Zhou Zhi-Hua, Feng Ji
National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210023, China.
Natl Sci Rev. 2019 Jan;6(1):74-86. doi: 10.1093/nsr/nwy108. Epub 2018 Oct 8.
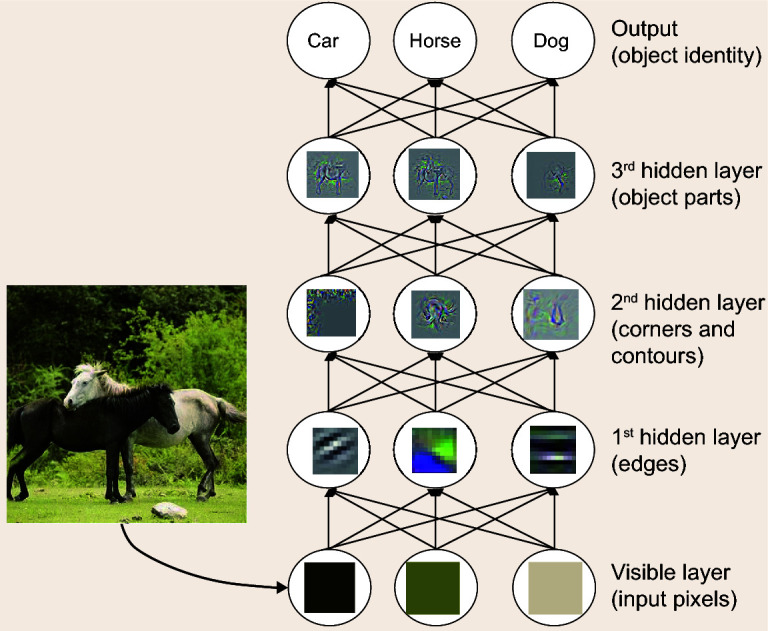
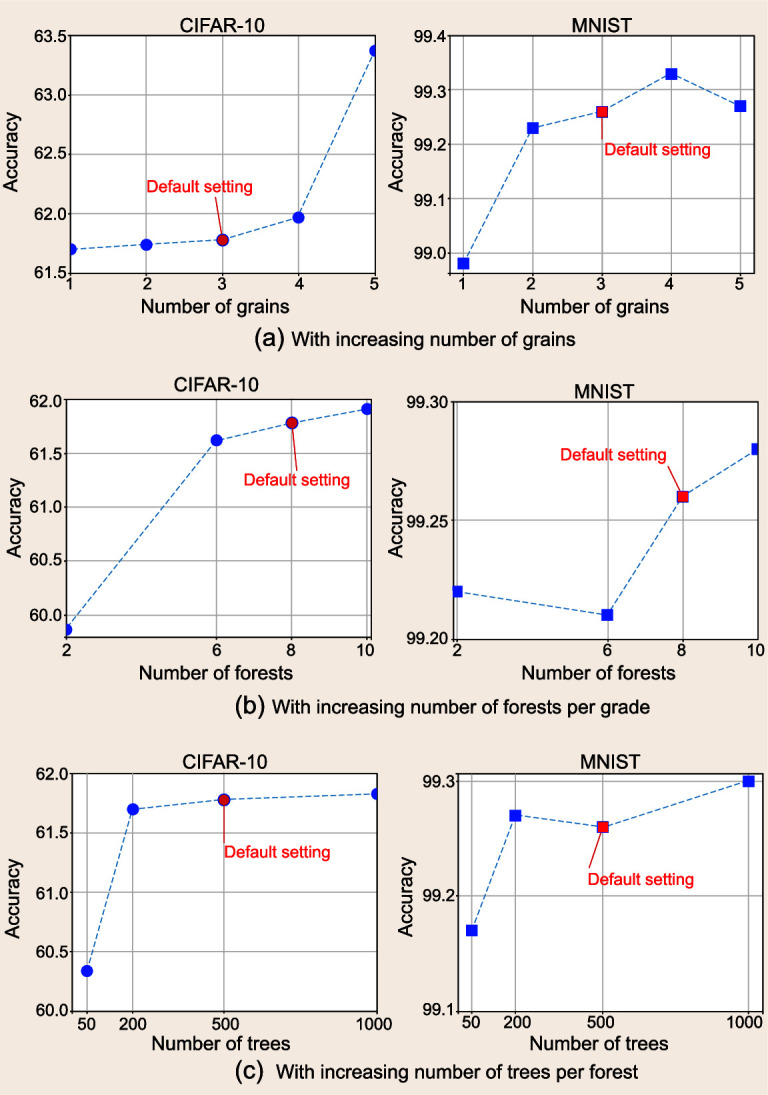
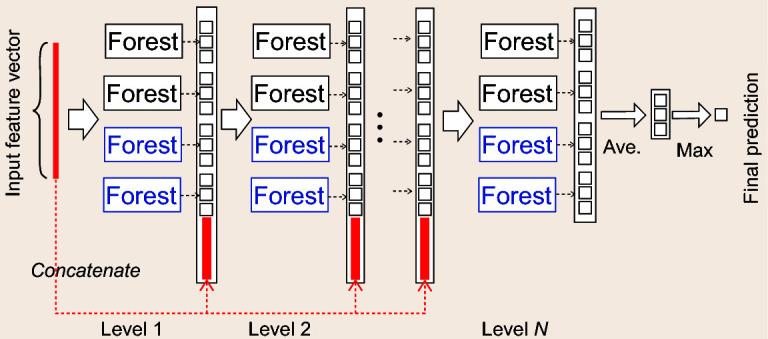
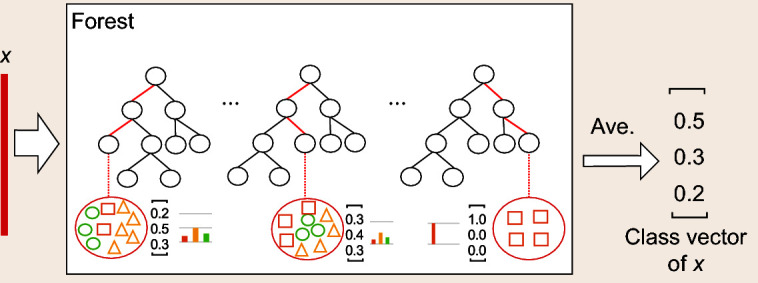
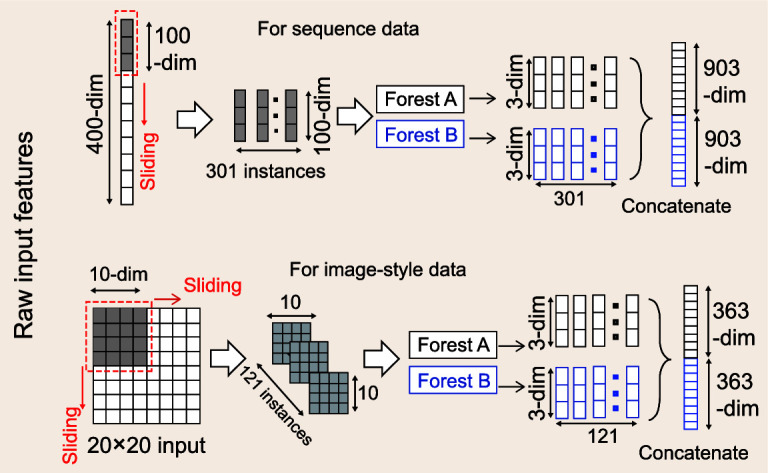
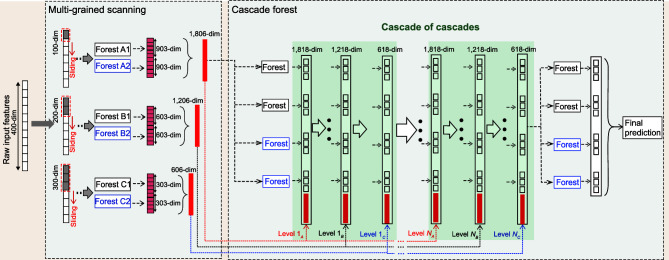
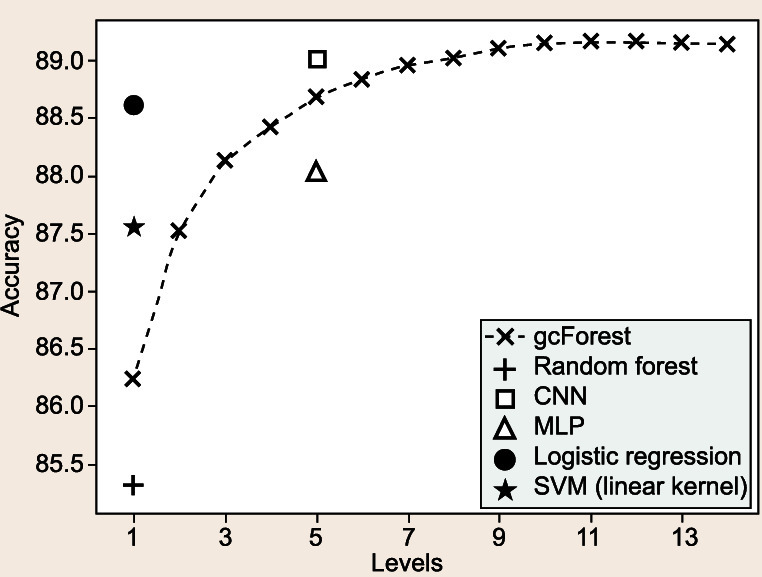
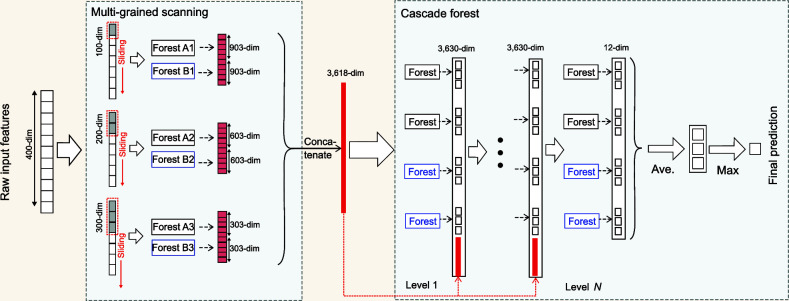
Current deep-learning models are mostly built upon neural networks, i.e. multiple layers of parameterized differentiable non-linear modules that can be trained by backpropagation. In this paper, we explore the possibility of building deep models based on non-differentiable modules such as decision trees. After a discussion