Department of Medicine, School of Medicine and Public Health, University of Wisconsin, Madison, WI, USA.
Department of Psychiatry and Behavioral Sciences, Rush University Medical Center, Chicago, IL, USA.
Lancet Digit Health. 2022 Jun;4(6):e426-e435. doi: 10.1016/S2589-7500(22)00041-3.
Substance misuse is a heterogeneous and complex set of behavioural conditions that are highly prevalent in hospital settings and frequently co-occur. Few hospital-wide solutions exist to comprehensively and reliably identify these conditions to prioritise care and guide treatment. The aim of this study was to apply natural language processing (NLP) to clinical notes collected in the electronic health record (EHR) to accurately screen for substance misuse.
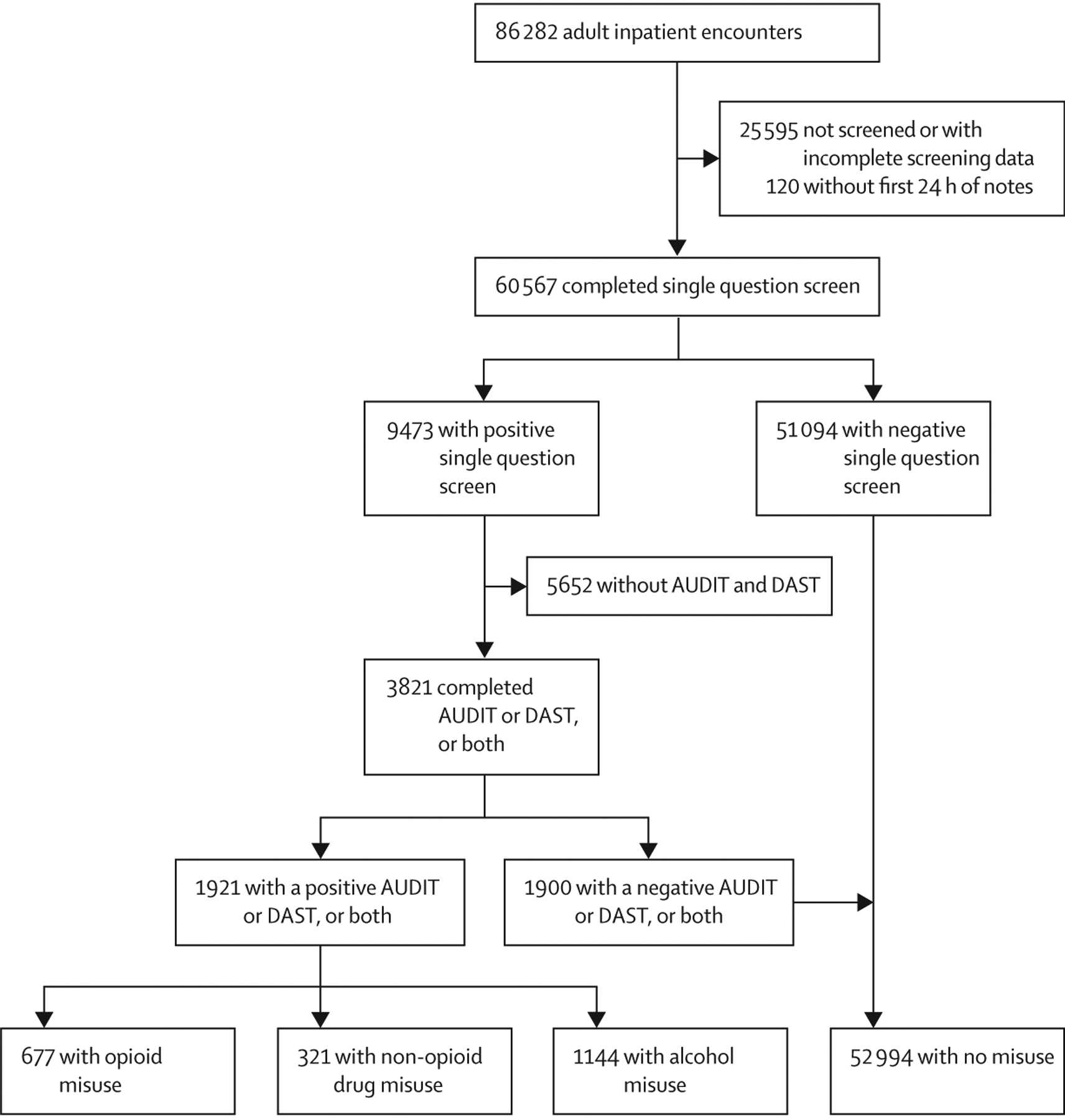
The model was trained and developed on a reference dataset derived from a hospital-wide programme at Rush University Medical Center (RUMC), Chicago, IL, USA, that used structured diagnostic interviews to manually screen admitted patients over 27 months (between Oct 1, 2017, and Dec 31, 2019; n=54 915). The Alcohol Use Disorder Identification Test and Drug Abuse Screening Tool served as reference standards. The first 24 h of notes in the EHR were mapped to standardised medical vocabulary and fed into single-label, multilabel, and