Center for Molecular Microscopy, Center for Cancer Research, National Cancer Institute, National Institutes of Health, Bethesda, United States.
Cancer Research Technology Program, Frederick National Laboratory for Cancer Research, Frederick, United States.
Elife. 2021 Apr 8;10:e65894. doi: 10.7554/eLife.65894.
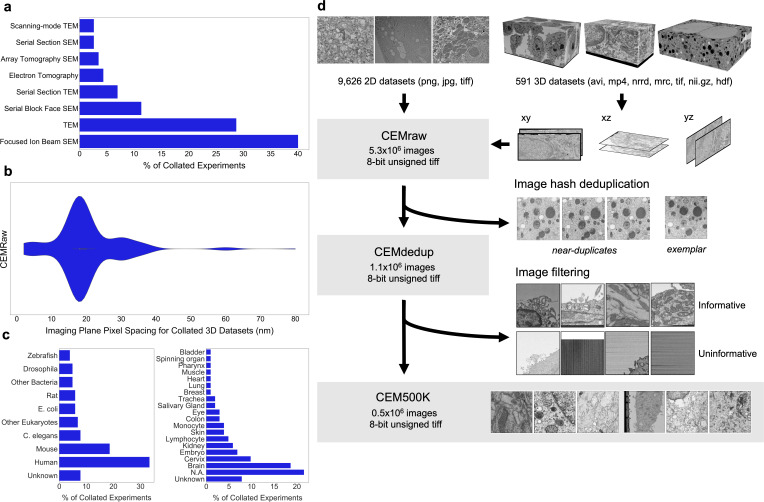
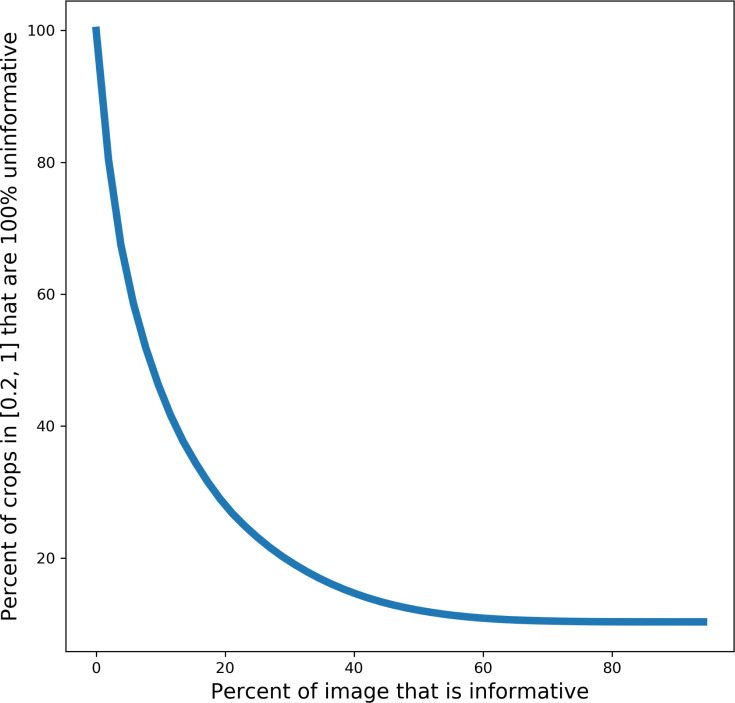
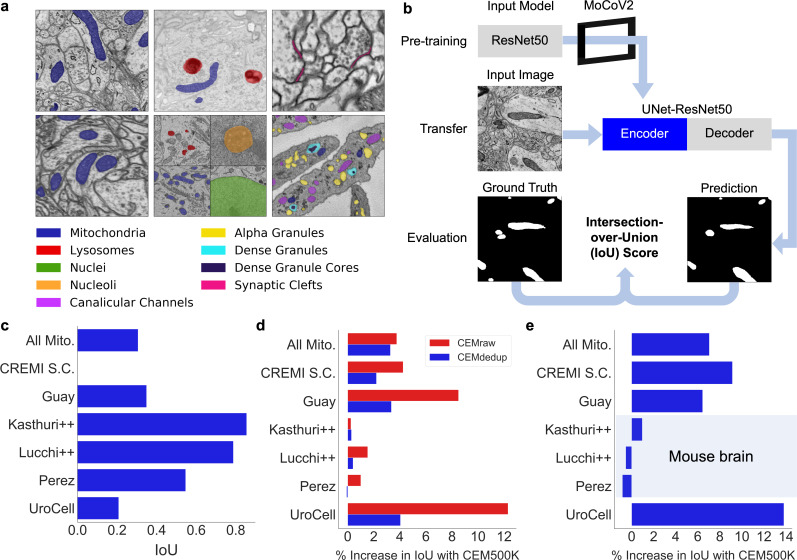
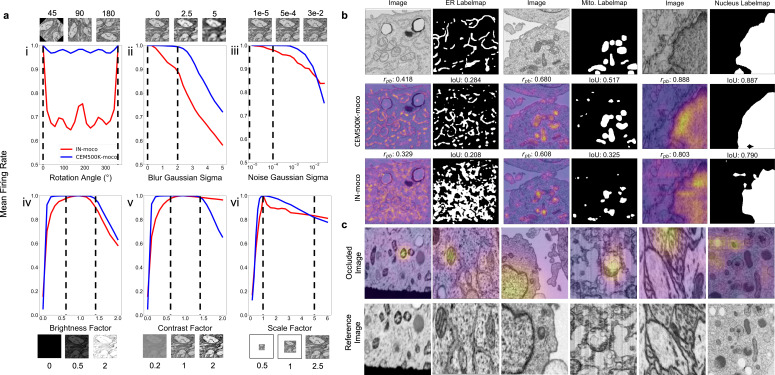
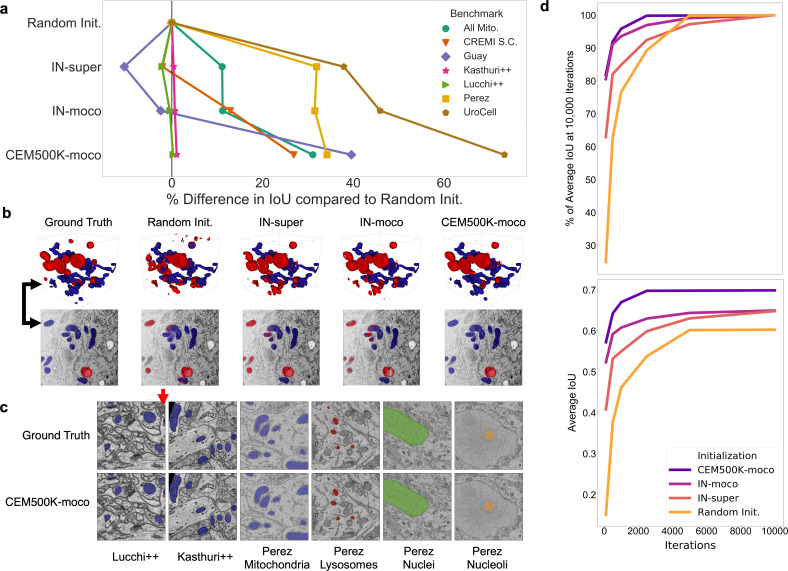
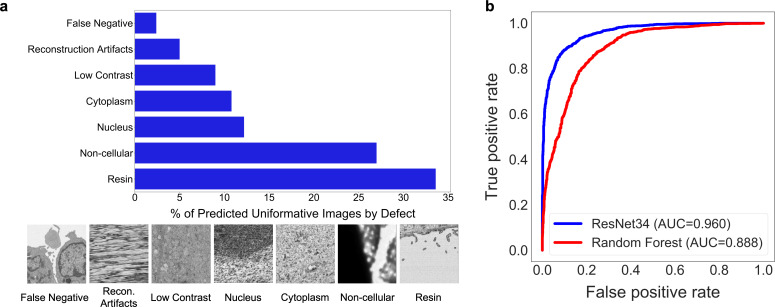
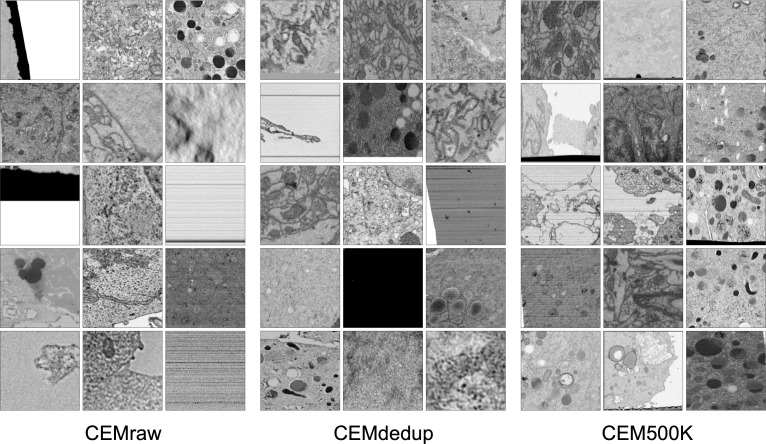
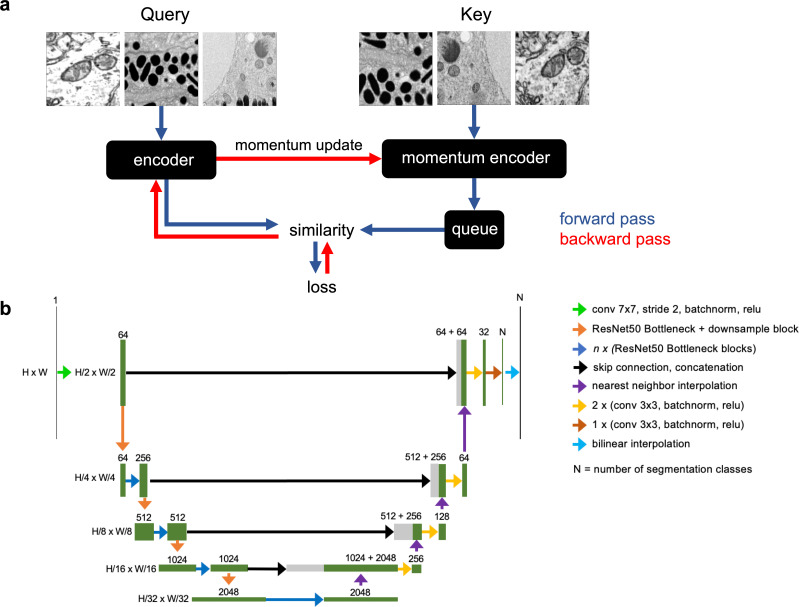
