Laboratory of Computer Science, Massachusetts General Hospital, Boston, Massachusetts, USA.
Department of Medicine, Massachusetts General Hospital, Boston, Massachusetts, USA.
J Am Med Inform Assoc. 2022 Jul 12;29(8):1334-1341. doi: 10.1093/jamia/ocac070.
The increasing translation of artificial intelligence (AI)/machine learning (ML) models into clinical practice brings an increased risk of direct harm from modeling bias; however, bias remains incompletely measured in many medical AI applications. This article aims to provide a framework for objective evaluation of medical AI from multiple aspects, focusing on binary classification models.
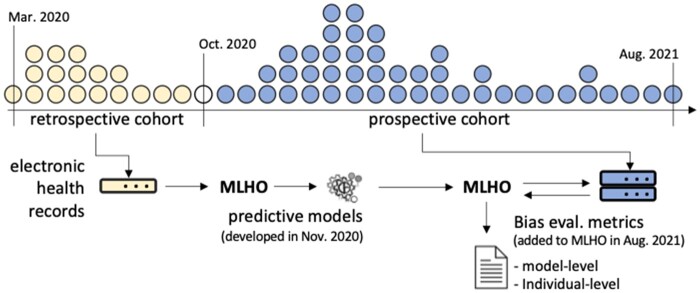
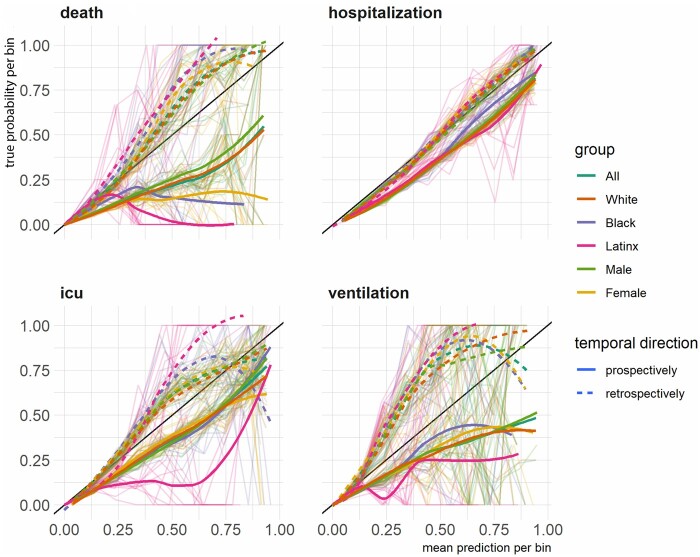
Using data from over 56 000 Mass General Brigham (MGB) patients with confirmed severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), we evaluate unrecognized bias in 4 AI models developed during the early months of the pandemic in Boston, Massachusetts that predict risks of hospital admission, ICU admission, mechanical ventilation, and death after a SARS-CoV-2 infection purely based on their pre-infection longitudinal medical records. Models were evaluated both retrospectively and prospectively using model-level metrics of discrimination, accuracy, and reliability, and a novel individual-level metric for error.
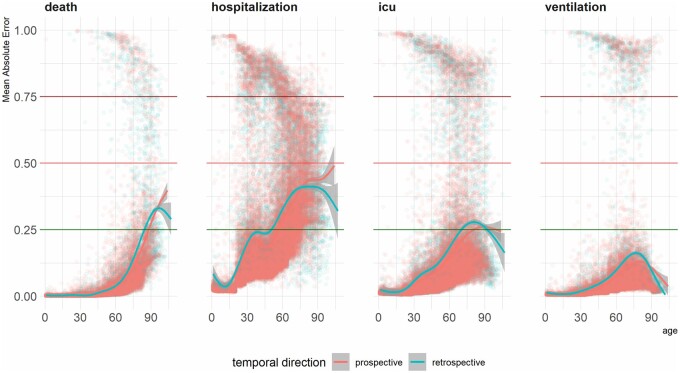
