Jha Neha, Hall Dwight, Kanakan Akshay, Mehta Priyanka, Maurya Ranjeet, Mir Quoseena, Gill Hunter Mathias, Janga Sarath Chandra, Pandey Rajesh
Integrative Genomics of Host-Pathogen (INGEN-HOPE) Laboratory, CSIR-Institute of Genomics and Integrative Biology (CSIR-IGIB), Delhi, India.
Department of Biohealth Informatics, School of Informatics and Computing, Indiana University Purdue University, Indianapolis, IN, United States.
Front Genet. 2021 Dec 17;12:753648. doi: 10.3389/fgene.2021.753648. eCollection 2021.
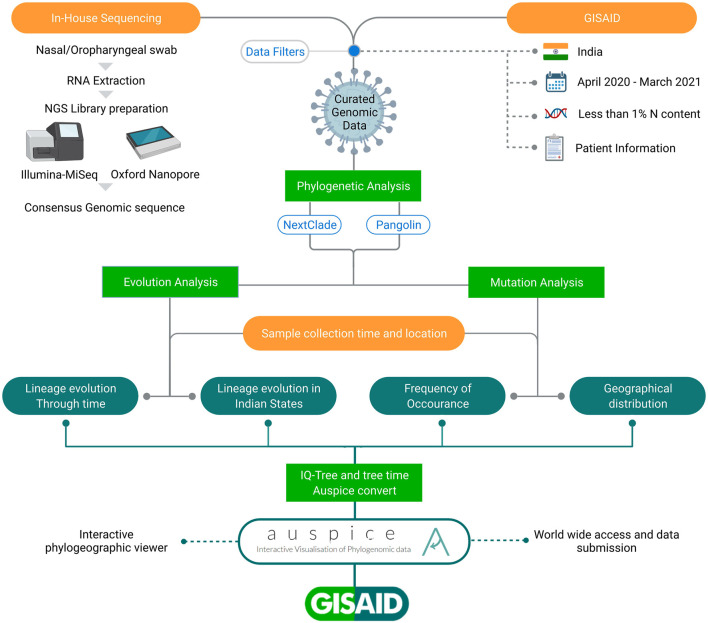
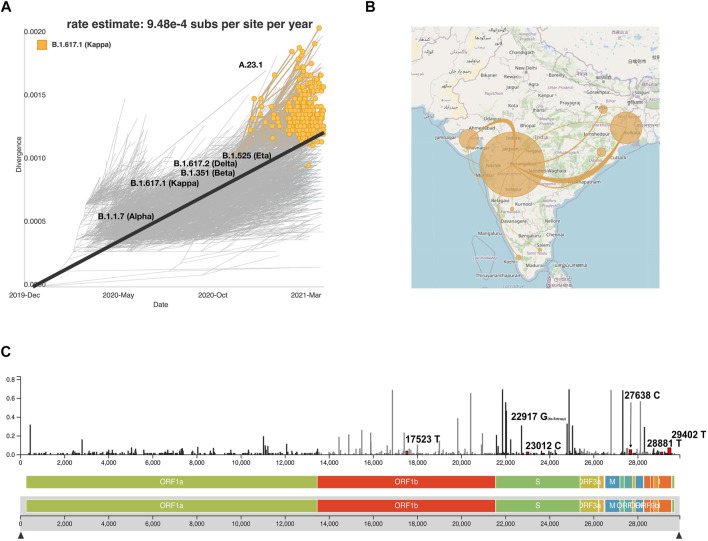
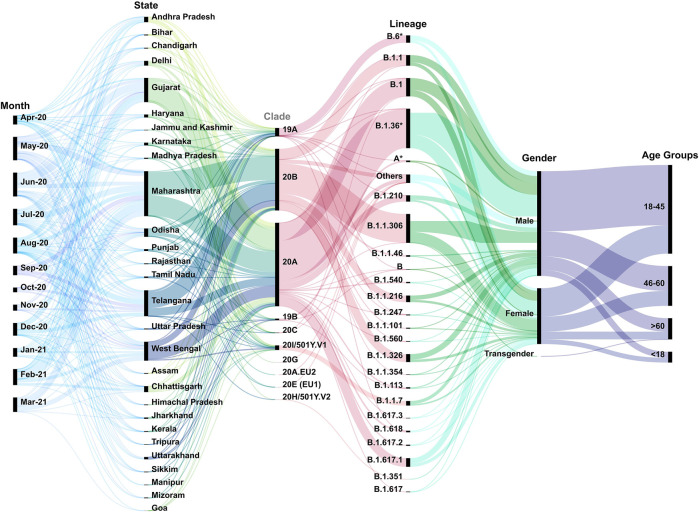
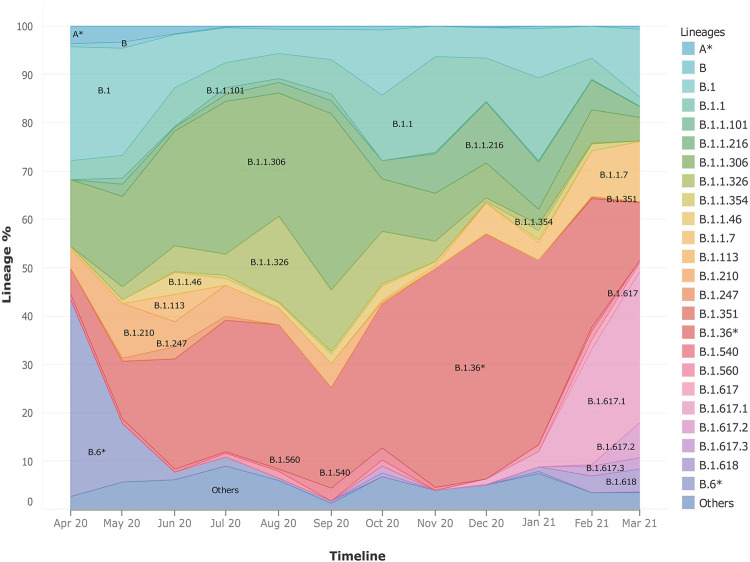
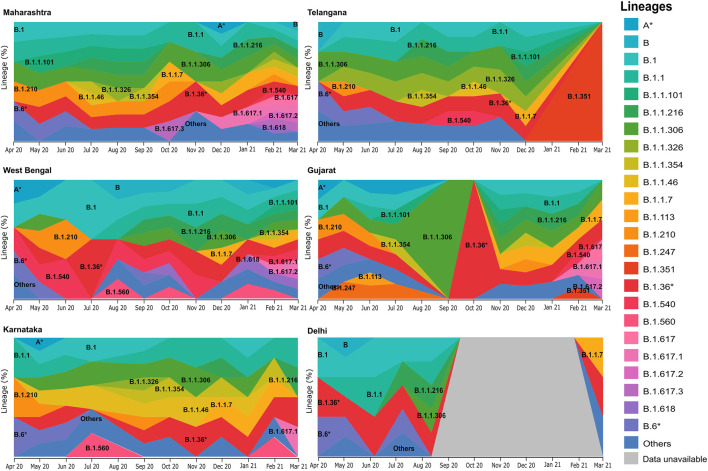
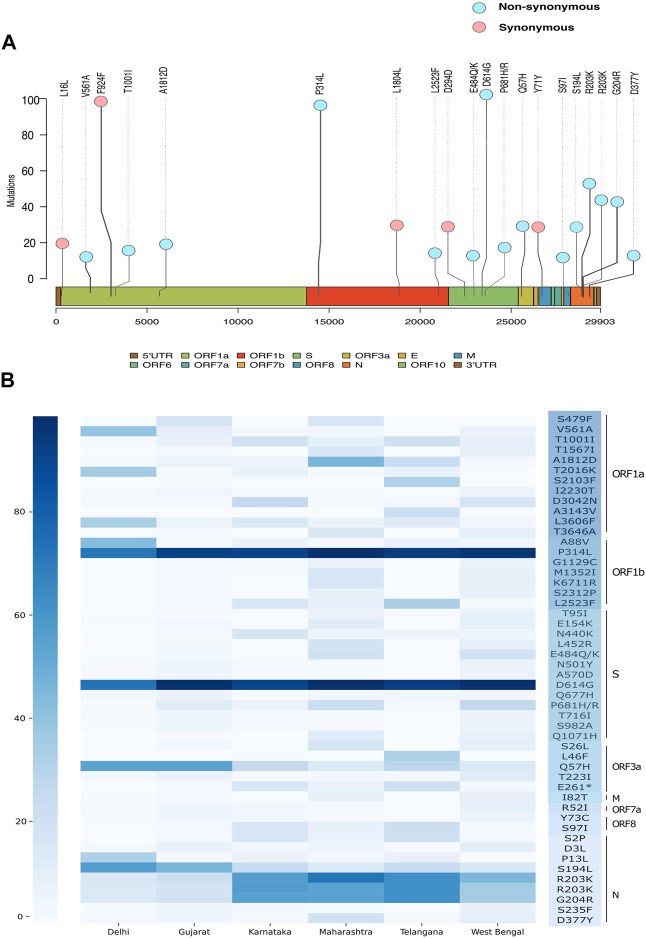
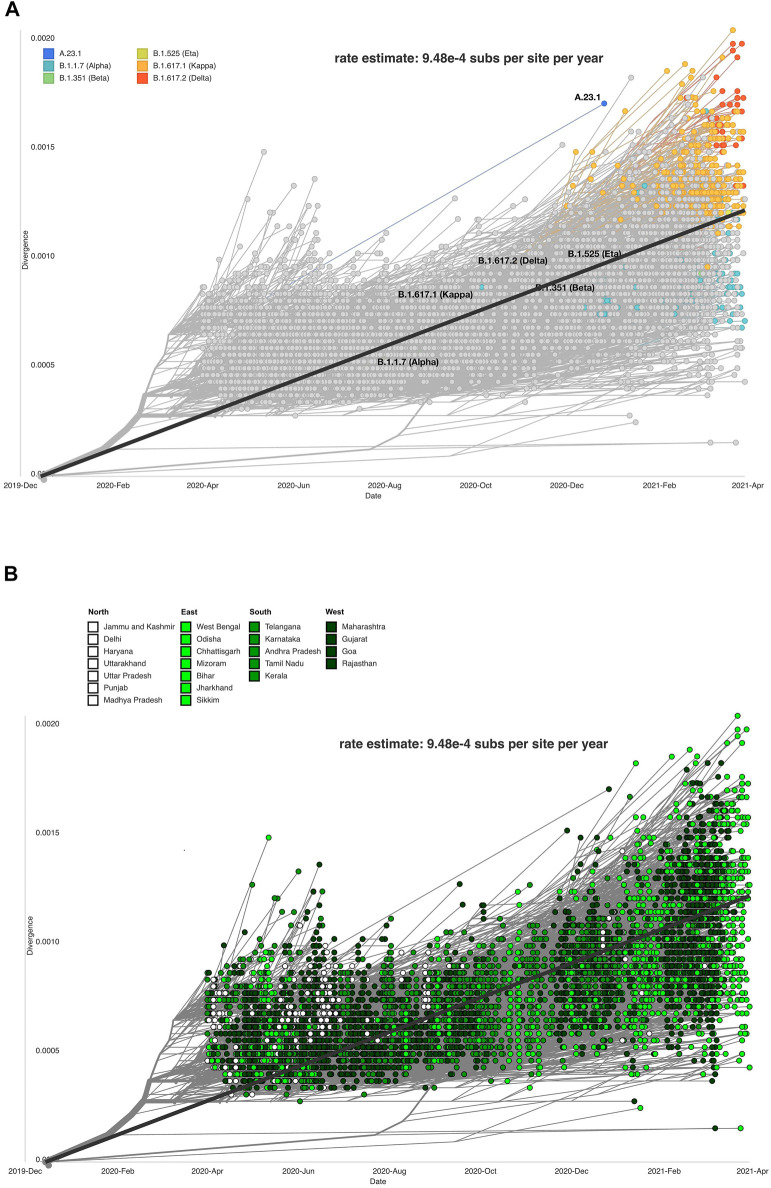
