Department of Economics, Texas Tech University, Lubbock, TX 79409, USA.
Department of Agricultural and Applied Economics, University of Georgia, Athens, GA 30602, USA.
Int J Environ Res Public Health. 2021 Jul 9;18(14):7346. doi: 10.3390/ijerph18147346.
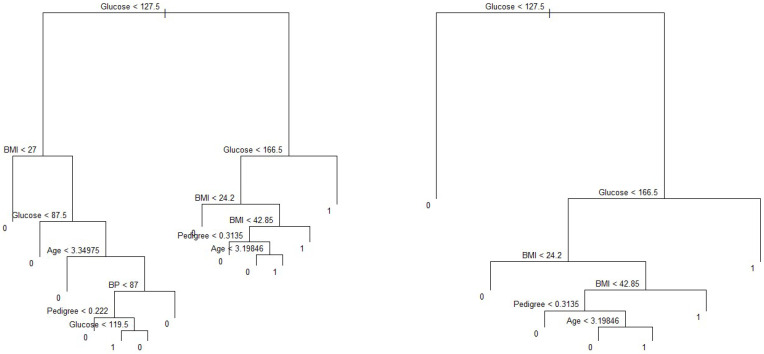
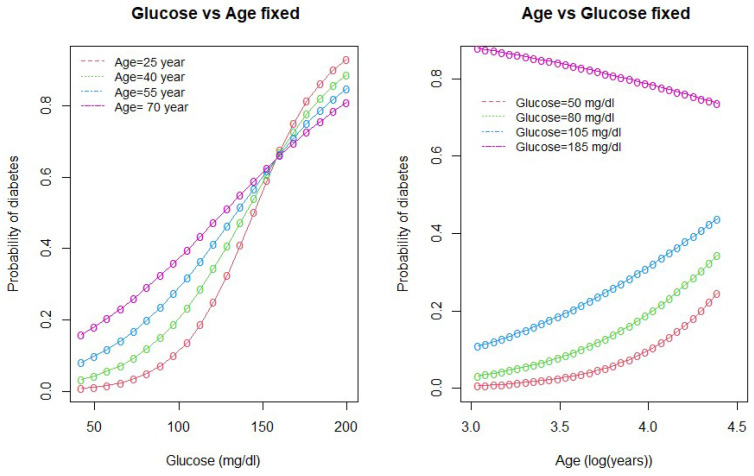
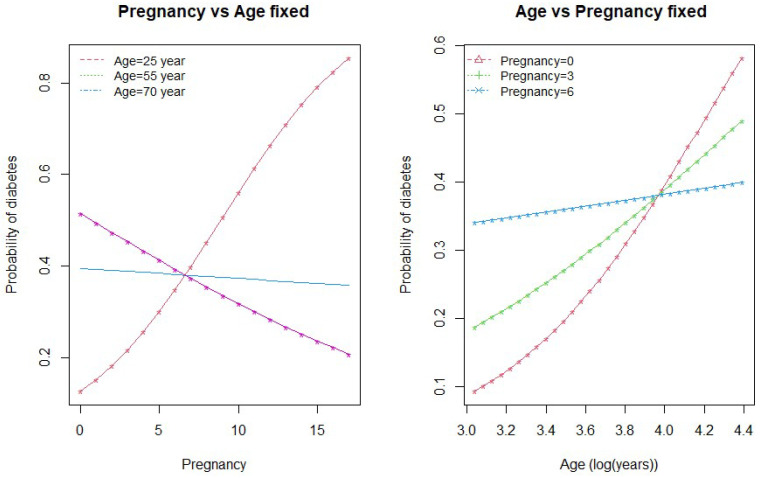
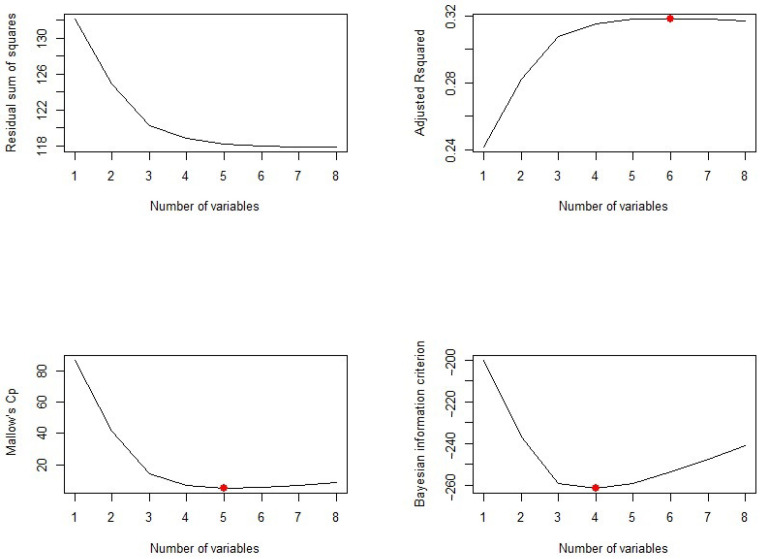
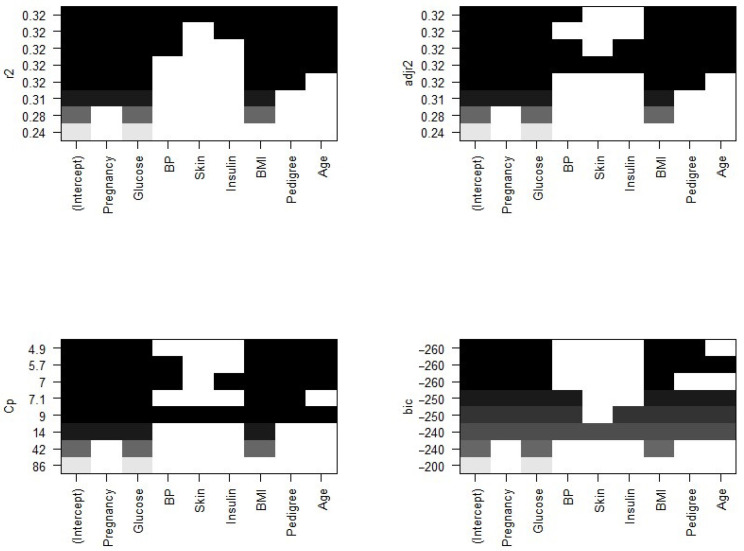
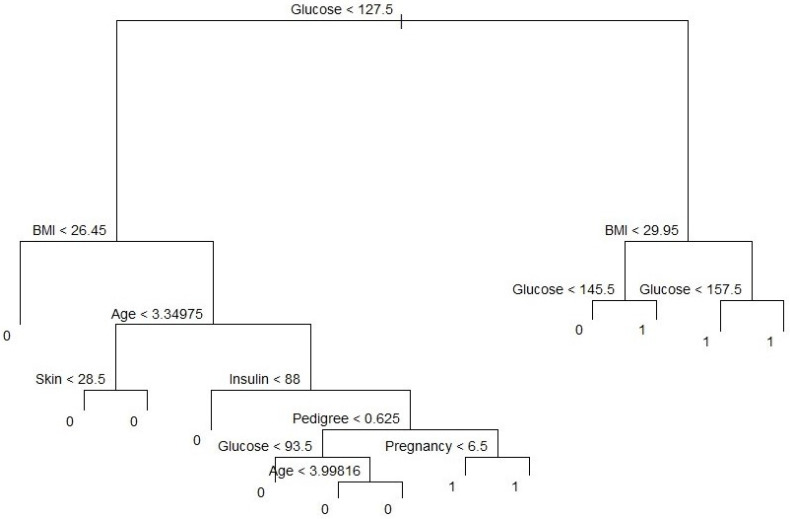
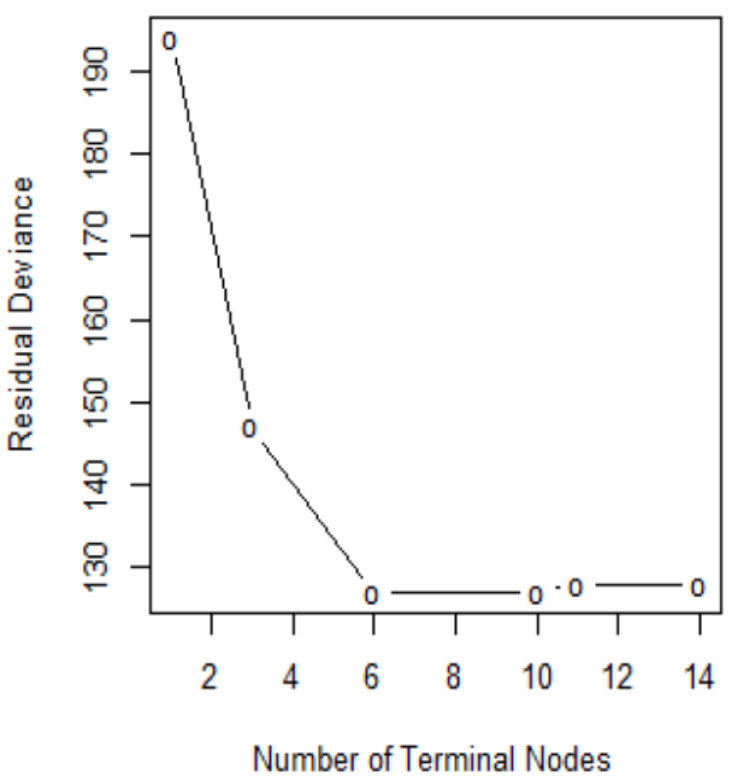
Diabetes mellitus is one of the most common human diseases worldwide and may cause several health-related complications. It is responsible for considerable morbidity, mortality, and economic loss. A