about the mystery behind deep neural networks, particularly by contrasting them with shallow neural networks and traditional machine-learning techniques such as decision trees and boosting machines, we conjecture that the success of deep neural networks owes much to three characteristics, i.e. layer-by-layer processing, in-model feature transformation and sufficient model complexity. On one hand, our conjecture may offer inspiration for theoretical understanding of deep learning; on the other hand, to verify the conjecture, we propose an approach that generates deep forest holding these characteristics. This is a decision-tree ensemble approach, with fewer hyper-parameters than deep neural networks, and its model complexity can be automatically determined in a data-dependent way. Experiments show that its performance is quite robust to hyper-parameter settings, such that in most cases, even across different data from different domains, it is able to achieve excellent performance by using the same default setting. This study opens the door to deep learning based on non-differentiable modules without gradient-based adjustment, and exhibits the possibility of constructing deep models without backpropagation.
当前的深度学习模型大多基于神经网络构建,即由多层可参数化的可微非线性模块组成,这些模块可通过反向传播进行训练。在本文中,我们探索基于诸如决策树等不可微模块构建深度模型的可能性。在讨论了深度神经网络背后的奥秘之后,特别是通过将它们与浅层神经网络以及诸如决策树和提升机器等传统机器学习技术进行对比,我们推测深度神经网络的成功很大程度上归功于三个特征,即逐层处理、模型内特征变换和足够的模型复杂性。一方面,我们的推测可能为深度学习的理论理解提供启示;另一方面,为了验证这一推测,我们提出了一种生成具有这些特征的深度森林的方法。这是一种决策树集成方法,其超参数比深度神经网络少,并且其模型复杂性可以以数据依赖的方式自动确定。实验表明,其性能对超参数设置相当稳健,以至于在大多数情况下,即使是来自不同领域的不同数据,通过使用相同的默认设置也能够实现优异的性能。这项研究为基于不可微模块且无需基于梯度调整的深度学习打开了大门,并展示了无需反向传播构建深度模型的可能性。