Wang Minjie, Allen Genevera I
Department of Statistics, Rice University, Houston, TX 77005, USA.
Departments of Electrical and Computer Engineering, Statistics, and Computer Science, Rice University, Houston, TX 77005, USA; Jan and Dan Duncan Neurological Research Institute, Baylor College of Medicine, Houston, TX 77030, USA.
J Mach Learn Res. 2021 Jan;22.
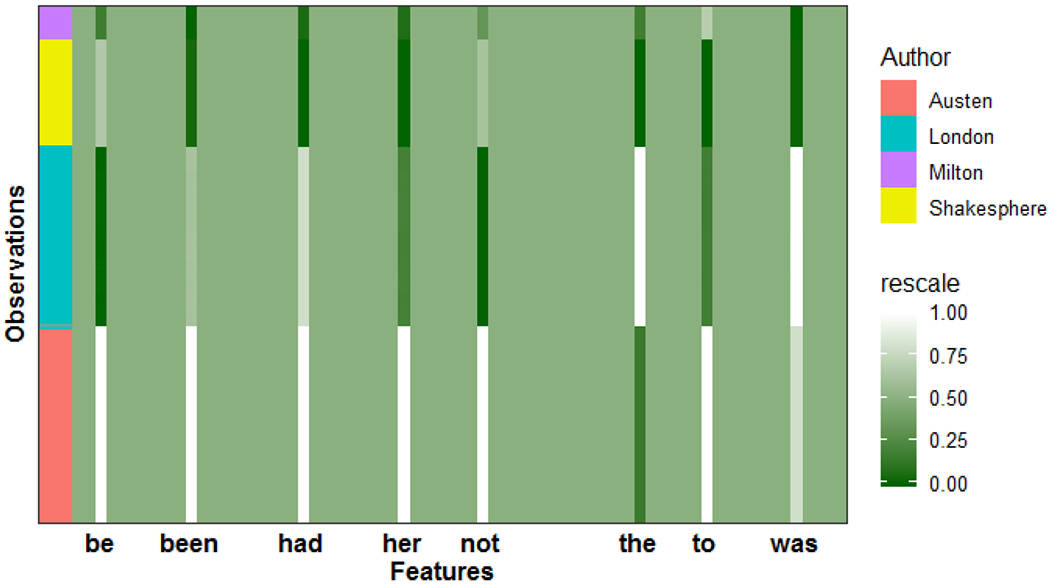
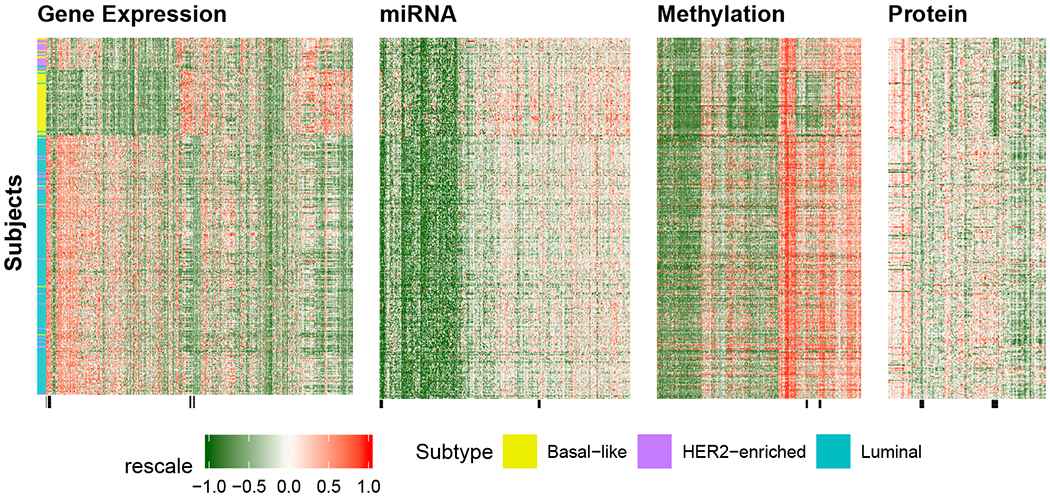
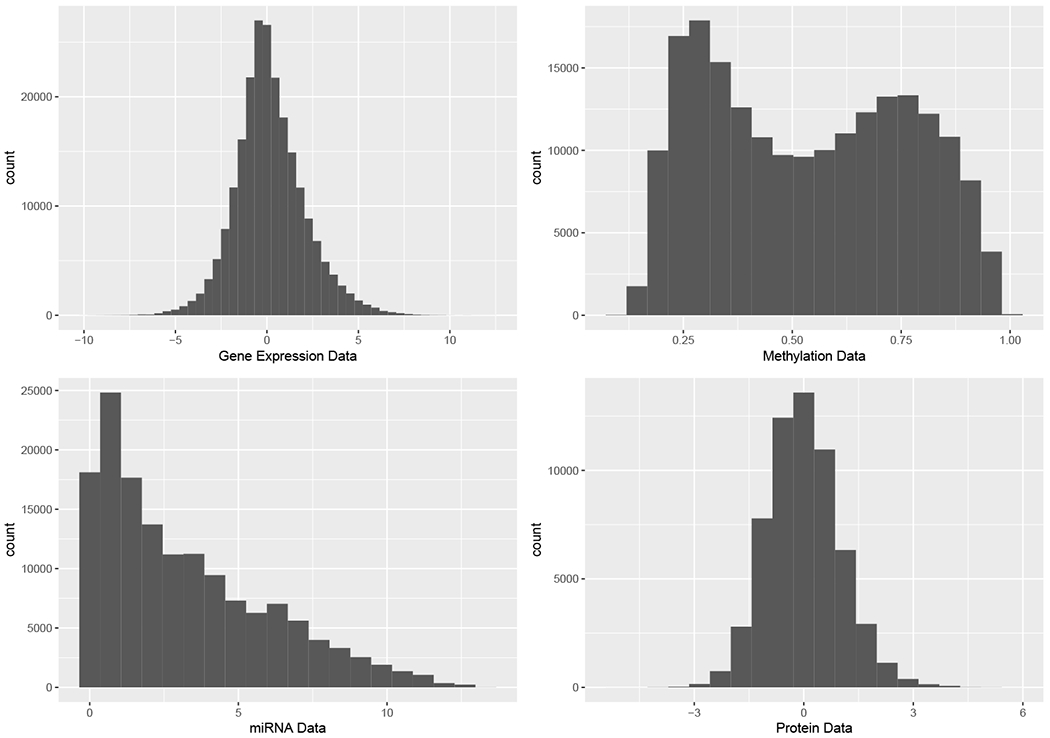
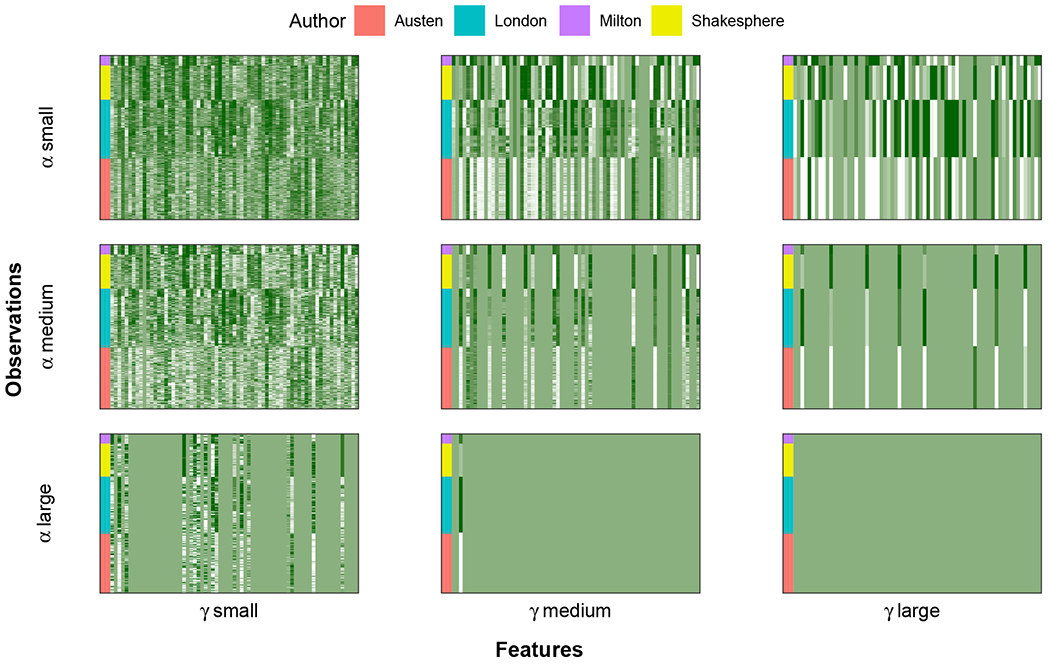
In mixed multi-view data, multiple sets of diverse features are measured on the same set of samples. By integrating all available data sources, we seek to discover common group structure among the samples that may be hidden in individualistic cluster analyses of a single data view. While several techniques for such integrative clustering have been explored, we propose and develop a convex formalization that enjoys strong empirical performance and inherits the mathematical properties of increasingly popular convex clustering methods. Specifically, our Integrative Generalized Convex Clustering Optimization (iGecco) method employs different convex distances, losses, or divergences for each of the different data views with a joint convex fusion penalty that leads to common