multilabel with auxillary-task neural network models. Temporal validation of the model was done using data from the subsequent 12 months on a subset of RUMC patients (n=16 917). External validation was done using data from Loyola University Medical Center, Chicago, IL, USA between Jan 1, 2007, and Sept 30, 2017 (n=1991 adult patients). The primary outcome was discrimination for alcohol misuse, opioid misuse, or non-opioid drug misuse. Discrimination was assessed by the area under the receiver operating characteristic curve (AUROC). Calibration slope and intercept were measured with the unreliability index. Bias assessments were performed across demographic subgroups.
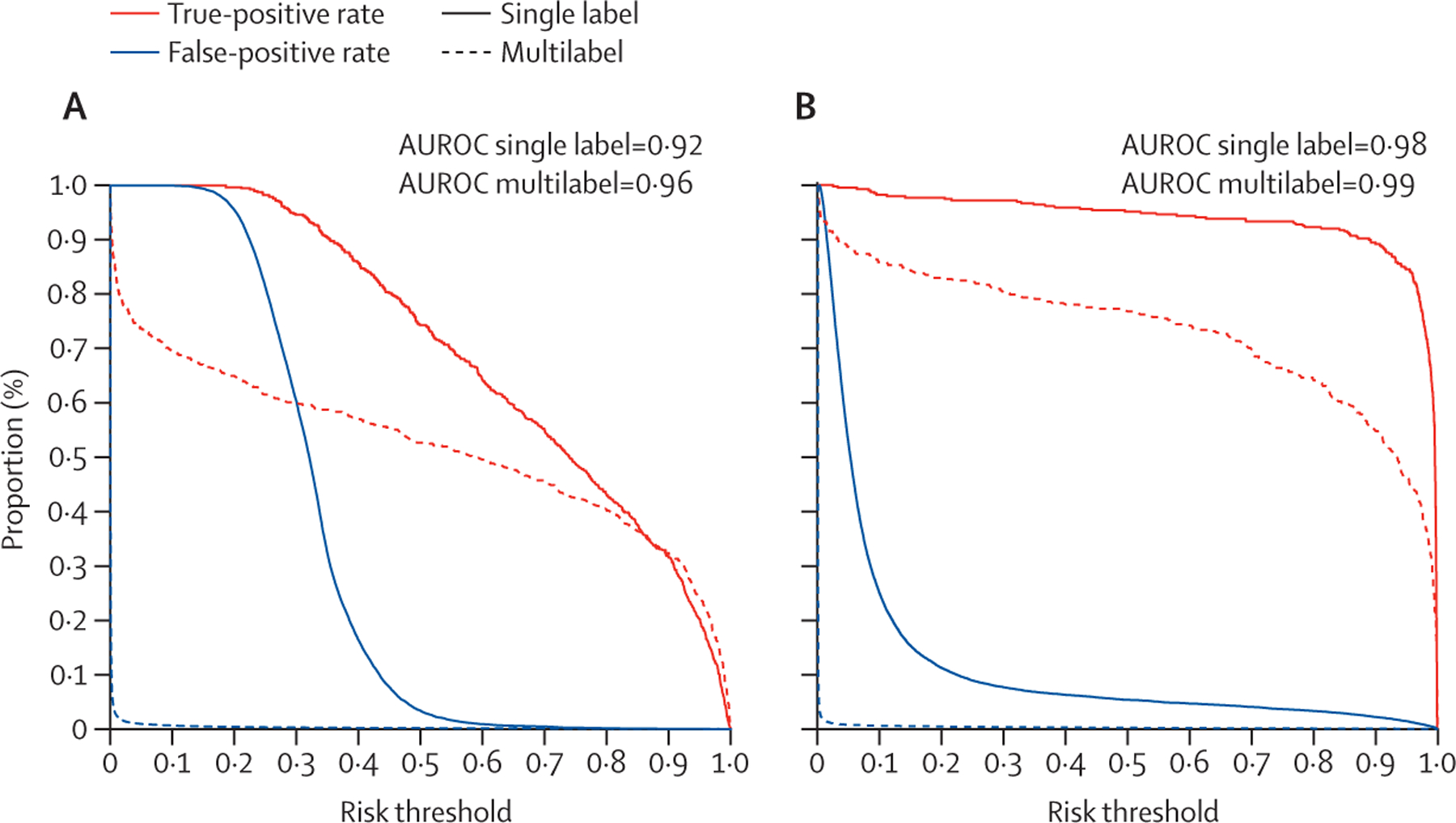
The model was trained on a cohort that had 3·5% misuse (n=1 921) with any type of substance. 220 (11%) of 1921 patients with substance misuse had more than one type of misuse. The multilabel convolutional neural network classifier had a mean AUROC of 0·97 (95% CI 0·96-0·98) during temporal validation for all types of substance misuse. The model was well calibrated and showed good face validity with model features containing explicit mentions of aberrant drug-taking behaviour. A false-negative rate of 0·18-0·19 and a false-positive rate of 0·03 between non-Hispanic Black and non-Hispanic White groups occurred. In external validation, the AUROCs for alcohol and opioid misuse were 0·88 (95% CI 0·86-0·90) and 0·94 (0·92-0·95), respectively.
