Department of Agricultural Sciences, University of Naples 'Federico II', Via Università 100, 80055, Portici (Naples), Italy.
Institute of Computational Biology, Department of Biotechnology, University of Natural Resources and Life Sciences, Vienna, Muthgasse 18, 1190, Vienna, Austria.
Plant J. 2022 Jun;110(6):1592-1602. doi: 10.1111/tpj.15756. Epub 2022 Apr 18.
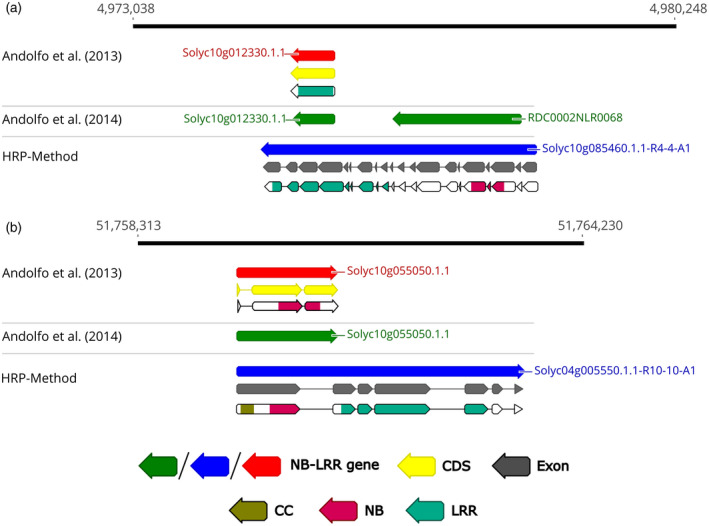
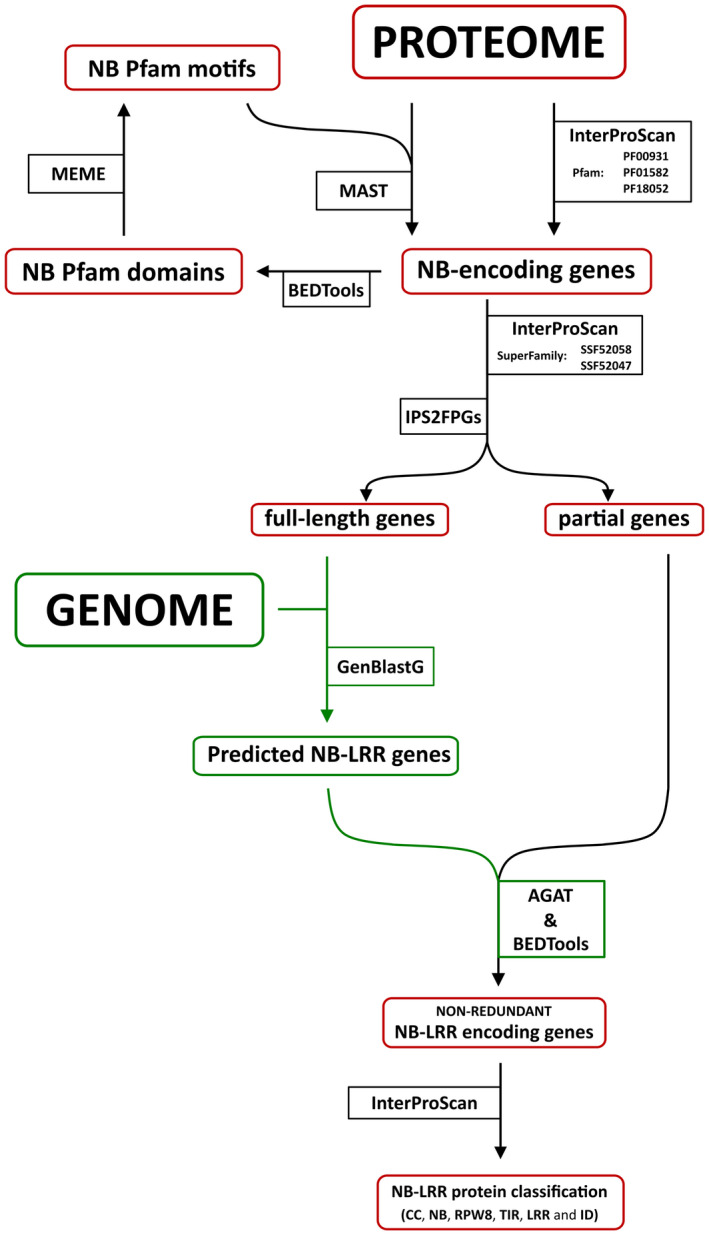
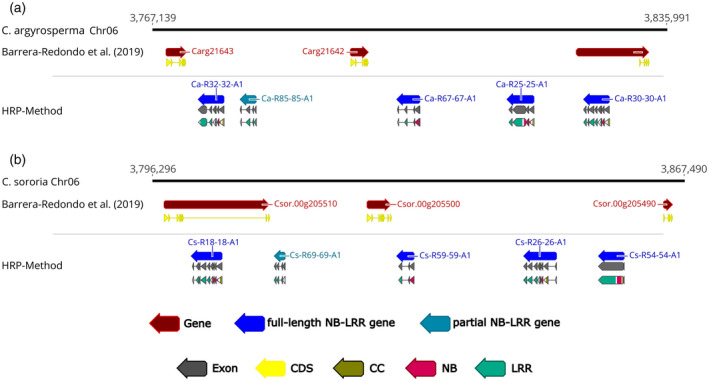
The activation of plant immunity is mediated by resistance (R)-gene receptors, also known as nucleotide-binding leucine-rich repeat (NB-LRR) genes, which in turn trigger the authentic defense response. R-gene identification is a crucial goal for both classic and modern plant breeding strategies for disease resistance. The conventional method identifies NB-LRR genes using a protein motif/domain-based search (PDS) within an automatically predicted gene set of the respective genome assembly. PDS proved to be imprecise since repeat masking prior to automatic genome annotation unwittingly prevented comprehensive NB-LRR gene detection. Furthermore, R-genes have diversified in a species-specific manner, so that NB-LRR gene identification cannot be universally standardized. Here, we present the full-length Homology-based R-gene Prediction (HRP) method for the comprehensive