Globally, SARS-CoV-2 has moved from one tide to another with ebbs in between. Genomic surveillance has greatly aided the detection and tracking of the virus and the identification of the variants of concern (VOC). The knowledge and understanding from genomic surveillance is important for a populous country like India for public health and healthcare officials for advance planning. An integrative analysis of the publicly available datasets in GISAID from India reveals the differential distribution of clades, lineages, gender, and age over a year (Apr 2020-Mar 2021). The significant insights include the early evidence towards B.1.617 and B.1.1.7 lineages in the specific states of India. Pan-India longitudinal data highlighted that B.1.36* was the predominant clade in India until January-February 2021 after which it has gradually been replaced by the B.1.617.1 lineage, from December 2020 onward. Regional analysis of the spread of SARS-CoV-2 indicated that B.1.617.3 was first seen in India in the month of October in the state of Maharashtra, while the now most prevalent strain B.1.617.2 was first seen in Bihar and subsequently spread to the states of Maharashtra, Gujarat, and West Bengal. To enable a real time understanding of the transmission and evolution of the SARS-CoV-2 genomes, we built a transmission map available on https://covid19-indiana.soic.iupui.edu/India/EmergingLineages/April2020/to/March2021. Based on our analysis, the rate estimate for divergence in our dataset was 9.48 e-4 substitutions per site/year for SARS-CoV-2. This would enable pandemic preparedness with the addition of future sequencing data from India available in