Rashidi Hooman H, Khan Imran H, Dang Luke T, Albahra Samer, Ratan Ujjwal, Chadderwala Nihir, To Wilson, Srinivas Prathima, Wajda Jeffery, Tran Nam K
Department of Pathology and Laboratory Medicine, University of California, Davis, School of Medicine, Sacramento, California, United States of America.
Amazon Web Services, Seattle, Washington, United States of America.
J Pathol Inform. 2022 Jan 20;13:10. doi: 10.4103/jpi.jpi_75_21. eCollection 2022.
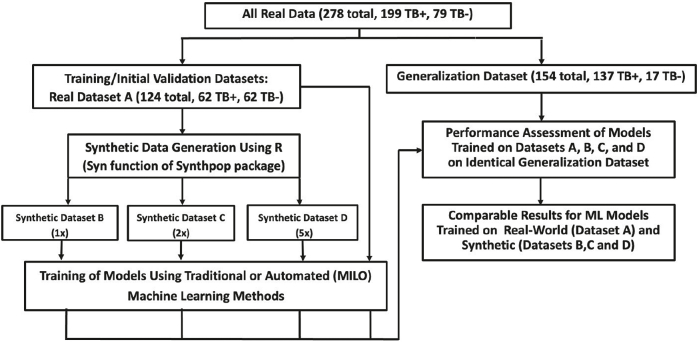
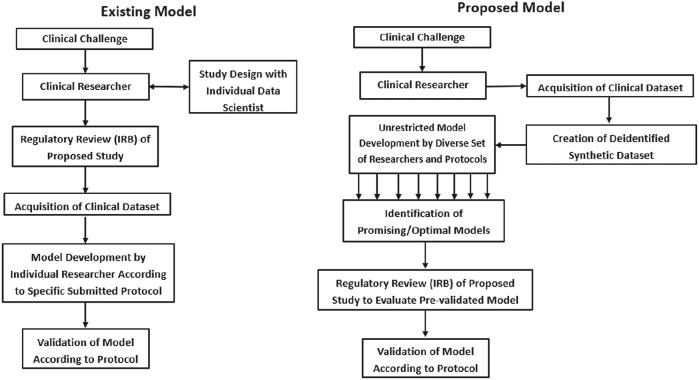
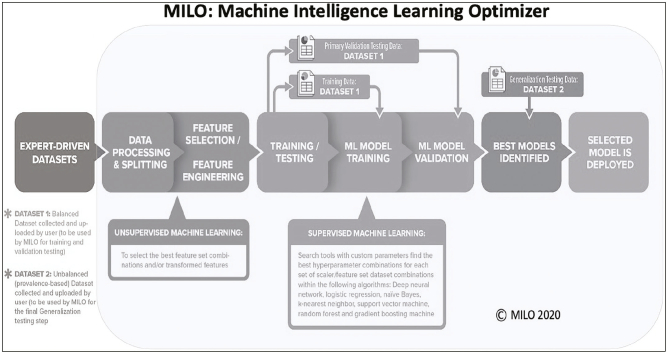
High-quality medical data is critical to the development and implementation of machine learning (ML) algorithms in healthcare; however, security, and privacy concerns continue to limit access. We sought to determine the utility of "synthetic data" in training ML algorithms for the detection of tuberculosis (TB) from inflammatory biomarker profiles. A retrospective dataset (A) comprised of 278 patients was used to generate synthetic datasets (B, C, and D) for training models prior to secondary validation on a generalization dataset. ML models trained and validated on the Dataset A (real) demonstrated an accuracy of 90%, a sensitivity of 89% (95% CI, 83-94%), and a specificity of 100% (95% CI, 81-100%). Models trained using the optimal synthetic dataset B showed an accuracy of 91%, a sensitivity of 93% (95% CI, 87-96%), and a specificity of 77% (95% CI, 50-93%). Synthetic datasets C and D displayed diminished performance measures (respective accuracies of 71% and 54%). This pilot study highlights the promise of synthetic data as an expedited means for ML algorithm development.
高质量的医学数据对于医疗保健领域机器学习(ML)算法的开发和实施至关重要;然而,安全和隐私问题继续限制数据的获取。我们试图确定“合成数据”在训练用于从炎症生物标志物谱中检测结核病(TB)的ML算法中的效用。一个由278名患者组成的回顾性数据集(A)被用于生成合成数据集(B、C和D),以便在泛化数据集上进行二次验证之前训练模型。在数据集A(真实数据)上训练和验证的ML模型显示准确率为90%,灵敏度为89%(95%CI,83 - 94%),特异性为100%(95%CI,81 - 100%)。使用最优合成数据集B训练的模型显示准确率为91%,灵敏度为93%(95%CI,87 - 96%),特异性为77%(95%CI,50 - 93%)。合成数据集C和D的性能指标有所下降(各自的准确率为71%和54%)。这项初步研究突出了合成数据作为ML算法开发的一种快速手段的前景。