identification and annotation of a genome's R-gene repertoire. Our method has substantially addressed the complex genomic organization of tomato (Solanum lycopersicum) NB-LRR gene loci, proving to be more performant than the well-established RenSeq approach. HRP efficiency was also tested on three differently assembled and annotated Beta sp. genomes. Indeed, HRP identified up to 45% more full-length NB-LRR genes compared to previous approaches. HRP also turned out to be a more refined strategy for R-gene allele mining, testified by the identification of hitherto undiscovered Fom-2 homologs in five Cucurbita sp. genomes. In summary, our high-performance method for full-length NB-LRR gene discovery will propel the identification of novel R-genes towards development of improved cultivars.
植物免疫的激活是由抗性(R)基因受体介导的,这些受体也被称为核苷酸结合富含亮氨酸重复(NB-LRR)基因,它们反过来触发真正的防御反应。R 基因的鉴定是经典和现代植物抗病育种策略的重要目标。传统的方法是使用基于蛋白质基序/结构域的搜索(PDS)在相应基因组组装的自动预测基因集中识别 NB-LRR 基因。事实证明,PDS 不够精确,因为在自动基因组注释之前进行重复掩蔽会无意中阻止全面的 NB-LRR 基因检测。此外,R 基因在物种特异性方面已经多样化,因此 NB-LRR 基因的识别不能普遍标准化。在这里,我们提出了基于同源性的全长 R 基因预测(HRP)方法,用于全面鉴定和注释基因组的 R 基因库。我们的方法大大解决了番茄(Solanum lycopersicum)NB-LRR 基因座的复杂基因组组织问题,其性能明显优于成熟的 RenSeq 方法。还在三个不同组装和注释的 Beta sp.基因组上测试了 HRP 的效率。事实上,与以前的方法相比,HRP 鉴定出的全长 NB-LRR 基因多了 45%。HRP 还被证明是一种更精细的 R 基因等位基因挖掘策略,在五个 Cucurbita sp.基因组中鉴定到迄今为止未发现的 Fom-2 同源物就是证明。总之,我们用于全长 NB-LRR 基因发现的高性能方法将推动新型 R 基因的鉴定,以开发改良品种。