groups. Additionally, integrating mixed multi-view data is often challenging when each data source is high-dimensional. To perform feature selection in such scenarios, we develop an adaptive shifted group-lasso penalty that selects features by shrinking them towards their loss-specific centers. Our so-called iGecco+ approach selects features from each data view that are best for determining the groups, often leading to improved integrative clustering. To solve our problem, we develop a new type of generalized multi-block ADMM algorithm using sub-problem approximations that more efficiently fits our model for big data sets. Through a series of numerical experiments and real data examples on text mining and genomics, we show that iGecco+ achieves superior empirical performance for high-dimensional mixed multi-view data.
在混合多视图数据中,在同一组样本上测量了多组不同的特征。通过整合所有可用数据源,我们试图发现样本之间可能隐藏在单个数据视图的个性化聚类分析中的共同组结构。虽然已经探索了几种用于这种整合聚类的技术,但我们提出并开发了一种凸形式化方法,它具有强大的实证性能,并继承了越来越流行的凸聚类方法的数学性质。具体来说,我们的整合广义凸聚类优化(iGecco)方法为每个不同的数据视图采用不同的凸距离、损失或散度,并带有一个联合凸融合惩罚项,从而得出共同的组。此外,当每个数据源都是高维时,整合混合多视图数据通常具有挑战性。为了在这种情况下进行特征选择,我们开发了一种自适应移位组套索惩罚项,通过将特征向其特定于损失的中心收缩来选择特征。我们所谓的iGecco +方法从每个数据视图中选择最适合确定组的特征,这通常会导致改进的整合聚类。为了解决我们的问题,我们使用子问题近似开发了一种新型的广义多块交替方向乘子法(ADMM)算法,该算法能更有效地使我们的模型适用于大数据集。通过一系列关于文本挖掘和基因组学的数值实验和实际数据示例,我们表明iGecco +在高维混合多视图数据上实现了卓越的实证性能。