We developed a novel and accurate approach to leveraging the first 24 h of EHR notes for screening multiple types of substance misuse.
National Institute On Drug Abuse, National Institutes of Health.
物质滥用是一组具有异质性和复杂性的行为状况,在医院环境中非常普遍,且经常同时发生。几乎没有全院范围内的解决方案可以全面、可靠地识别这些情况,以确定护理优先级并指导治疗。本研究旨在应用自然语言处理(NLP)技术从电子健康记录(EHR)中收集的临床记录中准确筛选物质滥用。
该模型是在芝加哥拉什大学医学中心(RUMC)的一项全院范围内的计划参考数据集上进行训练和开发的,该计划使用结构化诊断访谈在 27 个月内(2017 年 10 月 1 日至 2019 年 12 月 31 日)对入院患者进行手动筛查;n=54915)。酒精使用障碍识别测试和药物滥用筛查工具作为参考标准。EHR 中的前 24 小时记录被映射到标准化医学词汇中,并输入到单标签、多标签和多标签辅助任务神经网络模型中。该模型的时间验证使用 RUMC 患者的后续 12 个月(n=16917)中的数据进行。外部验证使用 2007 年 1 月 1 日至 2017 年 9 月 30 日期间芝加哥洛约拉大学医学中心(Loyola University Medical Center)的数据(n=1991 名成年患者)进行。主要结局是酒精滥用、阿片类药物滥用或非阿片类药物滥用的鉴别。通过接受者操作特征曲线(ROC)下的面积(AUROC)来评估鉴别能力。使用不可靠性指数测量校准斜率和截距。在人口统计学亚组中进行了偏差评估。
该模型在一个有 3.5%(n=1921)物质滥用的队列上进行了训练,其中任何类型的物质滥用都有 1%。1921 名物质滥用患者中有 220 名(11%)有多发性滥用。多标签卷积神经网络分类器在所有类型物质滥用的时间验证中平均 AUROC 为 0.97(95%CI 0.96-0.98)。该模型具有良好的校准能力,并且具有良好的表面有效性,其模型特征包含对异常药物使用行为的明确提及。非西班牙裔黑人组和非西班牙裔白人组的假阴性率分别为 0.18-0.19,假阳性率为 0.03。在外部验证中,酒精和阿片类药物滥用的 AUROCs 分别为 0.88(95%CI 0.86-0.90)和 0.94(0.92-0.95)。
我们开发了一种新颖而准确的方法,利用 EHR 记录的前 24 小时记录来筛查多种类型的物质滥用。
国家药物滥用研究所,美国国立卫生研究院。