the public repositories for tracking and monitoring the VOCs and variants of interest (VOI). This would help aid decision making from the public health perspective.
在全球范围内,新冠病毒(SARS-CoV-2)已从一个浪潮转向另一个浪潮,其间有起伏。基因组监测极大地有助于病毒的检测和追踪以及关注变异株(VOC)的识别。对于像印度这样的人口大国而言,基因组监测所获得的知识和理解对公共卫生和医疗官员进行预先规划很重要。对来自印度的全球共享流感数据倡议组织(GISAID)中公开可用数据集的综合分析揭示了一年(2020年4月至2021年3月)内进化枝、谱系、性别和年龄的差异分布。重要的见解包括印度特定邦出现B.1.617和B.1.1.7谱系的早期证据。全印度纵向数据突出显示,直到2021年1月至2月,B.1.36*一直是印度的主要进化枝,此后从2020年12月起逐渐被B.1.617.1谱系取代。对新冠病毒传播的区域分析表明,B.1.617.3于10月在印度马哈拉施特拉邦首次出现,而目前最流行的毒株B.1.617.2首次在比哈尔邦出现,随后传播到马哈拉施特拉邦、古吉拉特邦和西孟加拉邦。为了实时了解新冠病毒基因组的传播和进化,我们构建了一个传播图谱,可在https://covid19-indiana.soic.iupui.edu/India/EmergingLineages/April2020/to/March2021上获取。基于我们的分析,我们数据集中新冠病毒每个位点每年的分歧速率估计为9.48×10⁻⁴个替换。这将通过添加来自印度的未来测序数据(可在公共存储库中获取,用于追踪和监测关注变异株及感兴趣变异株)来实现大流行防范。这将有助于从公共卫生角度辅助决策。