University of Arkansas for Medical Sciences, Department of Biomedical Informatics, Little Rock, Arkansas, United States of America.
Pathogen and Microbiome Institute, Northern Arizona University, Flagstaff, Arizona, United States of America.
PLoS Comput Biol. 2021 Nov 8;17(11):e1009581. doi: 10.1371/journal.pcbi.1009581. eCollection 2021 Nov.
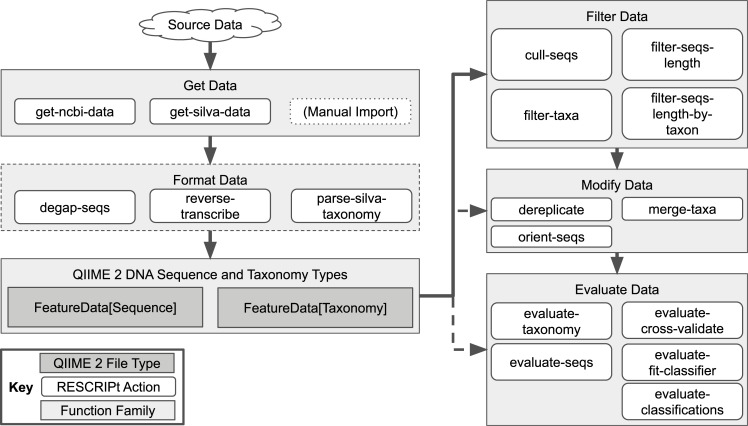
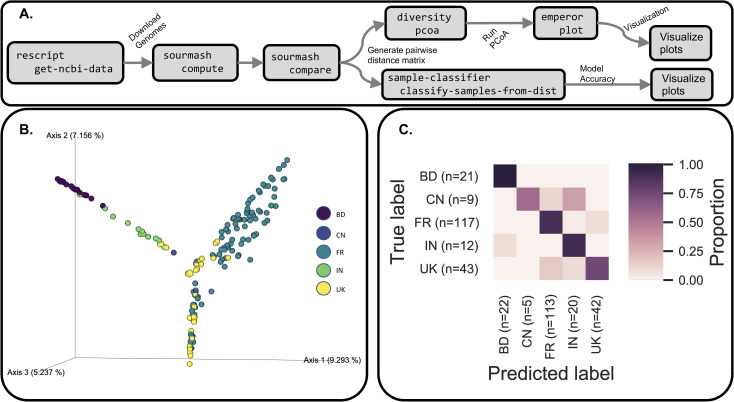
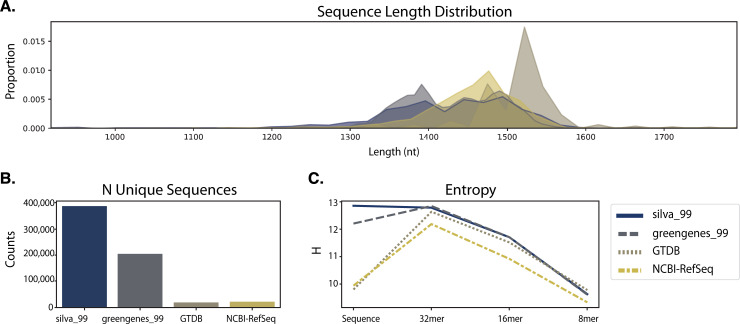
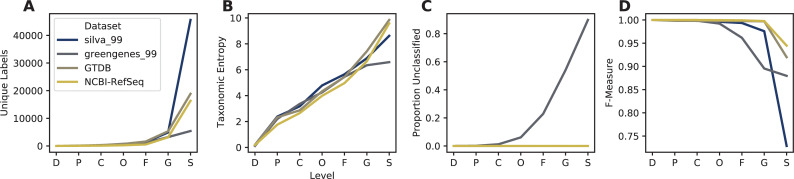
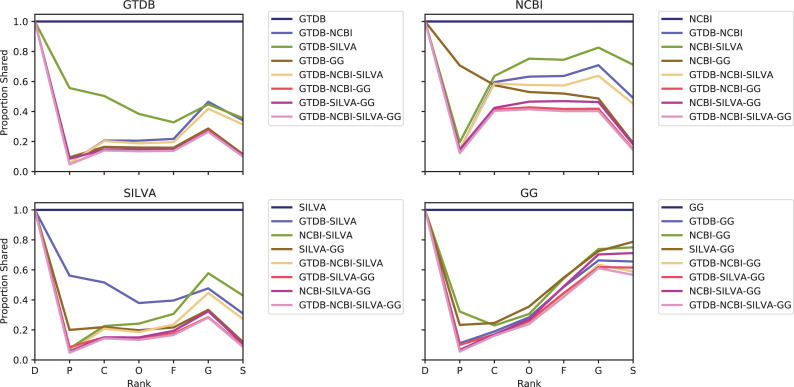
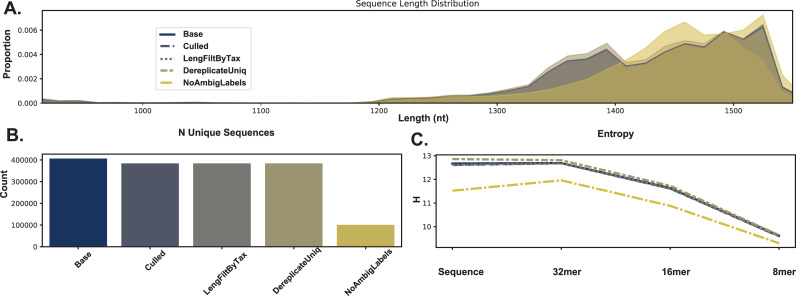
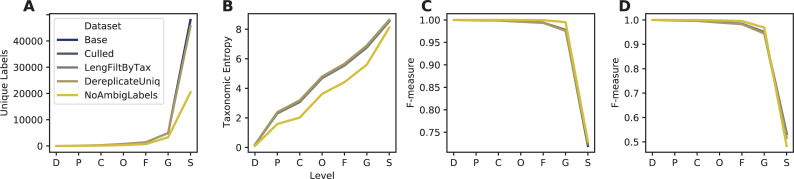
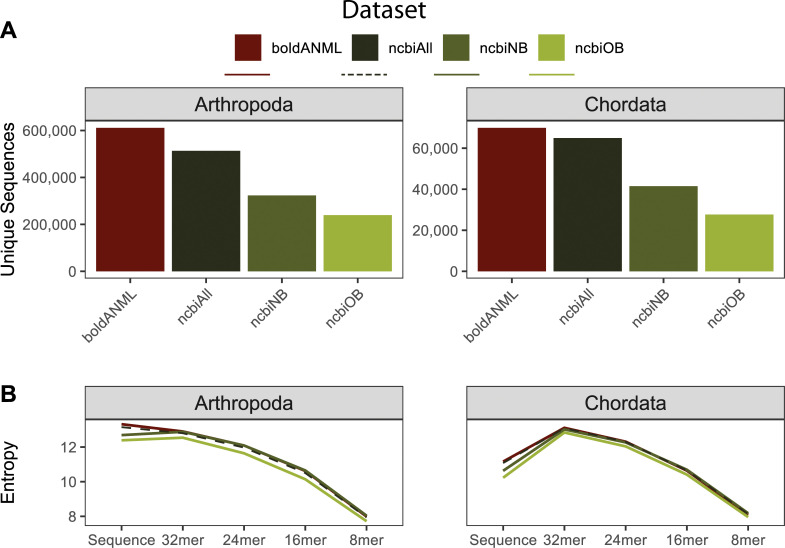
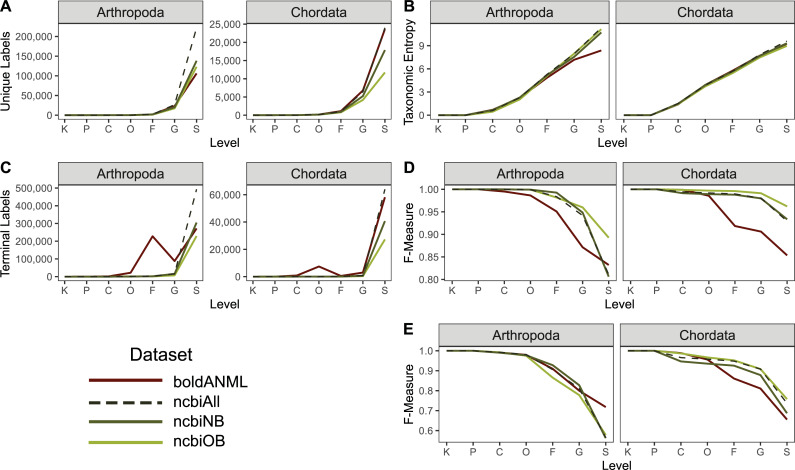
Nucleotide sequence and taxonomy reference databases are critical resources for widespread applications including marker-gene and metagenome sequencing for microbiome analysis, diet metabarcoding, and environmental DNA (eDNA) surveys. Reproducibly generating, managing, using, and evaluating nucleotide sequence and taxonomy reference databases creates a significant bottleneck for researchers aiming to generate custom sequence