Sharma Dilip Kumar, Garg Sonal
GLA University, Mathura, India.
Complex Intell Systems. 2023;9(3):2843-2863. doi: 10.1007/s40747-021-00552-1. Epub 2021 Oct 16.
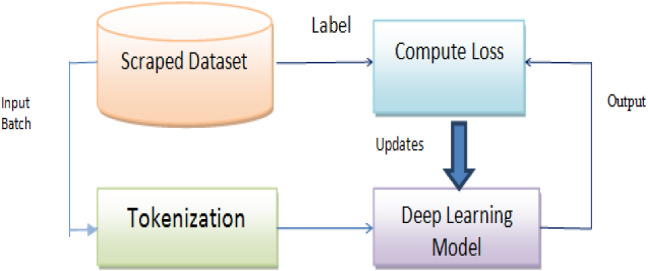
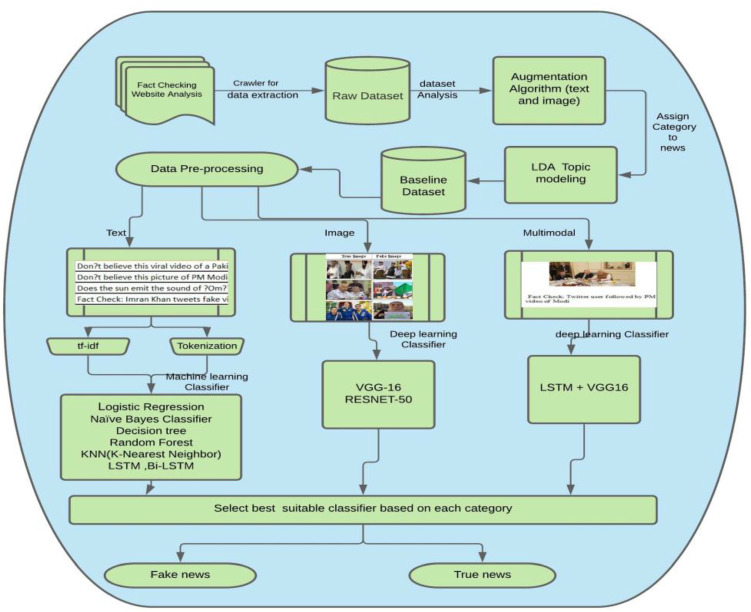
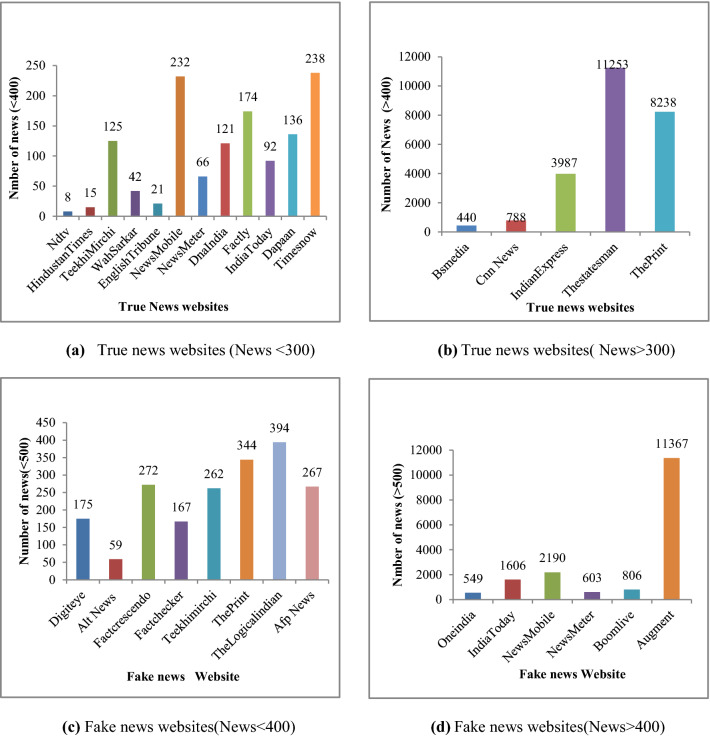
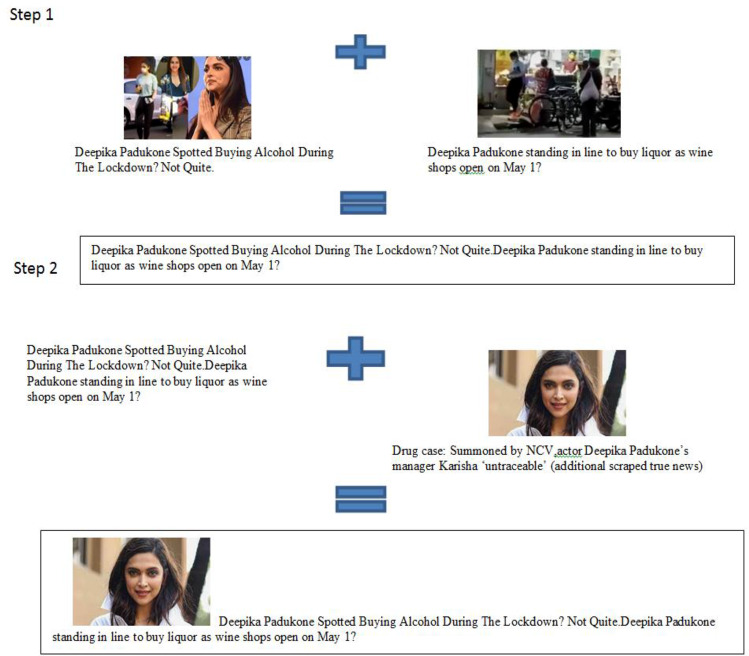
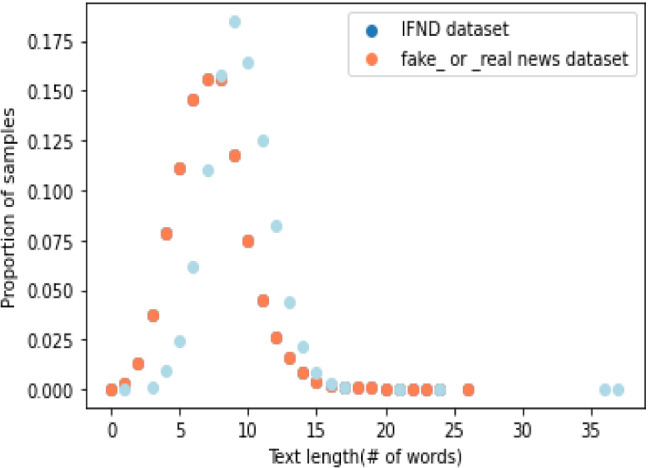
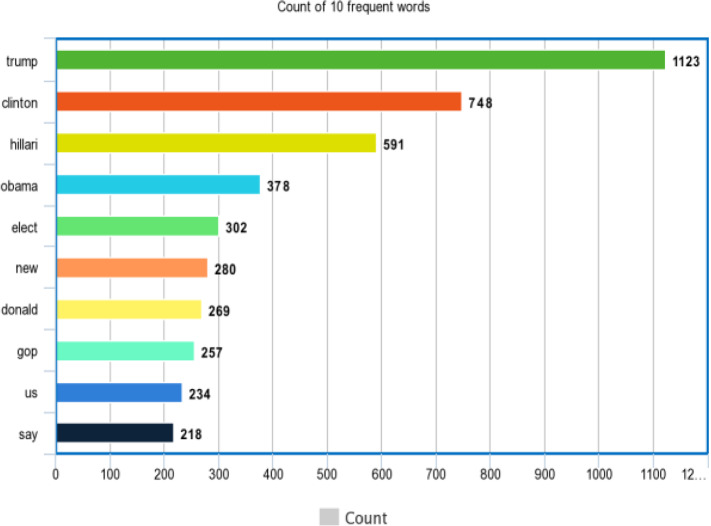
Spotting fake news is a critical problem nowadays. Social media are responsible for propagating fake news. Fake news propagated over digital platforms generates confusion as well as induce biased perspectives in people. Detection of misinformation over the digital platform is essential to mitigate its adverse impact. Many approaches have been implemented in recent years. Despite the productive work, fake news identification poses many challenges due to the lack of a comprehensive publicly available benchmark dataset. There is no large-scale dataset that consists of Indian news only. So, this paper presents IFND (Indian fake news dataset) dataset. The dataset consists of both text and images. The majority of the content in the dataset is about events from the year 2013 to the year 2021. Dataset content is scrapped using the Parsehub tool. To