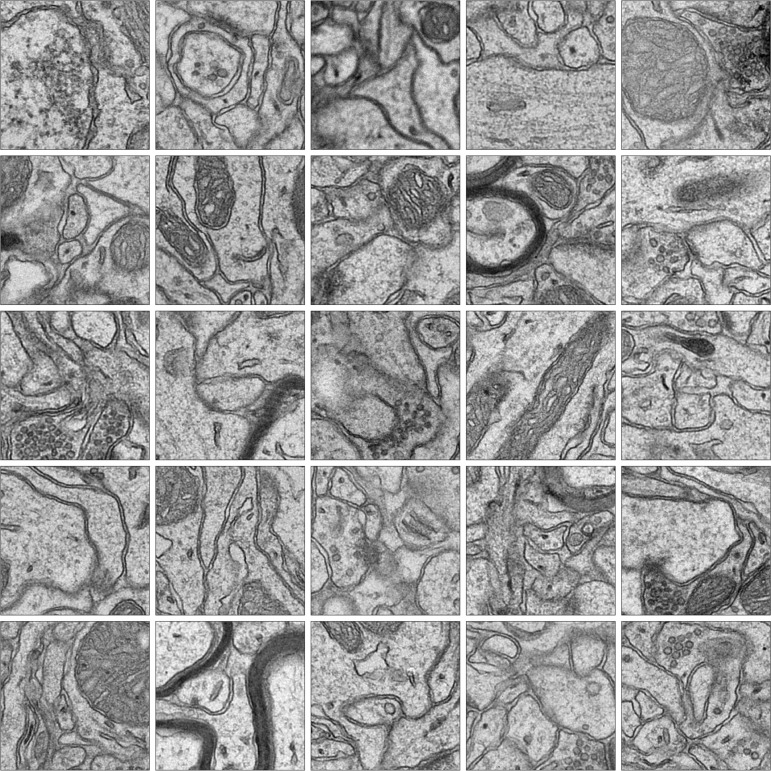
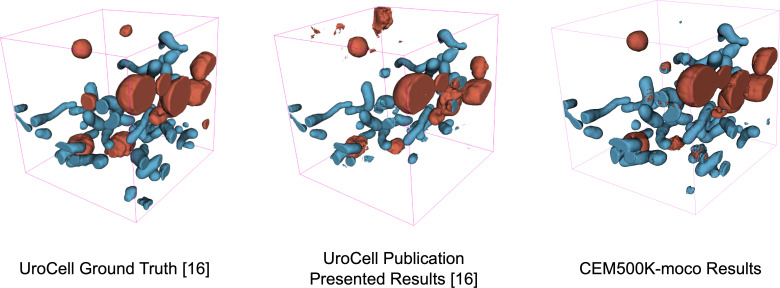
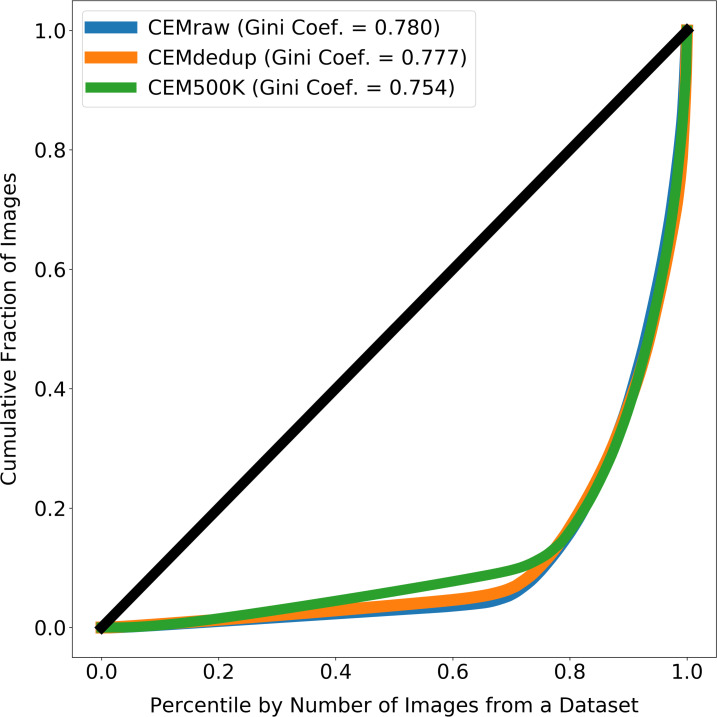
Automated segmentation of cellular electron microscopy (EM) datasets remains a challenge. Supervised deep learning (DL) methods that rely on region-of-interest (ROI) annotations yield models that fail to generalize to unrelated datasets. Newer unsupervised DL algorithms require relevant pre-training images, however, pre-training on currently available EM datasets is computationally expensive and shows little value for unseen biological contexts, as these datasets are large and homogeneous. To address this issue, we present CEM500K, a