Department of Artificial Intelligence and Knowledge Systems, Sanderring 2, 97070, Würzburg, Germany.
Interventional and Experimental Endoscopy (InExEn), Department of Internal Medicine II, University Hospital Würzburg, Oberdürrbacher Straße 6, 97080, Würzburg, Germany.
Biomed Eng Online. 2022 May 25;21(1):33. doi: 10.1186/s12938-022-01001-x.
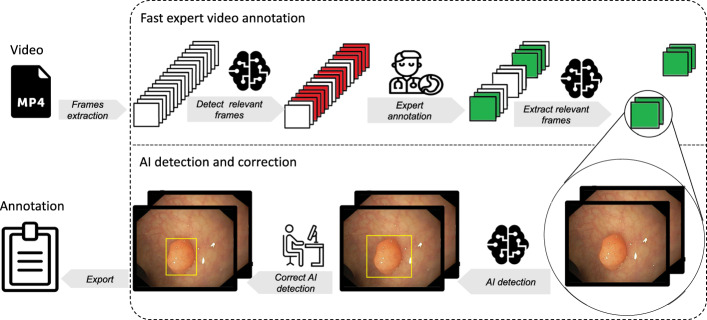
Machine learning, especially deep learning, is becoming more and more relevant in research and development in the medical domain. For all the supervised deep learning applications, data is the most critical factor in securing successful implementation and sustaining the progress of the machine learning model. Especially gastroenterological data, which often involves endoscopic videos, are cumbersome to annotate. Domain experts are needed to interpret and annotate the videos. To support those domain experts, we generated a framework. With this framework, instead of annotating every frame in the video sequence, experts are just performing key annotations at the beginning and the end of sequences with pathologies, e.g., visible polyps. Subsequently, non-expert annotators supported by machine learning add the missing annotations for the frames in-between.
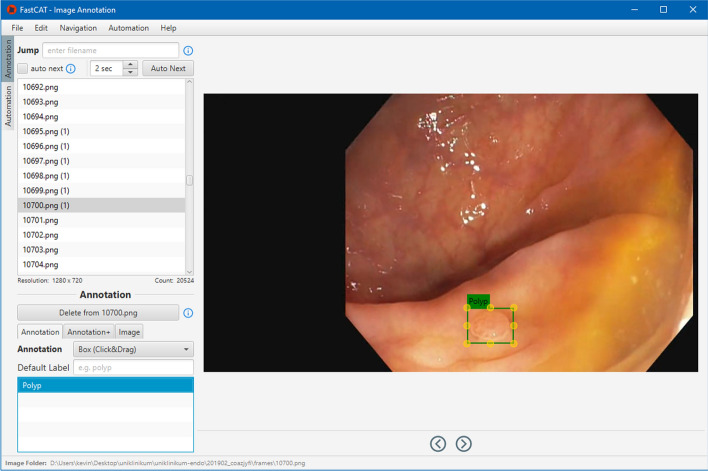
In our framework, an expert reviews the video and annotates a few video frames to verify the object's annotations for the non-expert. In a second step, a non-expert has visual confirmation of the given object and can annotate all following and preceding frames with AI assistance. After the expert has finished, relevant frames will be selected and passed on to an AI model. This information allows the AI model to detect and mark the desired object on all following and preceding frames with an annotation. Therefore, the non-expert can adjust and modify the AI predictions and export the results, which can then be used to train the AI model.
