Yoo Seungyeul, Shi Zhiao, Wen Bo, Kho SoonJye, Pan Renke, Feng Hanying, Chen Hong, Carlsson Anders, Edén Patrik, Ma Weiping, Raymer Michael, Maier Ezekiel J, Tezak Zivana, Johanson Elaine, Hinton Denise, Rodriguez Henry, Zhu Jun, Boja Emily, Wang Pei, Zhang Bing
Department of Genetics and Genomic Sciences, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA.
Icahn Institute for Data Science and Genomic Technology, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA.
Patterns (N Y). 2021 May 7;2(5):100245. doi: 10.1016/j.patter.2021.100245. eCollection 2021 May 14.
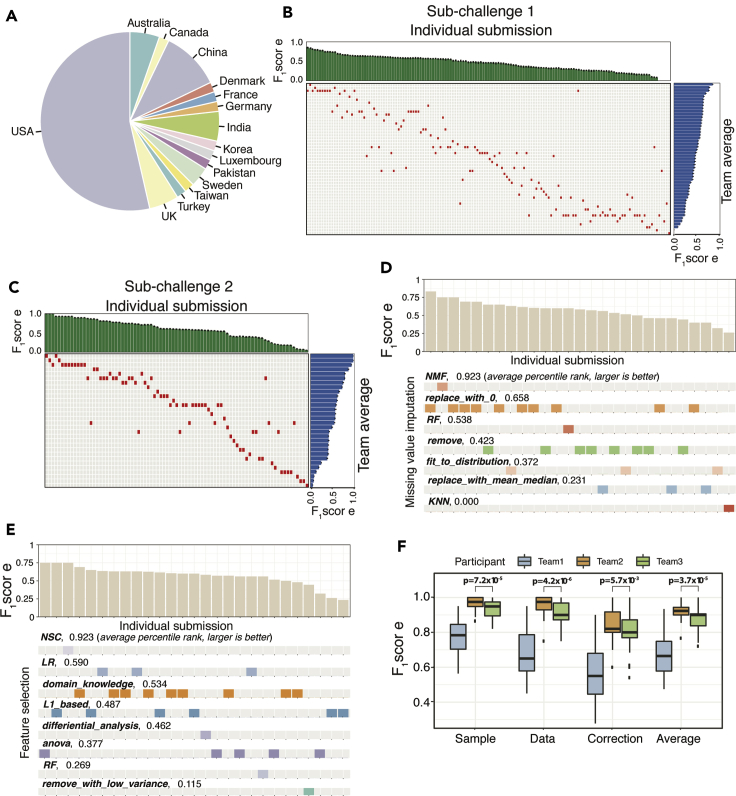
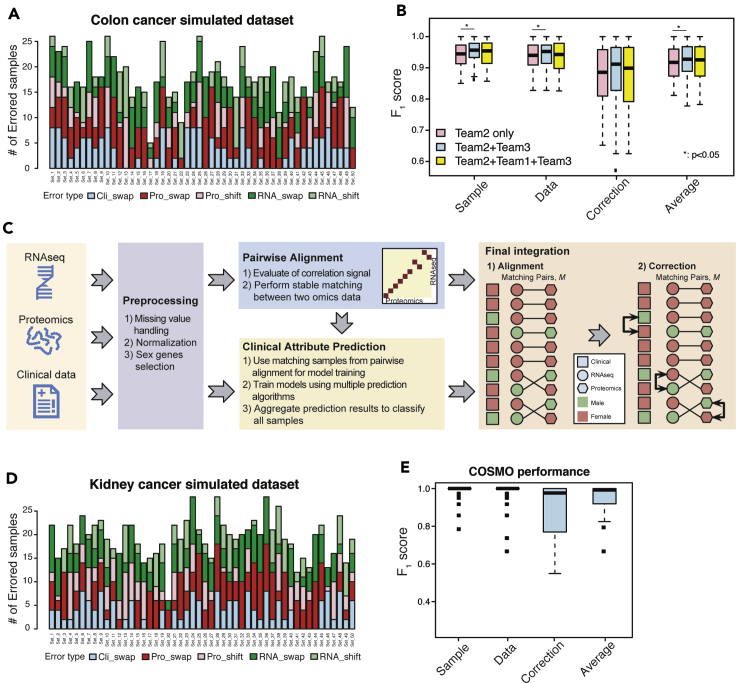
Sample mislabeling or misannotation has been a long-standing problem in scientific research, particularly prevalent in large-scale, multi-omic studies due to the complexity of multi-omic workflows. There exists an urgent need for implementing quality controls to automatically screen for and correct sample mislabels or misannotations in multi-omic studies. Here, we describe a crowdsourced precisionFDA NCI-CPTAC Multi-omics Enabled Sample Mislabeling Correction Challenge, which provides a framework for systematic benchmarking and evaluation of mislabel identification and correction methods for integrative proteogenomic studies. The challenge received a large number of submissions from domestic and international data scientists, with highly variable performance observed across the submitted methods. Post-challenge collaboration between the top-performing teams and the challenge organizers has created an open-source software, COSMO, with demonstrated high accuracy and robustness in mislabeling identification and correction in simulated and real multi-omic datasets.
样本标记错误或注释错误一直是科学研究中的一个长期问题,由于多组学工作流程的复杂性,在大规模多组学研究中尤为普遍。迫切需要实施质量控制,以自动筛选和纠正多组学研究中的样本标记错误或注释错误。在此,我们描述了一个众包的precisionFDA NCI-CPTAC多组学样本标记错误校正挑战,该挑战为综合蛋白质基因组学研究的错误标记识别和校正方法提供了系统的基准测试和评估框架。该挑战收到了来自国内外数据科学家的大量提交内容,提交的方法表现出很大的差异。顶级团队与挑战组织者在挑战后的合作开发了一个开源软件COSMO,该软件在模拟和真实多组学数据集中的错误标记识别和校正方面表现出了很高的准确性和稳健性。