databases. Furthermore, database composition drastically influences results, and lack of standardization limits cross-study comparisons. To address these challenges, we developed RESCRIPt, a Python 3 software package and QIIME 2 plugin for reproducible generation and management of reference sequence taxonomy databases, including dedicated functions that streamline creating databases from popular sources, and functions for evaluating, comparing, and interactively exploring qualitative and quantitative characteristics across reference databases. To highlight the breadth and capabilities of RESCRIPt, we provide several examples for working with popular databases for microbiome profiling (SILVA, Greengenes, NCBI-RefSeq, GTDB), eDNA and diet metabarcoding surveys (BOLD, GenBank), as well as for genome comparison. We show that bigger is not always better, and reference databases with standardized taxonomies and those that focus on type strains have quantitative advantages, though may not be appropriate for all use cases. Most databases appear to benefit from some curation (quality filtering), though sequence clustering appears detrimental to database quality. Finally, we demonstrate the breadth and extensibility of RESCRIPt for reproducible workflows with a comparison of global hepatitis genomes. RESCRIPt provides tools to democratize the process of reference database acquisition and management, enabling researchers to reproducibly and transparently create reference materials for diverse research applications. RESCRIPt is released under a permissive BSD-3 license at https://github.com/bokulich-lab/RESCRIPt.
核苷酸序列和分类学参考数据库是广泛应用的关键资源,包括微生物组分析的标记基因和宏基因组测序、饮食代谢条形码和环境 DNA(eDNA)调查。可重复地生成、管理、使用和评估核苷酸序列和分类学参考数据库,为希望生成自定义序列数据库的研究人员带来了重大瓶颈。此外,数据库组成极大地影响结果,缺乏标准化限制了跨研究比较。为了解决这些挑战,我们开发了 RESCRIPt,这是一个用于可重复生成和管理参考序列分类学数据库的 Python 3 软件包和 QIIME 2 插件,包括专门的功能,可简化从流行来源创建数据库的过程,以及用于评估、比较和交互式探索参考数据库中定性和定量特征的功能。为了突出 RESCRIPt 的广度和功能,我们提供了一些示例,用于处理微生物组分析的流行数据库(SILVA、Greengenes、NCBI-RefSeq、GTDB)、eDNA 和饮食代谢条形码调查(BOLD、GenBank)以及基因组比较。我们表明,更大并不总是更好,具有标准化分类学的参考数据库和专注于模式菌株的参考数据库具有定量优势,尽管它们可能不适用于所有用例。大多数数据库似乎都受益于某种策管(质量过滤),尽管序列聚类似乎对数据库质量有害。最后,我们通过比较全球肝炎基因组来展示 RESCRIPt 用于可重复工作流程的广度和可扩展性。RESCRIPt 提供了工具,使参考数据库获取和管理的过程民主化,使研究人员能够为各种研究应用可重复和透明地创建参考材料。RESCRIPt 在 https://github.com/bokulich-lab/RESCRIPt 下以宽松的 BSD-3 许可证发布。