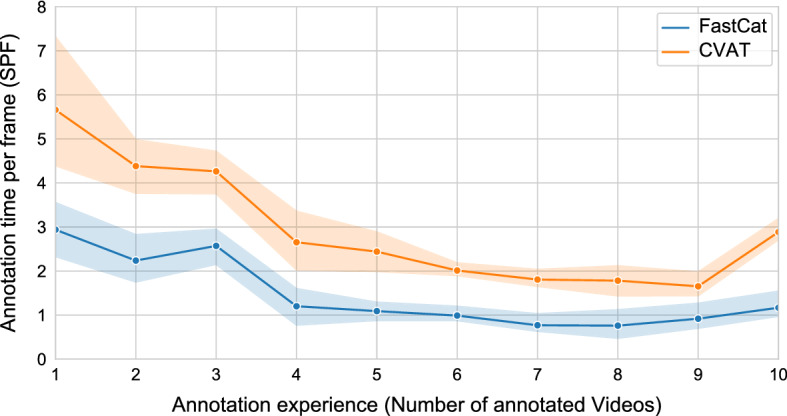
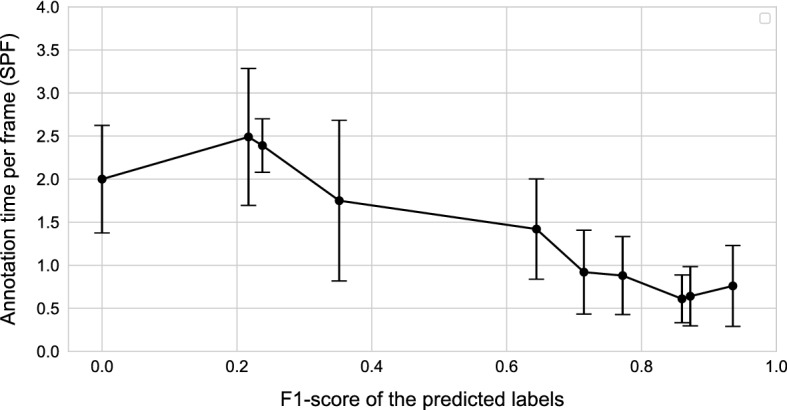
Using this framework, we were able to reduce workload of domain experts on average by a factor of 20 on our data. This is primarily due to the structure of the framework, which is designed to minimize the workload of the domain expert. Pairing this framework with a state-of-the-art semi-automated AI model enhances the annotation speed further. Through a prospective study with 10 participants, we show that semi-automated annotation using our tool doubles the annotation speed of non-expert annotators compared to a well-known state-of-the-art annotation tool.
In summary, we introduce a framework for fast expert annotation for gastroenterologists, which reduces the workload of the domain expert considerably while maintaining a very high annotation quality. The framework incorporates a semi-automated annotation system utilizing trained object detection models. The software and framework are open-source.
机器学习,尤其是深度学习,在医学领域的研究和开发中变得越来越重要。对于所有监督的深度学习应用程序来说,数据是确保成功实施和维持机器学习模型进展的最关键因素。特别是涉及内窥镜视频的胃肠病学数据,注释起来很麻烦。需要领域专家来解释和注释这些视频。为了支持这些领域专家,我们生成了一个框架。有了这个框架,专家不需要注释视频序列中的每一帧,而只需在有病理的序列的开头和结尾处进行关键注释,例如可见息肉。然后,由机器学习支持的非专家注释器添加序列中间帧的缺失注释。
在我们的框架中,专家审查视频并注释一些视频帧,以验证非专家的对象注释。在第二步中,非专家通过视觉确认给定的对象,并可以在 AI 辅助下注释所有后续和前面的帧。专家完成后,将选择相关帧并传递给 AI 模型。这些信息允许 AI 模型在所有后续和前面的帧上用注释检测和标记所需的对象。因此,非专家可以调整和修改 AI 预测并导出结果,然后可以将结果用于训练 AI 模型。
使用这个框架,我们能够在我们的数据上将领域专家的工作量平均减少 20 倍。这主要是由于框架的结构旨在最小化领域专家的工作量。将这个框架与最先进的半自动 AI 模型结合使用,可以进一步提高注释速度。通过一项有 10 名参与者的前瞻性研究,我们表明,与著名的最先进的注释工具相比,使用我们的工具进行半自动注释可以将非专家注释器的注释速度提高一倍。
总之,我们为胃肠病学家引入了一种快速专家注释框架,该框架大大减少了领域专家的工作量,同时保持了非常高的注释质量。该框架包含一个利用训练有素的对象检测模型的半自动注释系统。该软件和框架是开源的。