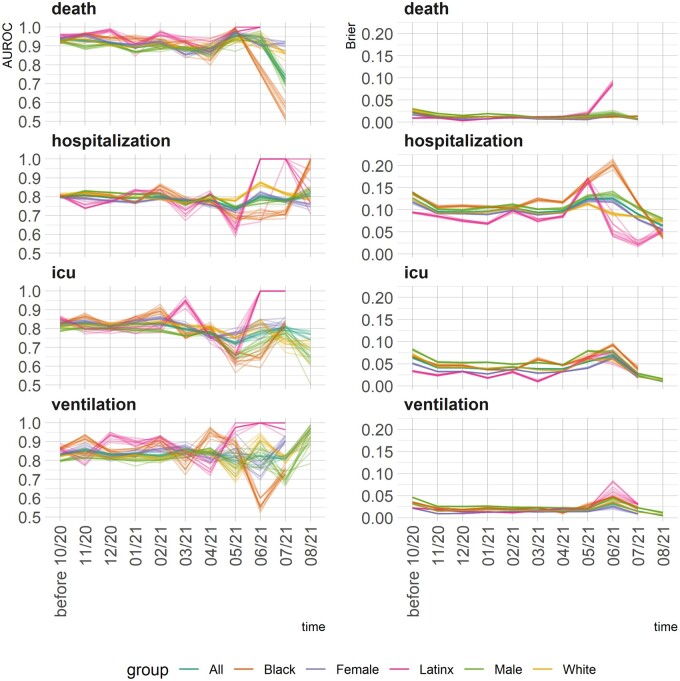
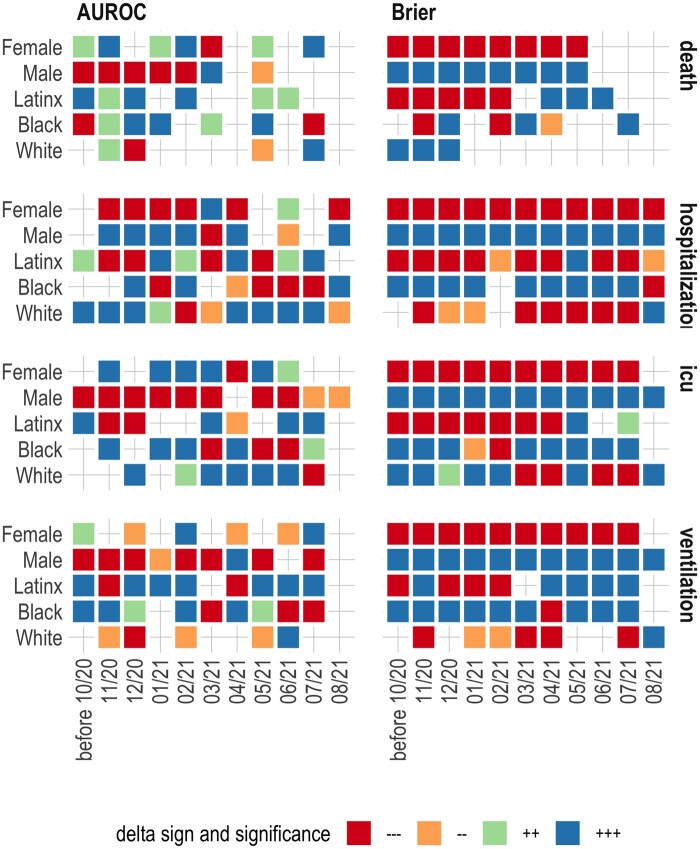
We found inconsistent instances of model-level bias in the prediction models. From an individual-level aspect, however, we found most all models performing with slightly higher error rates for older patients.
While a model can be biased against certain protected groups (ie, perform worse) in certain tasks, it can be at the same time biased towards another protected group (ie, perform better). As such, current bias evaluation studies may lack a full depiction of the variable effects of a model on its subpopulations.
Only a holistic evaluation, a diligent search for unrecognized bias, can provide enough information for an unbiased judgment of AI bias that can invigorate follow-up investigations on identifying the underlying roots of bias and ultimately make a change.
人工智能(AI)/机器学习(ML)模型在临床实践中的应用越来越多,这带来了模型偏差直接造成伤害的风险增加;然而,在许多医疗 AI 应用中,偏差仍然没有得到完全衡量。本文旨在提供一个从多个方面客观评估医疗 AI 的框架,重点关注二元分类模型。
利用来自马萨诸塞州波士顿超过 56000 名 MGB 确诊严重急性呼吸综合征冠状病毒 2(SARS-CoV-2)患者的数据,我们评估了在疫情早期开发的 4 种 AI 模型中存在的未被识别的偏差,这些模型仅基于感染 SARS-CoV-2 前的纵向医疗记录,预测感染 SARS-CoV-2 后的住院、入住 ICU、机械通气和死亡风险。使用模型水平的区分度、准确性和可靠性指标以及一种新的个体水平的误差指标,对模型进行回顾性和前瞻性评估。
我们发现预测模型中存在不一致的模型水平偏差实例。然而,从个体水平来看,我们发现大多数模型对老年患者的预测误差率略高。
虽然模型在某些任务中可能对某些受保护群体(即表现更差)存在偏差,但它同时也可能对另一个受保护群体(即表现更好)存在偏差。因此,目前的偏差评估研究可能缺乏对模型对其亚群的可变影响的全面描述。
只有全面的评估,以及对未被识别的偏差的仔细搜索,才能提供足够的信息,对 AI 偏差进行公正的判断,从而激发对识别偏差根源的后续调查,并最终做出改变。