increase the size of the fake news in the dataset, an intelligent augmentation algorithm is used. An intelligent augmentation algorithm generates meaningful fake news statements. The latent Dirichlet allocation (LDA) technique is employed for topic modelling to assign the categories to news statements. Various machine learning and deep-learning classifiers are implemented on text and image modality to observe the proposed IFND dataset's performance. A multi-modal approach is also proposed, which considers both textual and visual features for fake news detection. The proposed IFND dataset achieved satisfactory results. This study affirms that the accessibility of such a huge dataset can actuate research in this laborious exploration issue and lead to better prediction models.
如今,识别虚假新闻是一个关键问题。社交媒体对虚假新闻的传播负有责任。在数字平台上传播的虚假新闻会造成混乱,并在人们中引发偏见。在数字平台上检测错误信息对于减轻其不利影响至关重要。近年来已经实施了许多方法。尽管取得了丰硕的成果,但由于缺乏全面的公开基准数据集,虚假新闻识别仍面临许多挑战。没有仅包含印度新闻的大规模数据集。因此,本文提出了IFND(印度虚假新闻数据集)数据集。该数据集包含文本和图像。数据集中的大部分内容是关于2013年至2021年的事件。数据集内容使用Parsehub工具进行抓取。为了增加数据集中虚假新闻的数量,使用了一种智能增强算法。智能增强算法生成有意义的虚假新闻陈述。潜在狄利克雷分配(LDA)技术用于主题建模,为新闻陈述分配类别。在文本和图像模态上实现了各种机器学习和深度学习分类器,以观察所提出的IFND数据集的性能。还提出了一种多模态方法,该方法考虑文本和视觉特征来进行虚假新闻检测。所提出的IFND数据集取得了令人满意的结果。这项研究证实,如此庞大数据集的可获取性可以推动在这个艰巨的探索问题上的研究,并导致更好的预测模型。