Princeton Neuroscience Institute & Department of Psychology, Princeton University.
Department of Psychology, Yale University.
Cogn Sci. 2022 Feb;46(2):e13085. doi: 10.1111/cogs.13085.
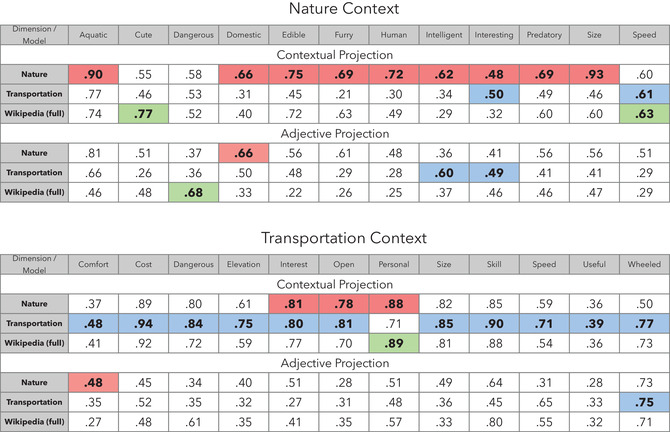
Applying machine learning algorithms to automatically infer relationships between concepts from large-scale collections of documents presents a unique opportunity to investigate at scale how human semantic knowledge is organized, how people use it to make fundamental judgments ("How similar are cats and bears?"), and how these judgments depend on the features that describe concepts (e.g., size, furriness). However, efforts to date have exhibited a substantial discrepancy between algorithm predictions and human empirical judgments. Here, we introduce a novel approach to generating embeddings for this purpose motivated by the idea that semantic context plays a critical role in human judgment. We leverage this idea by constraining the topic or domain from which documents used for generating embeddings are drawn (e.g., referring to the natural world vs. transportation apparatus). Specifically, we trained state-of-the-art machine learning algorithms using contextually-constrained text corpora (domain-specific subsets of Wikipedia articles, 50+ million words each) and showed that this procedure greatly improved predictions of empirical similarity judgments and feature ratings of contextually relevant concepts. Furthermore, we describe a novel, computationally tractable method for improving predictions of contextually-unconstrained embedding models based on dimensionality reduction of their internal representation to a small number of contextually relevant semantic features. By improving the correspondence between predictions derived automatically by machine learning methods using vast amounts of data and more limited, but direct empirical measurements of human judgments, our approach may help leverage the availability of online corpora to better understand the structure of human semantic representations and how people make judgments based on those.
应用机器学习算法从大规模文档集合中自动推断概念之间的关系,为从大规模上研究人类语义知识的组织方式、人们如何利用它做出基本判断(“猫和熊有多相似?”)以及这些判断如何依赖于描述概念的特征(例如,大小、毛茸茸)提供了独特的机会。然而,迄今为止的努力在算法预测和人类经验判断之间表现出了显著的差异。在这里,我们引入了一种新的方法来生成为此目的的嵌入,其灵感来自于语义上下文在人类判断中起着关键作用的想法。我们通过限制用于生成嵌入的文档的主题或领域(例如,指自然世界与交通设备)来利用这个想法。具体来说,我们使用上下文受限的文本语料库(每个语料库都来自维基百科文章的特定领域子集,超过 5000 万词)对最先进的机器学习算法进行了训练,并表明该过程极大地提高了对经验相似性判断和相关概念特征评级的预测。此外,我们描述了一种新颖的、计算上可行的方法,用于根据其内部表示的降维来提高上下文不受限制的嵌入模型的预测,从而将其简化为少数几个与上下文相关的语义特征。通过提高使用大量数据的机器学习方法自动推导的预测与人类判断的更有限但直接的经验测量之间的一致性,我们的方法可以帮助利用在线语料库的可用性来更好地理解人类语义表示的结构以及人们如何基于这些表示做出判断。