nimble 25 GB dataset of 0.5 × 10 unique 2D cellular EM images curated from nearly 600 three-dimensional (3D) and 10,000 two-dimensional (2D) images from >100 unrelated imaging projects. We show that models pre-trained on CEM500K learn features that are biologically relevant and resilient to meaningful image augmentations. Critically, we evaluate transfer learning from these pre-trained models on six publicly available and one newly derived benchmark segmentation task and report state-of-the-art results on each. We release the CEM500K dataset, pre-trained models and curation pipeline for model building and further expansion by the EM community. Data and code are available at https://www.ebi.ac.uk/pdbe/emdb/empiar/entry/10592/ and https://git.io/JLLTz.
细胞电子显微镜 (EM) 数据集的自动分割仍然是一个挑战。依赖于感兴趣区域 (ROI) 注释的监督深度学习 (DL) 方法生成的模型无法推广到不相关的数据集。较新的无监督 DL 算法需要相关的预训练图像,但是,在当前可用的 EM 数据集上进行预训练在计算上是昂贵的,并且对于看不见的生物背景几乎没有价值,因为这些数据集很大且同质。为了解决这个问题,我们提出了 CEM500K,这是一个灵活的 25GB 数据集,包含 0.5×10 个独特的 2D 细胞 EM 图像,这些图像是从近 600 个 3D 和 10000 个 2D 图像中提取出来的,这些图像来自于 >100 个不相关的成像项目。我们表明,在 CEM500K 上预训练的模型学习到的特征是具有生物学意义的,并且对有意义的图像增强具有弹性。至关重要的是,我们评估了这些预训练模型在六个公开可用的和一个新衍生的基准分割任务中的迁移学习,并在每个任务上报告了最先进的结果。我们发布了 CEM500K 数据集、预训练模型和模型构建的策展管道,以供 EM 社区进一步扩展。数据和代码可在 https://www.ebi.ac.uk/pdbe/emdb/empiar/entry/10592/ 和 https://git.io/JLLTz 获得。