The CardioVascular Center Tufts Medical Center Boston MA.
Medical Faculty Heinrich Heine University Düsseldorf Germany.
J Am Heart Assoc. 2021 Jul 20;10(14):e020085. doi: 10.1161/JAHA.120.020085. Epub 2021 Jul 6.
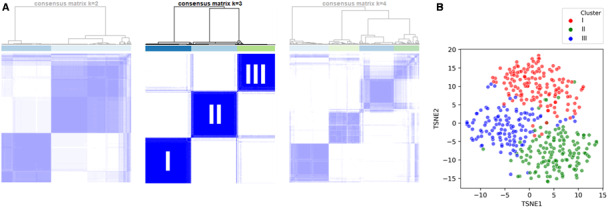
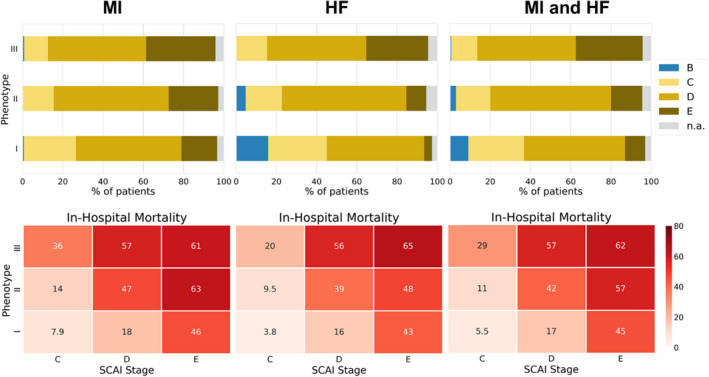
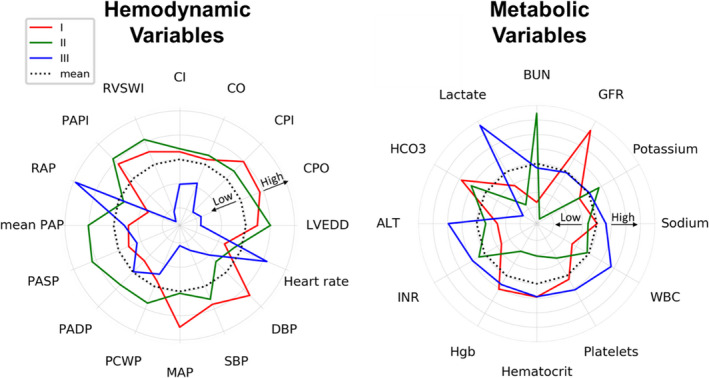
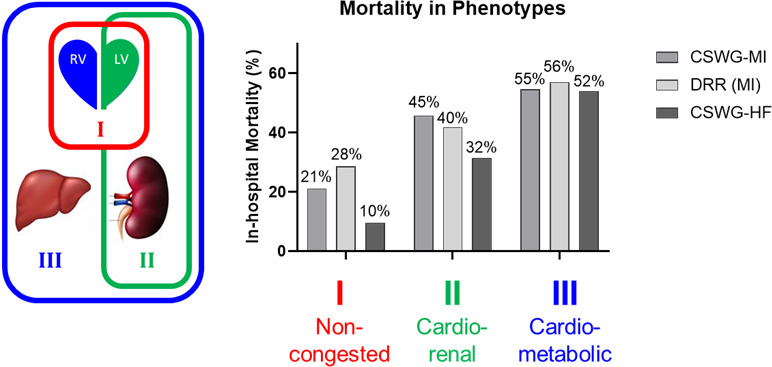
Background Cardiogenic shock (CS) is a heterogeneous syndrome with varied presentations and outcomes. We used a machine learning approach to test the hypothesis that patients with CS have distinct phenotypes at presentation, which are associated with unique clinical profiles and in-hospital mortality. Methods and Results We analyzed data from 1959 patients with CS from 2 international cohorts: CSWG (Cardiogenic Shock Working Group Registry) (myocardial infarction [CSWG-MI; n=410] and acute-on-chronic heart failure [CSWG-HF; n=480]) and the DRR (Danish Retroshock MI Registry) (n=1069). Clusters of patients with CS were identified in CSWG-MI using the consensus k means algorithm and subsequently validated in CSWG-HF and DRR. Patients in each phenotype were further categorized by their Society of Cardiovascular Angiography and Interventions staging. The machine learning algorithms revealed 3 distinct clusters in CS: "non-congested (I)", "cardiorenal (II)," and "cardiometabolic (III)" shock. Among the 3 cohorts (CSWG-MI versus DDR versus CSWG-HF), in-hospital mortality was 21% versus 28% versus 10%, 45% versus 40% versus 32%, and 55% versus 56% versus 52% for clusters I, II, and III, respectively. The "cardiometabolic shock" cluster had the highest risk of developing stage D or E shock as well as in-hospital mortality among the phenotypes, regardless of cause. Despite baseline differences, each cluster showed reproducible demographic, metabolic, and hemodynamic profiles across the 3 cohorts. Conclusions Using machine learning, we identified and validated 3 distinct CS phenotypes, with specific and reproducible associations with mortality. These phenotypes may allow for targeted patient enrollment in clinical trials and foster development of tailored treatment strategies in subsets of patients with CS.
背景 心原性休克(CS)是一种表现和结局多样的异质性综合征。我们采用机器学习方法检验了以下假设,即 CS 患者在就诊时具有不同的表型,这些表型与独特的临床特征和院内死亡率相关。
方法和结果 我们分析了来自 2 个国际队列的 1959 例 CS 患者的数据:CSWG(心原性休克工作组注册)(心肌梗死 [CSWG-MI;n=410] 和急性加重的慢性心力衰竭 [CSWG-HF;n=480])和 DRR(丹麦再休克 MI 注册)(n=1069)。在 CSWG-MI 中使用共识 k 均值算法识别 CS 患者的聚类,随后在 CSWG-HF 和 DRR 中进行验证。在每个表型中,患者进一步根据心血管造影和介入学会的分期进行分类。机器学习算法在 CS 中揭示了 3 个不同的聚类:“非充血性(I)”、“心肾(II)”和“心代谢(III)”休克。在 3 个队列(CSWG-MI 与 DDR 与 CSWG-HF)中,院内死亡率分别为 21%对 28%对 10%、45%对 40%对 32%、55%对 56%对 52%,分别为聚类 I、II 和 III。“心代谢性休克”聚类在表型中具有发展为 D 期或 E 期休克以及院内死亡率最高的风险,无论病因如何。尽管存在基线差异,但每个聚类在 3 个队列中都表现出可重复的人口统计学、代谢和血液动力学特征。
结论 使用机器学习,我们鉴定并验证了 3 种不同的 CS 表型,与死亡率具有明确和可重复的关联。这些表型可能有助于在临床试验中针对特定患者进行入组,并促进 CS 亚组患者的个体化治疗策略的发展。