Department of Electrical Engineering (ESAT), Stadius Centre for Dynamical Systems, Signal Processing and Data Analytics, KU Leuven, Kasteelpark Arenberg 10 - Box 2446, 3001, Leuven, Belgium.
Leuven Statistics Research Center, KU Leuven, 3000, Leuven, Belgium.
BMC Med Inform Decis Mak. 2021 Sep 17;21(1):267. doi: 10.1186/s12911-021-01630-7.
The use of Electronic Health Records (EHR) data in clinical research is incredibly increasing, but the abundancy of data resources raises the challenge of data cleaning. It can save time if the data cleaning can be done automatically. In addition, the automated data cleaning tools for data in other domains often process all variables uniformly, meaning that they cannot serve well for clinical data, as there is variable-specific information that needs to be considered. This paper proposes an automated data cleaning method for EHR data with clinical knowledge taken into consideration.
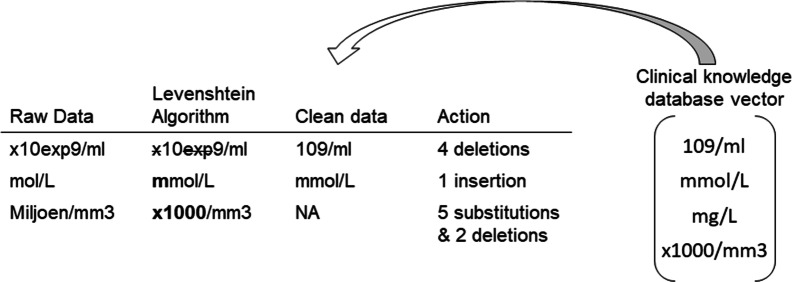
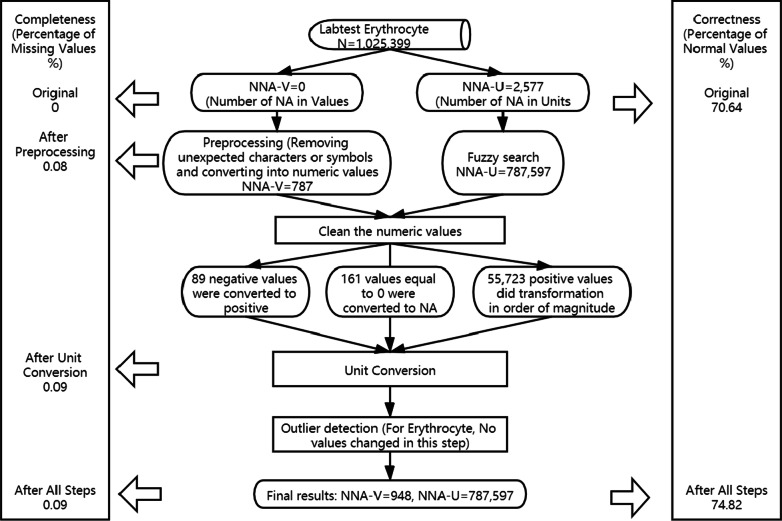
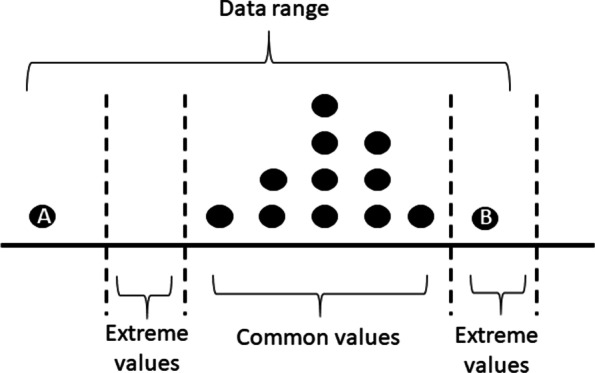
We used EHR data collected from primary care in Flanders, Belgium during 1994-2015. We constructed a Clinical Knowledge Database to store all the variable-specific information that is necessary for data cleaning. We applied Fuzzy search to automatically detect and replace the wrongly spelled units, and performed the unit conversion following the variable-specific conversion formula. Then the numeric values were corrected and outliers were detected considering the clinical knowledge. In total, 52 clinical variables were cleaned, and the percentage of missing values (completeness) and percentage of values within the normal range (correctness) before and after the cleaning process were compared.
All variables were 100% complete before data cleaning. 42 variables had a drop of less than 1% in the percentage of missing values and 9 variables declined by 1-10%. Only 1 variable experienced large decline in completeness (13.36%). All variables had more than 50% values within the normal range after cleaning, of which 43 variables had a percentage higher than 70%.
We propose a general method for clinical variables, which achieves high automation and is capable to deal with large-scale data. This method largely improved the efficiency to clean the data and removed the technical barriers for non-technical people.
电子健康记录 (EHR) 数据在临床研究中的应用正在迅速增加,但数据资源的丰富性也带来了数据清理的挑战。如果能够自动完成数据清理,将节省时间。此外,其他领域数据的自动化数据清理工具通常统一处理所有变量,这意味着它们不能很好地适用于临床数据,因为需要考虑特定于变量的信息。本文提出了一种考虑临床知识的 EHR 数据自动化数据清理方法。
我们使用了 1994 年至 2015 年期间在比利时佛兰德斯收集的初级保健 EHR 数据。我们构建了一个临床知识数据库来存储所有需要数据清理的特定于变量的信息。我们应用模糊搜索自动检测和替换拼写错误的单位,并根据特定于变量的转换公式执行单位转换。然后根据临床知识校正数字值并检测异常值。总共有 52 个临床变量进行了清理,并比较了清理前后缺失值的百分比(完整性)和正常值范围内的值的百分比(正确性)。
所有变量在数据清理前的完整性均为 100%。42 个变量缺失值百分比下降不到 1%,9 个变量下降 1-10%。只有 1 个变量的完整性下降较大(13.36%)。所有变量的正常值范围内的值百分比均超过 50%,其中 43 个变量的百分比高于 70%。
我们提出了一种针对临床变量的通用方法,该方法实现了高度自动化,能够处理大规模数据。这种方法大大提高了清理数据的效率,并为非技术人员消除了技术障碍。