances of building machine learning models with high prediction accuracy that can enhance decision support systems. Here, we present a comparative assessment and a standard benchmark for knowledge graph-based representation learning methods focused on the link prediction task for biological relations. We systematically investigated and compared state-of-the-art embedding methods based on the design settings used for training and evaluation. We further tested various strategies aimed at controlling the amount of information related to each relation in the knowledge graph and its effects on the final performance. We also assessed the quality of the knowledge graph features through clustering and visualization and employed several evaluation metrics to examine their uses and differences. Based on this systematic comparison and assessments, we identify and discuss the limitations of knowledge graph-based representation learning methods and suggest some guidelines for the development of more improved methods.
链接数据和生物本体能够实现知识表示、标准化及传播,是生物和生物医学数据库开发不可或缺的一部分。也就是说,数据库中采用链接数据和生物本体来维护数据完整性、数据组织并增强搜索能力。然而,链接数据和生物本体最近更多地被用于将信息表示为多关系异构图,即“知识图”。原因在于,知识图中的实体和关系可表示为语义空间中的嵌入向量,且这些嵌入向量已被用于预测实体之间的关系。此类知识图嵌入方法为数据分析提供了一种实用途径,并增加了构建具有高预测准确性的机器学习模型的机会,而这些模型能够增强决策支持系统。在此,我们针对专注于生物关系链接预测任务的基于知识图的表示学习方法,给出了一项比较评估和一个标准基准。我们基于用于训练和评估的设计设置,系统地研究并比较了当前最先进的嵌入方法。我们进一步测试了各种旨在控制与知识图中每个关系相关的信息量及其对最终性能影响的策略。我们还通过聚类和可视化评估了知识图特征的质量,并采用了多个评估指标来检验它们的用途和差异。基于这一系统的比较和评估,我们识别并讨论了基于知识图的表示学习方法的局限性,并为开发更完善的方法提出了一些指导原则。