timely diagnosis and prediction of this disease could provide patients with an opportunity to take the appropriate preventive and treatment strategies. To improve the understanding of risk factors, we predict type 2 diabetes for Pima Indian women utilizing a logistic regression model and decision tree-a machine learning algorithm. Our analysis finds five main predictors of type 2 diabetes: glucose, pregnancy, body mass index (BMI), diabetes pedigree function, and age. We further explore a classification tree to complement and validate our analysis. The six-fold classification tree indicates glucose, BMI, and age are important factors, while the ten-node tree implies glucose, BMI, pregnancy, diabetes pedigree function, and age as the significant predictors. Our preferred specification yields a prediction accuracy of 78.26% and a cross-validation error rate of 21.74%. We argue that our model can be applied to make a reasonable prediction of type 2 diabetes, and could potentially be used to complement existing preventive measures to curb the incidence of diabetes and reduce associated costs.
糖尿病是全球最常见的人类疾病之一,可能导致多种与健康相关的并发症。它导致了相当大的发病率、死亡率和经济损失。及时诊断和预测这种疾病可以为患者提供机会,采取适当的预防和治疗策略。为了更好地了解风险因素,我们利用逻辑回归模型和决策树(一种机器学习算法)预测皮马印第安妇女的 2 型糖尿病。我们的分析发现了 5 个 2 型糖尿病的主要预测因素:血糖、妊娠、体重指数(BMI)、糖尿病家族史函数和年龄。我们进一步探讨了分类树来补充和验证我们的分析。六叉树表明血糖、BMI 和年龄是重要因素,而十叉树则表明血糖、BMI、妊娠、糖尿病家族史函数和年龄是重要的预测因素。我们首选的规格产生了 78.26%的预测准确性和 21.74%的交叉验证错误率。我们认为,我们的模型可以用于对 2 型糖尿病进行合理预测,并有可能用于补充现有的预防措施,以遏制糖尿病的发病率并降低相关成本。